The problem
Most business systems have a layer of authored rules that handle the long tail of decisions the application cannot decide for itself. "If vendor X and category Y, route to approver Z." "If amount > €5,000 and project = construction, require CFO sign-off." Authored rules are auditable and well-understood, but they have a discoverability problem: someone has to know that the rule should exist before they can write it.
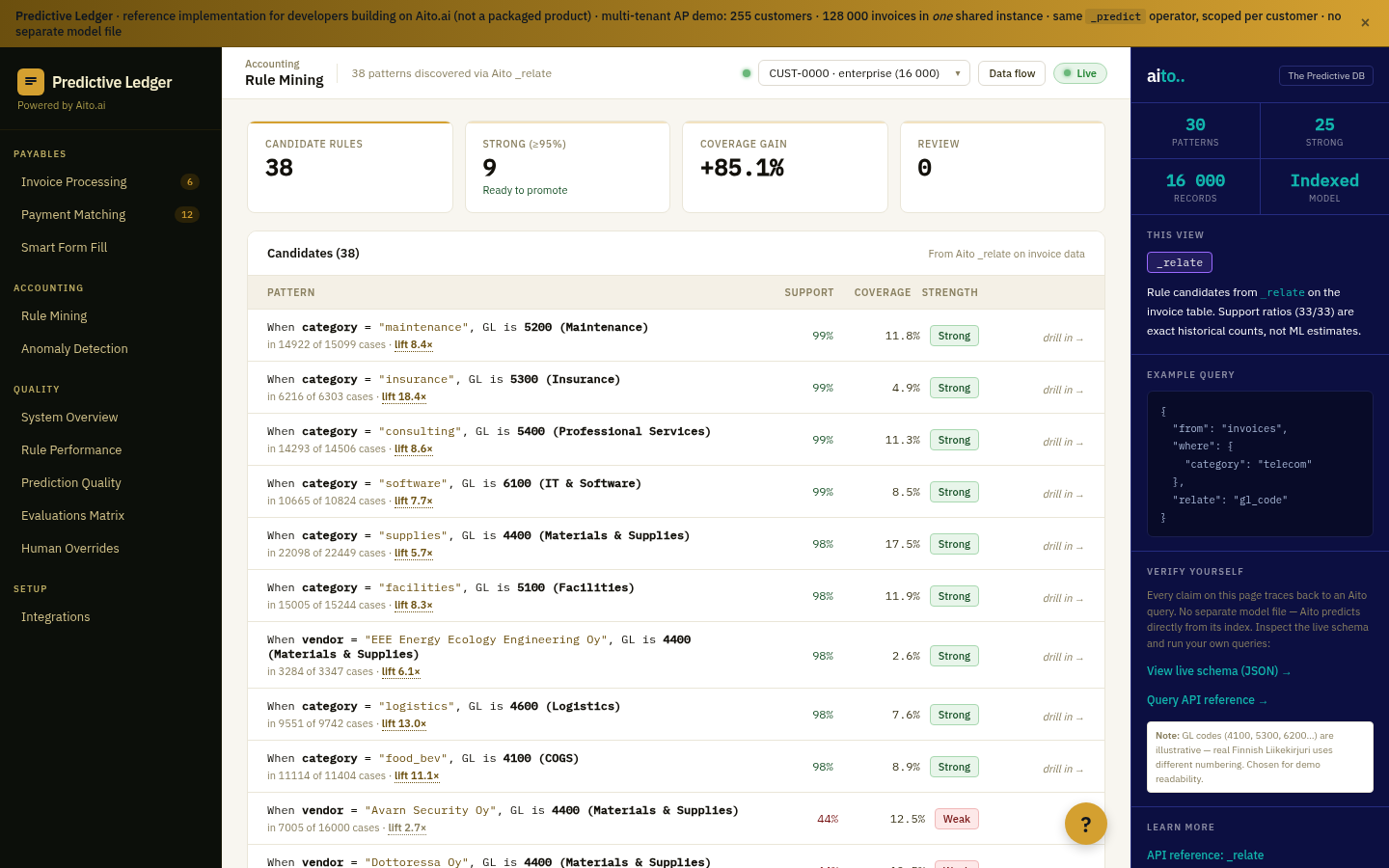
The patterns the rules should encode are already in the data. Vendor X plus category Y has routed to approver Z 47 times out of the last 50 occurrences — that is a statistically significant pattern with 94% support. Nobody has written it as a rule yet, but the system could surface it as a candidate. Once surfaced, the team can promote it to a rule, ignore it, or override the source data — each path documented with an audit trail.
Rule mining solves the discoverability problem. The system finds the patterns hiding in the operational data and presents them for human review.
How it works
Aito's _relate operator returns conditional probabilities between any two attributes — and crucially, ranks them by lift. Lift is the ratio of conditional probability to base probability; a lift of 15.8× means the pattern is 15.8 times more likely than chance. Patterns with lift below ~3× are noise; patterns above ~5× are usually worth a look; patterns above ~10× are very likely real and stable.
The rule-mining view runs _relate across the operational data with support and lift filters, presenting the top candidates ranked by significance. Each candidate becomes a row with the conditional pattern, the lift, the support (how many cases over what time window), and three buttons: promote-to-rule, dismiss, or override-source-data. Promoting writes the rule with an audit trail; dismissing records the decision so the same candidate does not resurface; overriding flags the source data for review.
{
"from": "invoices",
"relate": ["category", "gl_code"],
"with": "approver",
"select": ["$lift", "$p", "$support"],
"where": { "$lift": { "$gte": 5 } },
"limit": 20
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🧾 Accounting demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How is this different from association rule mining (Apriori, FP-growth)?
Same conceptual family — find statistically significant patterns in transaction data. The difference is that classical algorithms run in batch, produce a frozen rule set, and need to be re-run when data changes. _relate runs at query time over the live index, so the candidate list reflects the current state of the data on every refresh.
Will this surface a lot of patterns that are too specific to be useful?
That is what the lift threshold handles. At lift > 5× and support > 20 cases, the candidates are stable enough to be worth a human review. Lower thresholds produce more noise; higher thresholds miss real patterns. Mature deployments tune the thresholds per domain.
What happens to existing rules when the data shifts and the pattern weakens?
The mining view shows pattern strength over time. When a previously-strong pattern drops below the threshold, it surfaces in a "review existing rules" filter — the audit trail makes it explicit that the rule was added on supporting data that has since weakened.
Can dismissed candidates resurface later?
Dismissed candidates are recorded with a dismissal reason and do not resurface for the same combination. If the support or lift increases substantially (e.g., 2× the original level), the candidate appears in a "previously dismissed, now stronger" review queue.
Does this work outside accounting and ERP?
Yes. The pattern is "find statistically significant relationships between attributes in operational data" — applicable to support ticket routing, e-commerce product co-occurrence, customer-segment behavior, anywhere conditional patterns matter. The threshold tuning differs per domain but the mechanism is the same.