The problem
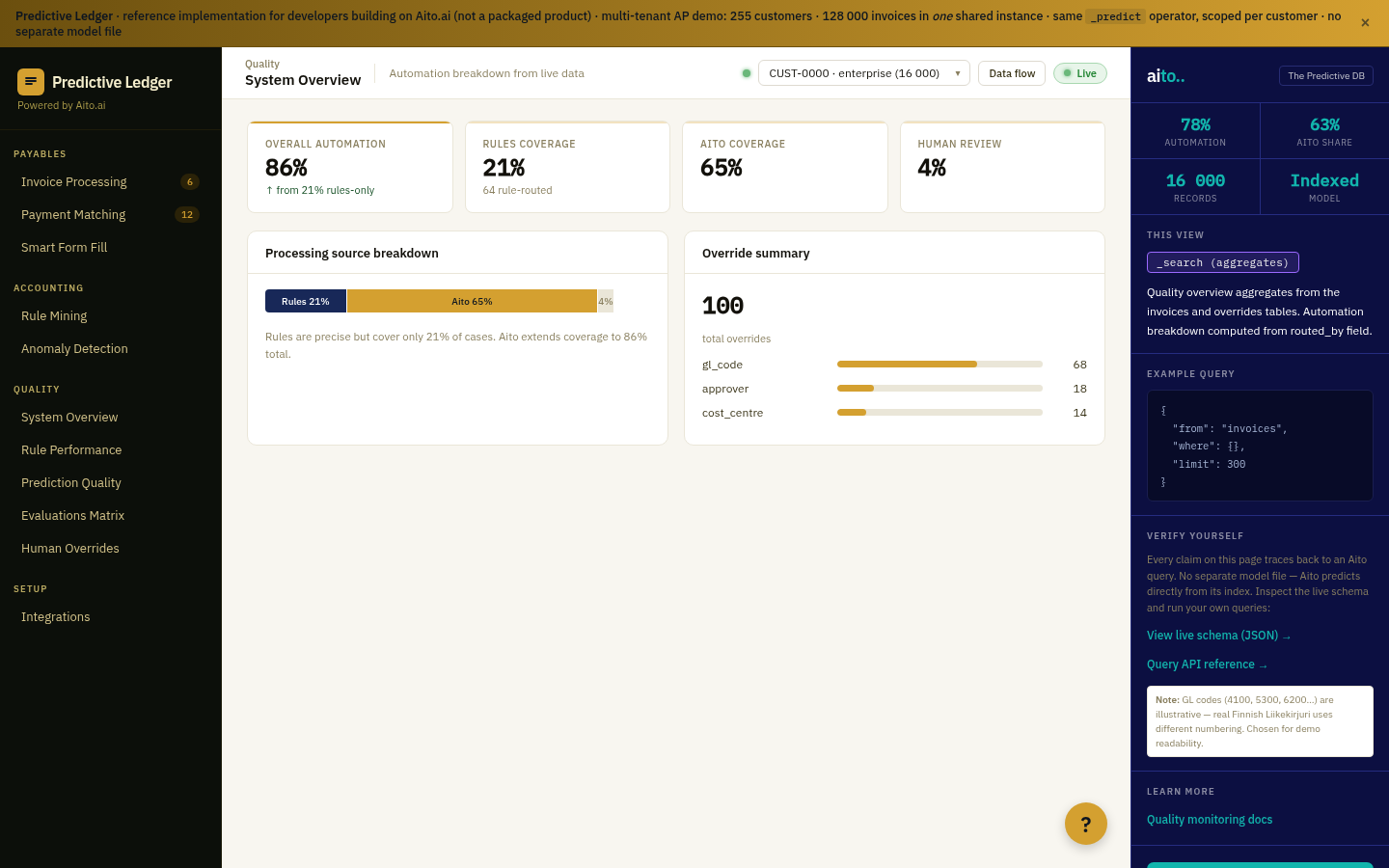
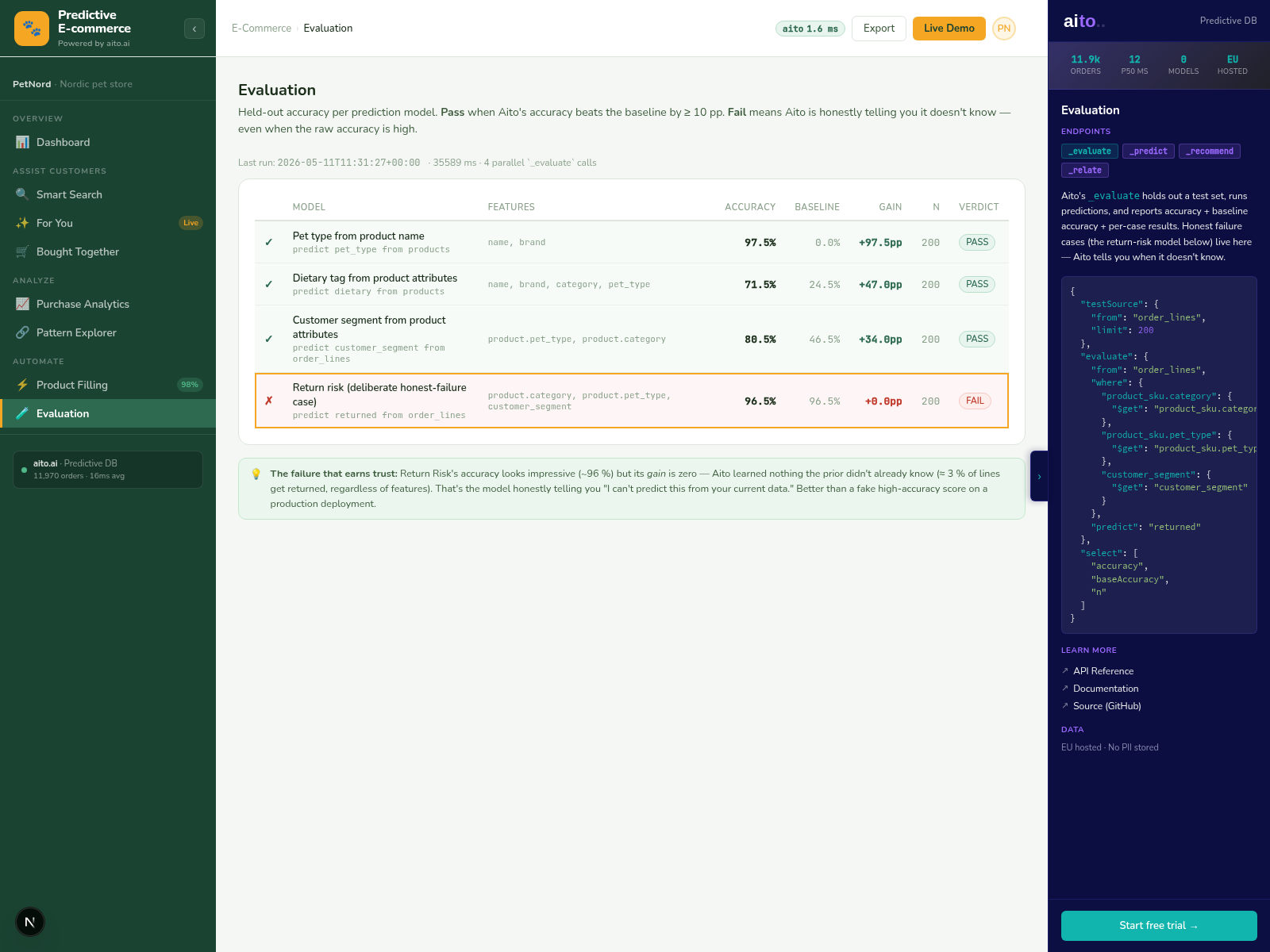
Most ML systems are evaluated as "what's the overall accuracy?" — a single headline number that hides what the system can and cannot do. For business automation, the headline accuracy is the wrong question. The right question is per-confidence-tier accuracy: at >95% confidence, what is the error rate? At 50-90%? Below 50%? The tiered answer is what makes confidence-based automation safe; the headline number is what makes it dangerous.
The honest-evaluation pattern says: every prediction returns a calibrated confidence, AND the system regularly scores those confidences against ground truth. If 95% confidence corresponds to 95% realized accuracy, the calibration is honest. If 95% confidence corresponds to 70% realized accuracy, the calibration is broken and the system is unsafe to automate on. Most ML pipelines never compute this; they report headline accuracy and call it done.
How it works
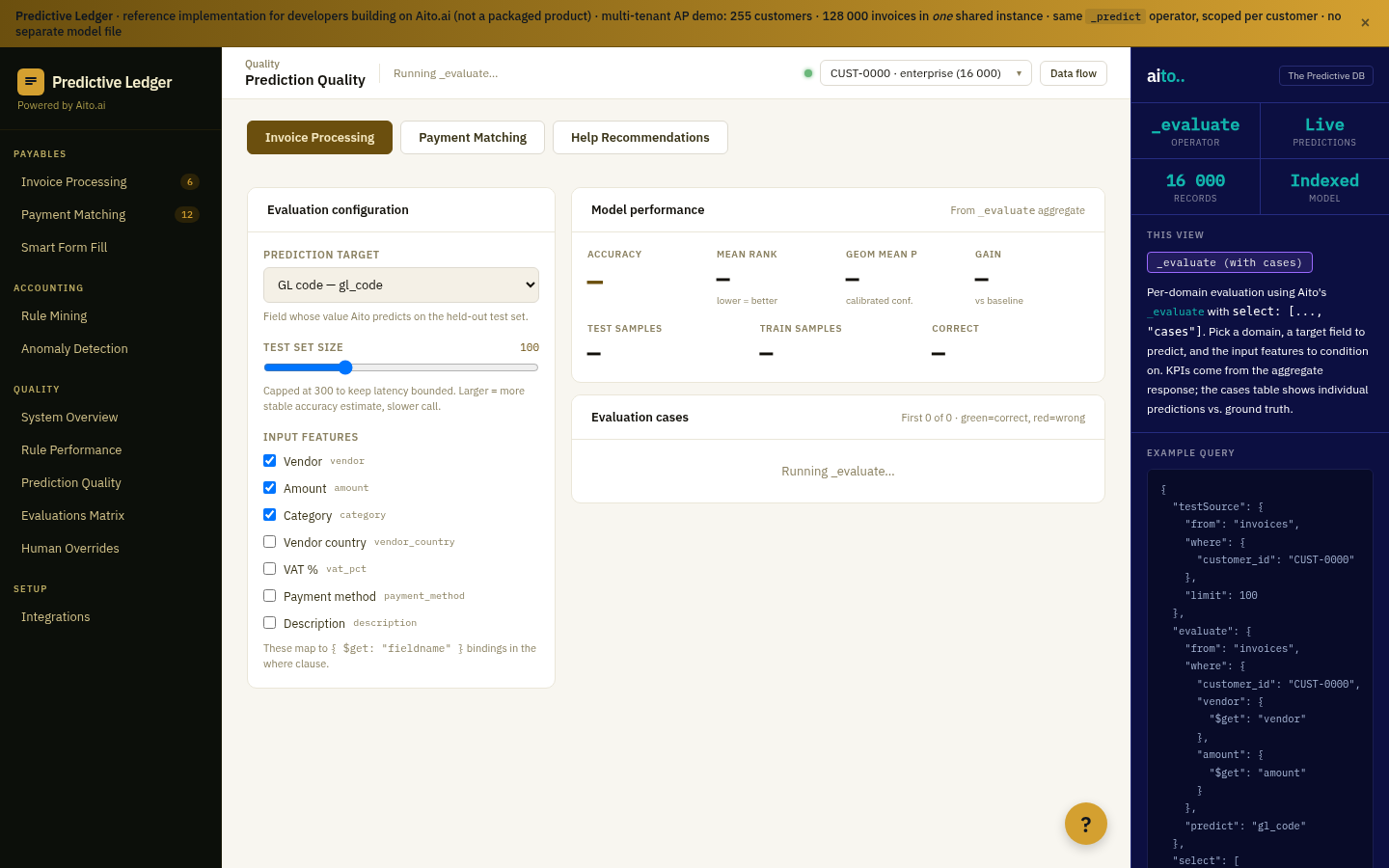
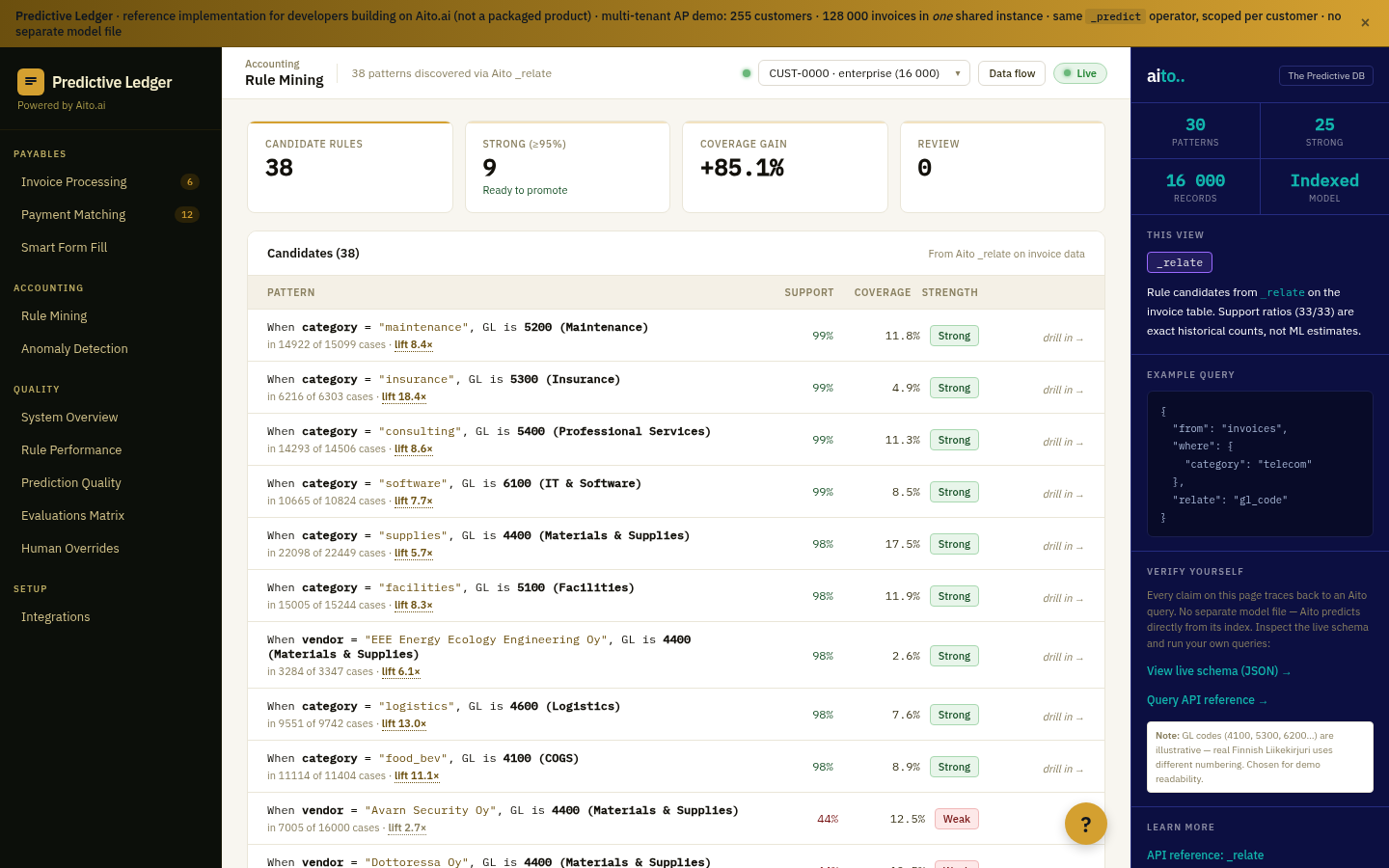
Aito's _evaluate operator runs the predictive operators (_predict, _recommend, _estimate) against a held-out slice of the data and returns the same calibration metrics the production system uses. Per-field accuracy. Per-confidence-bucket realized error. ECE (Expected Calibration Error) at the column level. Green/red diff vs. an always-predict-majority baseline so the team can see at a glance whether the prediction is actually better than guessing the most common value.
The honest-failure pattern is the load-bearing one: when _evaluate shows that a prediction yields +0.0 pp gain over baseline (the Return Risk view in the e-commerce demo), the system renders the row red and the application knows not to auto-process based on that prediction. The system saying "I cannot help here" is exactly what makes the predictions on adjacent fields safe.
{
"from": "order_lines",
"evaluate": "returned",
"where": { "product_sku.category": ["dog-dryfood", "dog-dentaltreats"] },
"select": ["$baseline_accuracy", "$accuracy", "$gain_pp", "$ece"]
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
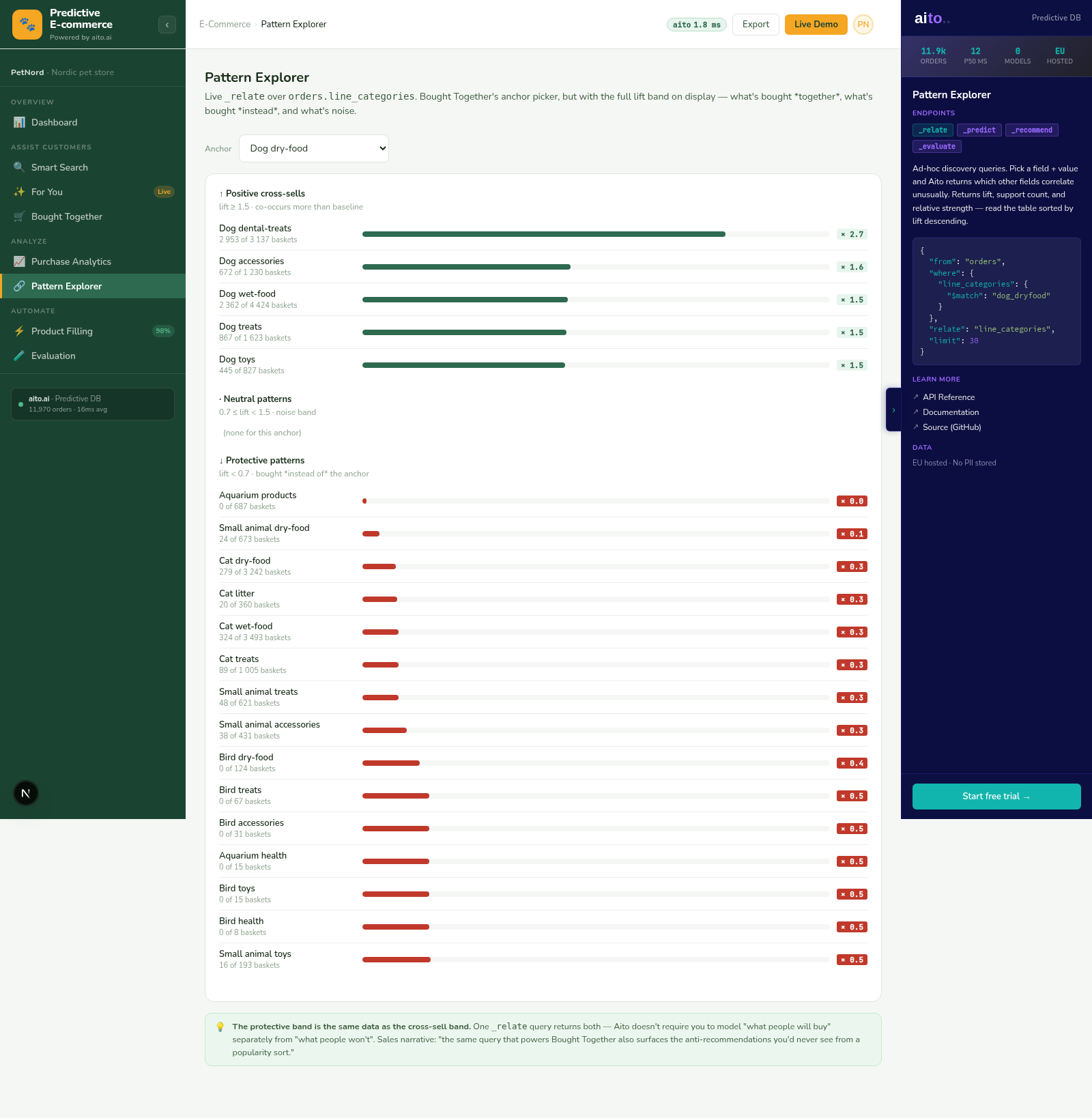
This use case runs in the 🛒 E-commerce demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to standard ML evaluation (precision, recall, F1)?
Standard metrics tell you what fraction of predictions were correct. They do not tell you whether you can trust each prediction individually. For business automation, "this prediction is 95% confident" needs to mean "actually 95% accurate at that confidence level" — that is calibration, and it is typically not part of standard ML evaluation. _evaluate reports both: standard accuracy AND calibration. The two answer different questions.
Why is calibration the metric that matters for automation?
Confidence-tiered automation says "above 95%, auto-process; below 50%, manual." If the 95% confidence is actually 70% accurate, you are auto-processing wrong predictions and the error rate looks fine because the headline number averages high and low. The user sees: "system says 95%, it must be safe." It is not. Calibrated confidence is what makes the tiering work.
What happens when _evaluate finds a prediction that performs worse than baseline?
The application surfaces it as a failed prediction — red row in the dashboard, +0.0 pp gain or worse. The application then knows not to auto-process based on that prediction. This is the honest-failure pattern: the system actively reports where it cannot help, rather than silently failing.
Can the system show calibration over time, not just at one snapshot?
Yes — that is calibration monitoring. Run _evaluate on rolling windows (last 7 days, last 30 days, last quarter). Track ECE per window. When calibration drifts (model behavior changes faster than data accumulation can compensate), the system surfaces a "calibration drift detected" signal and the team can adjust thresholds before the auto-process tier starts producing errors.
Is this just naive Bayes calibration, or something more sophisticated?
The underlying inference is Bayesian over the columnar index, not naive Bayes specifically — feature selection and posterior calculation happen per query. Calibration emerges naturally from the Bayesian update because the posterior is the probability given the evidence, not a sampled score from a discriminative model. This is part of why predictive databases tend to be well-calibrated by default; the architecture produces calibrated outputs without needing Platt scaling or isotonic regression layered on top.