Introducing the Predictive Application
Antti Rauhala
CEO and founder
May 23, 2026 • 9 min read
Software has always treated the user as the inference engine. That assumption is now optional.
The user is the processor
Every application ever built has rested on the same architectural assumption. The data lives in the software. The decisions live in the user, in every form field, every routing choice, every approval, every category. The software presents. The user thinks.
Step back from any single product and the scale of this becomes visible. Hundreds of millions of professionals spend most of their working hours making decisions that are repetitive, pattern-following, and in most cases already determined by the data sitting in the system that asks the question. This is more than a UX inconvenience. It is a civilization-scale allocation of human cognitive effort to tasks the system could resolve on its own.
The assumption held because there was no real alternative. Something has changed.
Why developers ration prediction
Every machine learning prediction has a cost: the data pipeline, the model, the training set, the monitoring, the retraining schedule, the on-call rotation when the metrics drift. The cost per prediction is high enough that the rational response is to cherry-pick. Find the two or three use cases where the ROI is unambiguous, build those, and leave everything else manual.
This is not a failure of imagination. It is correct engineering judgement given the economics.
The outcome is specific: patchwork applications, intelligent in spots, manual everywhere else. The user gets partial relief but most of the cognitive load remains. NPS moves slightly. Churn does not change. The smart-feature roadmap becomes a backlog that competes with everything else and loses.
The ceiling is economic, not technical. It applies to every application built under the assumption that prediction is expensive.
What happens when the assumption breaks?
When the cost collapses
Imagine the marginal cost of the tenth prediction equals the cost of the first. The thousandth equals the tenth. Developers stop rationing. Every field becomes a candidate, along with every routing choice, every categorization, every approval. The question shifts from where prediction earns its place to where it does not.
This is a logical consequence, not yet a claim about a specific technology. If prediction is cheap enough to apply everywhere, the whole category of decisions users make inside software becomes reclaimable.

Why does prediction matter most where complexity is highest?
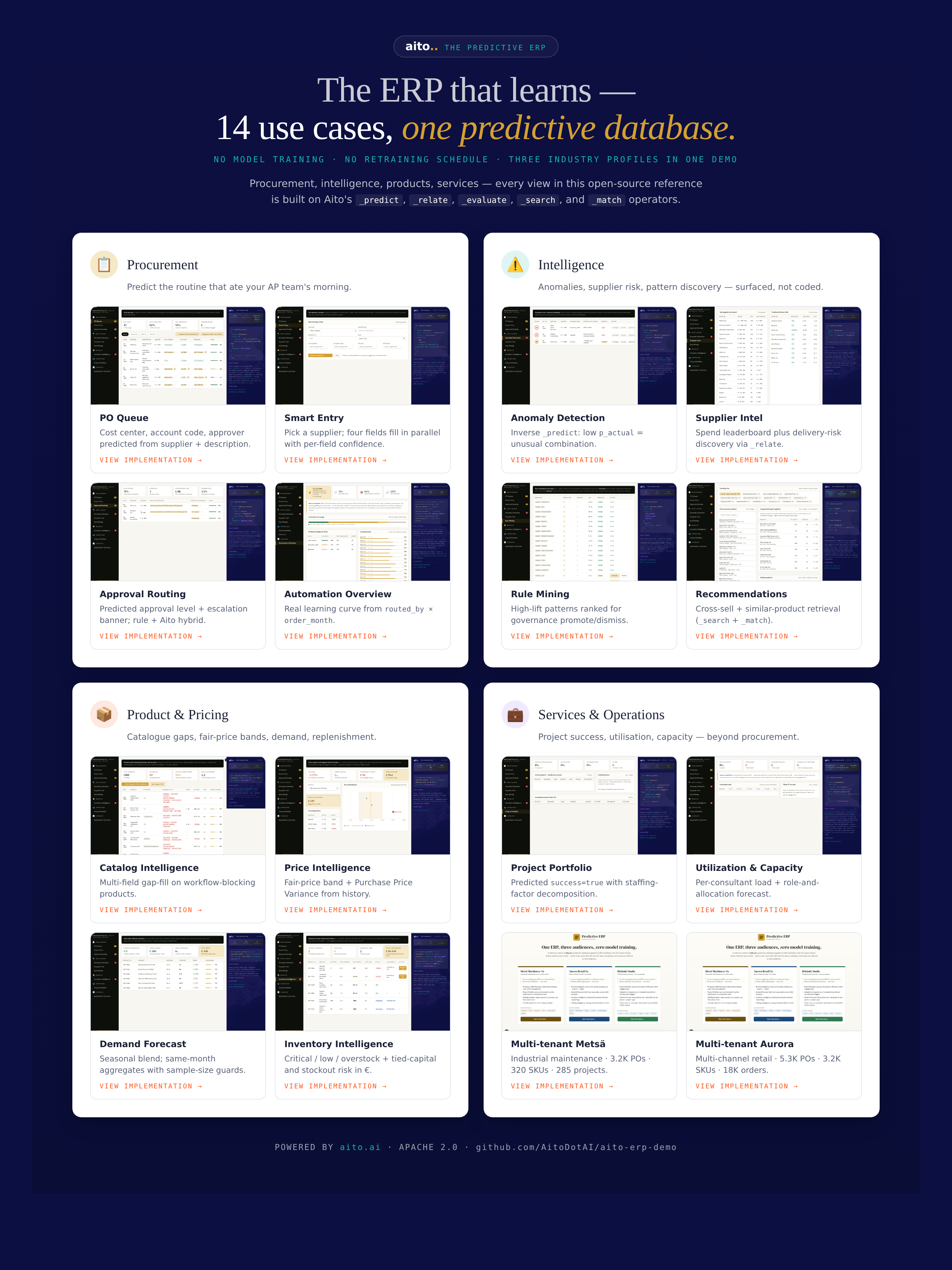
ERP is the extreme case: maximum field density, maximum decision variety per transaction, maximum cost when the user gets it wrong. Account codes, cost centers, approvers, project allocations, VAT, payment terms, supplier accounts. Every purchase order is a small exam.
If prediction works here, it works anywhere.
erp.aito.ai runs three industry profiles in one codebase: industrial maintenance, multi-channel retail, professional services. Each profile has its own database, its own data shape, its own personas. Each runs the same predictive operators. The aggregate automation rate across the mixed profile sits at 72%.
That number is specific because it is real. A marketing team would have written 90%.
Open the demo now, not after you finish reading.
What the demo reveals is that everything is automated, not just some fields.
Can you trust prediction when mistakes have financial consequences?

Accounting raises the objection before it gets asked. Finance is not a domain for blind automation. Misclassified transactions show up in tax filings. Misrouted approvals create regulatory exposure. Errors here carry real cost. The concern is correct.
Prediction in accounting is conservative and auditable. Every prediction returns a calibrated probability. Above 95%, auto-process. Between 50% and 90%, pre-fill and route to review. Below 50%, leave the field empty. The user stays in control. The system says honestly when it does not know.
Applied to every transaction, every invoice, every routing decision, this kind of assistance collapses effort.
Open accounting.aito.ai.
The prediction does not feel like AI. It feels like the application finally knowing what you were going to do anyway.
What does this look like when the volume is massive?

E-commerce operates at a different scale, with millions of interactions per day. Each one is a candidate for prediction: search ranking, cross-sell, catalog enrichment, personalization. They all run from the same data, with no separate models and no retraining schedule.
ecommerce.aito.ai runs the PetNord pet-store reference. 110K rows. 16 production-ready views on a single Aito instance.
Two things deserve attention. First, the Bought Together view shows dog dry-food cross-selling to dental treats at 2.72× baseline lift. That number is not a curated rule. It came out of the data. Second, the Evaluation view contains a deliberate honest failure. Return Risk prediction yields zero improvement over baseline, and the demo shows it as a red row, not buried or hidden. A system that tells you when it cannot help is a system you can trust.
Across three domains with very different data structures, the architectural pattern is the same.
Prediction is infrastructure
Every serious application has search. Not because search is a differentiating feature. Because its absence is a deficiency. Nobody builds their own search engine. Teams use infrastructure that makes search cheap and reliable, and they apply it everywhere a search box belongs.
Predictive functionality is on the same trajectory. It will become a baseline capability that users come to expect, and whose absence will feel, increasingly, like something is broken.
The analogy has a limit. Search retrieves. Prediction decides. The stakes per interaction are higher and the value per interaction is larger.
The question is not whether the application needs this. It is whether the team builds it themselves.
LLMs raise the bar. They don't replace the UI.
LLMs are genuinely powerful for open-ended tasks: writing, exploration, synthesis, unstructured problems where the shape of the answer is unknown until the answer arrives.
But most enterprise software usage is structured, repetitive, pattern-following: invoice processing, order routing, product categorization, GL code assignment. These are decision tasks with histories, not exploration tasks. The pattern lives in the data already.
LLMs applied to those tasks are expensive, brittle, and wrong-shaped for the problem. Prediction is the right tool. The two are complements.
LLMs handle the exception. Prediction handles the rule.
The Predictive Application
Software has been getting smarter for thirty years. Databases got faster, search got better, interfaces got cleaner. One thing did not change: the user remained the inference engine. Every decision, every categorization, every routing choice was still human.
The assumption held because prediction was expensive. It no longer is.
The applications that retire the assumption first will not just be better. They will make everything built under the old assumption feel broken. The way manual search felt broken after Google. The way static recommendations felt broken after Netflix.
This is what a Predictive Application is: an application designed around the premise that the user should never make a decision the data has already made for them.
What would your application look like if prediction was free?
Three predictive applications are live today. Pick the closest fit.
Building accounting SaaS? See Predictive Accounting. Same operators behind Nordic enterprise AP automation at 95%+ accuracy since 2018. 255-tenant reference at accounting.aito.ai.
Building e-commerce or commerce SaaS? See Predictive E-commerce. 16 production-ready views on the PetNord pet-store dataset, including a deliberately honest failure case.
Building ERP or operations SaaS? See Predictive ERP. PO routing, smart entry, anomaly detection, demand forecast, on one substrate.
Want to see the full surface? See the use case catalog. 39 predictive operations across verticals, organized as Analyze, Assist, Automate.
Or if you are ready to talk, email me directly: antti@aito.ai. I am the founder. Plain email works.
The questions worth asking
Is the prediction accurate enough to matter? It depends on data density. Accounting and ERP have rich transactional histories, which are strong conditions for prediction. The accuracy numbers in the demos are observable, not claimed. Open the Evaluation views and read them.
Is this production-ready? Fennoa, Q-Automate, and Lastbot run on Aito in production today. Not pilots. Paying customers, processing real transactions on real data.
How long does integration take? The demos were built in weeks. The API is HTTP and JSON. See the documentation.
The demos are live and the engine is real. Test it rather than taking anyone's word for it.
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429







