Predictive ERP Solutions

Predictive ERP on Aito
Turn Your ERP into a Predictive Application
A predictive application is an operational SaaS where the data layer doesn't just store transactions — it predicts the next one. Predictive ERP means purchase orders that route themselves, smart-entry forms where four fields fill in from one supplier pick, anomaly detection that flags miscoded accounts before posting, and demand forecasts that drive replenishment without a separate model.
Aito is the predictive database underneath. Every prediction comes back with a probability, top-3 alternatives, and a $why factor decomposition. No retraining, no MLOps, no separate ML pipeline alongside your ERP transaction tables.
Live Reference: erp.aito.ai
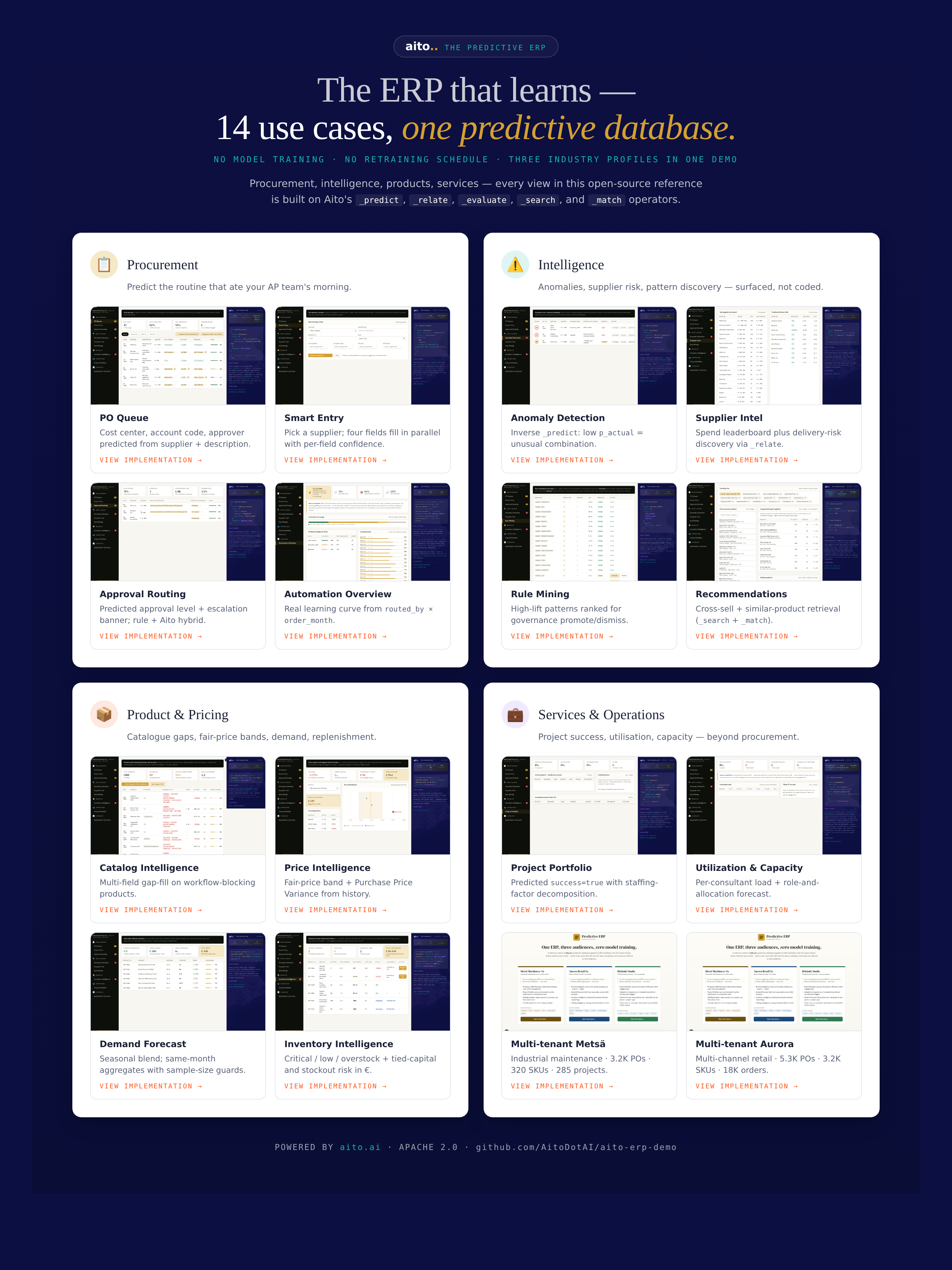
erp.aito.ai is our open-source reference implementation of a predictive ERP — 14 production-ready views built on _predict, _relate, _search, and _recommend. The same code powers three industry profiles (industrial maintenance, multi-channel retail, professional services), each with its own Aito database and persona-appropriate fixtures.
Explore the Use Cases → · Try the Live Demo → · Source on GitHub →
What's Inside the Predictive ERP Reference
Procurement & approvals
- 📋 PO Queue — Each purchase order arrives with predicted account code, cost center, and approver — visualised in three confidence tiers, with bulk-approve for rule-matched rows.
- ✨ Smart Entry — Multi-field prediction with cross-highlight: pick a supplier and four fields predict in parallel (cost center, account code, project, approver). Tab to accept, Esc to reject.
- ✅ Approval Routing — Aito surfaces governance candidates like "amount > €5K + security → CFO" via
_relate; nothing becomes policy without explicit signoff. - ⚠️ Anomaly Detection — Inverse prediction: low confidence on a normally-predictable field is the anomaly. Three types: amount-spike, unknown-vendor, mis-coded-account.
Supplier, catalog & pricing intelligence
- 🏭 Supplier Intel — Spend leaderboard plus delivery-risk discovery via
_relate— "Neste Q4 lift 1.4× (33% late rate)". - ⚙️ Rule Mining — Discover statistical patterns with support and lift, promote with audit trail, dismiss to record the decision so it doesn't resurface.
- 📦 Catalog Intelligence — Multi-field gap-filling on workflow-blocking products: predict category, HS code, unit price one-shot across the catalog.
- 💰 Price Intelligence — Fair-price band, flagged outliers, Purchase Price Variance with annualised exposure.
Demand, inventory & projects
- 📈 Demand Forecast —
_predict units_soldblended with seasonality factors derived from same-month historical data. - 🏗 Inventory Intelligence — Days-of-supply, stockout risk, tied capital, weekly margin at risk per row. "Reorder now" creates a real PO that flows back into PO Queue.
- 🗂 Project Portfolio —
_predict successper active project with$whyfactor decomposition, plus a staffing simulator: swap a team member, watch P(success) move. - 👥 Utilization & Capacity — Per-consultant load with role forecasting via
_predict allocation_pct(services tenant).
Cross-cutting
- 🛍 Recommendations — Cross-sell via month co-occurrence and similar-product discovery via attribute overlap (retail tenant).
- 📊 Automation Overview — €220K savings YTD with collapsible methodology footnote; a 29-month learning curve computed live from
routed_by × order_month.
Every view ships with a hero screenshot, working code, and a use-case guide. Same operators across all 14 features — _predict, _relate, _search, _recommend.
How Much Can You Automate? (The Honest Answer)
Two things are true at once.
The verifiable facts. Industry-wide, automated AP error rates land in the 0.1-0.8% range when properly configured; best-in-class AP teams hit 60-80% touchless processing rates and 3.1-day cycle times. Aito has run AP automation at 95%+ accuracy in Nordic enterprise production since 2018, on the same predictive operators. PO-backed invoices typically auto-match at 60-80% via three-way matching before any prediction is needed; predictions earn their keep on non-PO invoices, where even a small share can break a manual-coding workflow.
The conditional answer. All ERP procurement processes are super-regular at their core — procurement contracts, BOMs, scheduled-maintenance cycles, and accounting consistency rules see to that. What differs between customers is how much of your incoming PO volume matches prior patterns vs. arrives as a first-time pattern. Predictive ERP is a conditional-probability engine that works the same way on each transaction; how many of your transactions benefit from it depends on the volume mix.
Why ERP transaction data is unusually predictable to begin with
Procurement and ERP transactions are more regular than typical ML training data because of how the underlying business operates. Procurement contracts lock supplier-account mappings. BOMs and SKU taxonomies are stable across years. Maintenance schedules repeat on calendar cycles. And GAAP/IFRS accounting consistency rules apply once those POs flow into the GL. The same supplier × category combination maps to the same cost center 95%+ of the time, not by coincidence but by operational and regulatory design.
This is why on regular procurement data, three observations of a stable multi-field pattern produces ~90% confidence with realized error around 1%. By five observations, error rates well under 1% are typical. The top confidence bucket (>95%) carries near-zero realized error in production — Aito's confidence is calibrated, so when it says >95%, the realized rate matches.
Three pattern-repetition profiles, three different ranges
Underneath all three, the process is the same — same coding logic, same conditional-probability math, same calibrated confidence. What changes between deployments is the volume mix: how much of the incoming PO stream lands on patterns with ≥3 prior examples vs. arrives as a first-time pattern.
| Profile | Examples | What the volume mix looks like | Range we typically see |
|---|---|---|---|
| Mostly-recurring | Spare-parts replenishment; scheduled maintenance procurement; recurring utility / network supplier POs; BOM-driven manufacturing buys; PO-backed direct procurement | Stable supplier base, calendar-driven schedules, contractually locked terms — the bulk of incoming POs match patterns already seen many times | Near the top of industry benchmarks — 70-90%+ touchless, supplemented by three-way match auto-rates of 60-80% before prediction even applies |
| Mixed | Industrial maintenance with a stable supplier base; multi-channel retail buying; typical mid-market procurement at a mature tenant; mixed PO + non-PO flows | Combination of repeat-pattern POs and one-offs; meaningful share of project-specific spend or new-supplier onboardings each month | Mid-tier of industry benchmarks — 50-70% touchless on common configurations |
| Mostly-snowflake | Construction project POs with subcontractor sprawl; professional services with project-specific passthroughs; employee-expense passthroughs in services workloads | Project-driven spend by construction — many incoming POs are first-time patterns (new subcontractor, new build, new client engagement). The procurement-coding logic is just as regular; the share of incoming POs that match prior patterns is low | Headline touchless rate lower — we've seen ranges in the 20-40% area; field-level prediction still produces 3-4 of 5 fields pre-filled per PO with $why, so manual-effort reduction is much larger than the touchless headline implies |
The conditional-probability machinery is the same across all three profiles. Three observations of any stable pattern produces ~90% confidence with ~1% realized error, regardless of profile. What differs is how many of your incoming POs land on patterns with ≥3 prior examples vs. arrive as novel ones.
Find your profile in 15 minutes: run _evaluate on a held-out slice of your real data. Per-field accuracy and per-confidence-bucket calibration tell you which range your tenants sit in.
Why three examples is enough on regular data
Where contractual and operational stability apply, ERP transaction data isn't noisy. The same supplier × category maps to the same cost center 95%+ of the time. The conditional probability collapses fast because there's not much disagreement to average over.
| Repetitions of a stable pattern | Top-1 confidence | Typical realized error |
|---|---|---|
| 0 | base rate ~5-15% — "no prediction yet" | n/a |
| 1 | ~50-70% — single suggestion | high |
| 3 | ~85-92% — auto-fill territory | often ~1% on regular data |
| 5 | ~92-95%+ | well under 1%, approaching the calibration floor |
| 10+ | at the drift ceiling | calibrated to confidence; near zero in the top bucket |
Not every field is equally stable, even on regular workloads
A subtle but important distinction: even when the workload is regular, not every field is equally stable. The split tells you which predictions need to be more reactive to recent overrides.
| Field type | Stability | Why |
|---|---|---|
| Account code, cost center, expense category, VAT % | High — long-term stable | Locked by chart-of-accounts taxonomy and procurement contracts. Same supplier → same account year over year. |
| Payment terms, delivery terms | High — derived from supplier contract | Contractually stable. |
| Approver / cost-owner / project manager | Medium — changes with personnel | Vacations, role changes, project transitions, team restructuring break recurring person-keyed patterns. |
| One-off supplier accounts (snowflake tail) | Low by construction | No prior history to learn from; supplier-locked fields require human judgement. |
Two practical implications: (a) person-keyed predictions need to be more reactive to recent overrides than account-keyed predictions — handled naturally because every override is the next prediction's training signal; (b) chart-of-accounts reorganizations and supplier-master changes are documented events, so a brief drop in account-keyed accuracy after a reorg is expected and recoverable within ~3 observations of the new mapping.
The snowflake tail and what still works there
ERP procurement always has a long tail. One-off subcontractors on a specific build project, exceptional ad-hoc purchases, employee-expense passthroughs in services workloads, equipment rentals from a supplier seen once — statistical snowflakes by construction. No amount of data resolves them.
The honest answer: supplier-keyed predictions don't work on the snowflake tail. A supplier seen for the first time has zero conditional history. Aito returns honest low confidence, not a wrong high-confidence answer.
What still works on snowflake POs
Different prediction targets depend on different signals. Not every field is supplier-locked:
| Field on a snowflake PO | Predicted from | Useful confidence? |
|---|---|---|
| Cost-center category | Description text + amount range | ✅ "Hydraulic seal" → maintenance category |
| Approver | Cost owner / project manager | ✅ Tied to the person, not the supplier |
| Project allocation | Department / cost-owner | ✅ From the requester, not the supplier |
| VAT % | Amount + country + category | ✅ Not supplier-dependent |
| Specific account code | Supplier history | ❌ Supplier-locked, falls to low confidence |
| Supplier master ID | Supplier history | ❌ Supplier-locked, falls to low confidence |
Smart Entry on a snowflake PO doesn't return blank fields. It returns field-level predictions with field-level confidence, with $why rendered so the reviewer sees what was used. Three or four of five fields auto-fill; the supplier-locked fields surface for human judgement.
What production actually looks like — two anchor points
Anchor 1 — recurring industrial procurement ("highly regular"). A workload dominated by recurring supplier POs against a stable category catalog — spare-parts replenishment, scheduled maintenance procurement, recurring utility/network suppliers — looks like:
- ~80%+ fully automated at the high-confidence threshold, realized error near zero.
- ~15-20% reviewed-with-prefill — mostly the medium-confidence tail.
- ~0-5% mostly manual — the actual one-off long tail.
Anchor 2 — heavy snowflake tail ("highly diverse"). A predictive ERP workload with significant project-subcontractor or ad-hoc spend splits roughly into thirds:
- ~1/3 fully automated. Top confidence bucket. Realized errors essentially zero — Aito's confidence is calibrated.
- ~1/3 reviewed but pre-filled. Mid-confidence across most fields. Reviewer confirms instead of types — 4-5× speedup over manual coding.
- ~1/3 partially filled, mostly manual. Snowflake POs where supplier-locked fields are unknowns. Even here, category, approver, and project are usually pre-filled with
$whyrendered, so the human judges 1-2 fields, not all 5.
Both are real production observations. Most products serve a mix of tenant shapes and land between the two anchors.
Buyer diligence: run _evaluate per field
The single best 15-minute test is to run _evaluate on a held-out slice of your real data. Pay attention to two things:
- Per-field accuracy. Description-keyed fields (category, project) typically hit 90%+ even on diverse workloads; supplier-locked fields drop sharply on the snowflake tail.
- Per-confidence-bucket calibration. The top bucket should land at near-zero realized error if the model is well-calibrated. If it doesn't, your tiered-confidence UI plan won't work.
Your UI keys off field-level confidence per prediction: auto-fill the high-confidence fields, suggest the medium, route the low to human review with $why. Cold-start handles itself field by field, confidence-bucket by confidence-bucket.
The drift ceiling, honestly
Per-field accuracy on the recurring core caps around 92-95% from drift (supplier account changes, taxonomy shifts, org reorgs, personnel changes for person-keyed fields). Per-field accuracy on the snowflake tail caps lower; that ceiling is structural. Tenant-wide headline accuracy is the volume-weighted blend.
A predictive ERP product covering tenants with heavier snowflake shares will see lower headline accuracy — that's the data, not the model. Both numbers are correct, and both are useful, as long as your UI is field-level confidence-aware.
Pick your closest fixture profile to bootstrap
The reference ships three: Metsä Machinery (industrial maintenance — heavy recurring core), Aurora Retail (multi-channel commerce — mixed), Helsinki Studio (professional services — heavier passthrough tail). Each is its own Aito DB with 3-5K POs of persona-appropriate data. Switch tenants in the TopBar and the predictions retone — and the recurring/snowflake split shifts visibly. Your real product points Aito at your tenants' data; the same code path serves them all.
The Override → Learn Loop (Why You Don't Need MLOps)
User changes a predicted cost center from 4220 to 4210 at 14:00:23. The next request for a similar PO — different PO, same supplier, same description — reflects the new pattern in its conditional probability. No retrain queue. No model deploy. No A/B holdout.
| In a typical ML pipeline | In a predictive database |
|---|---|
| User correction → label store | User correction → INSERT |
| Nightly retraining job | (none) |
| Model artifact + deploy | (none) |
| Canary, holdout, regression monitoring | (none) |
| 24-72 hours from correction → live | <1 second |
This is why predictive ERP scales differently than traditional procurement automation. Rules rot; predictions improve with every override.
The End-to-End Workflow Loop
The signature interaction in a predictive ERP is the loop: Smart Entry submits → PO Queue picks it up → Approval Routing predicts the approver → Inventory reorder creates the next one. Every override trains the next prediction.
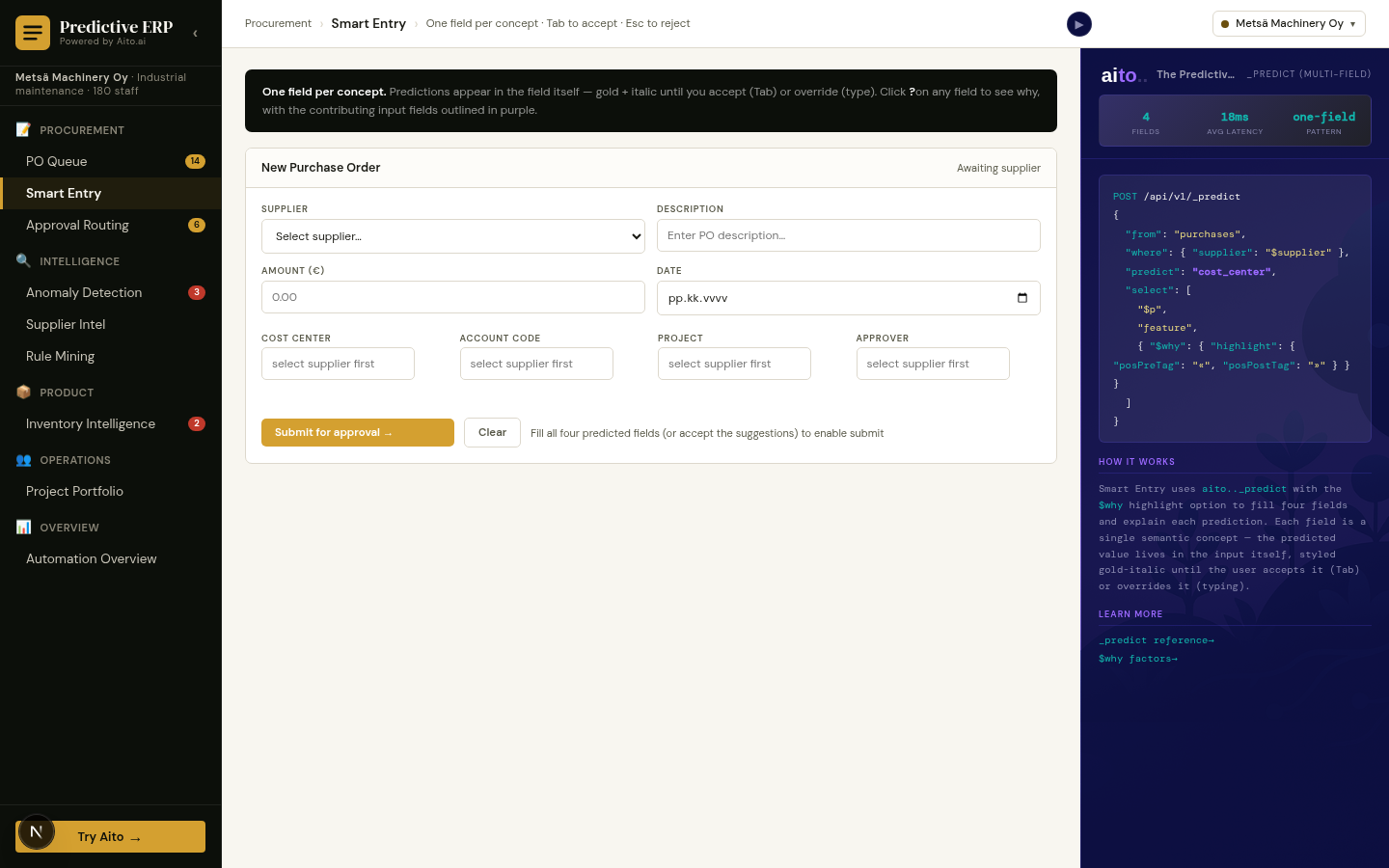
That's the whole demo in one screenshot: pick a supplier, four fields predict, click submit, watch it route. No retraining between steps, no model deployment after a correction.
Try Live ERP Predictions
Run the same predictions used by erp.aito.ai directly from this page. These queries hit our hosted demo database — no signup, no setup.
Interactive Predictive ERP Queries
Run live queries against erp.aito.ai's Metsä Machinery (industrial maintenance) demo database
Cost Center Prediction
Predict the cost center for a workwear PO from Lindström Oy
{
"from": "purchases",
"where": {
"supplier": "Lindström Oy",
"description": "Workwear order"
},
"predict": "cost_center",
"select": [
"$p",
"feature",
"$why"
]
}Three Industry Profiles, One Predictive Database
The same predictive ERP code drives three personas, each with its own Aito DB and persona-appropriate fixtures:
| Profile | Audience | Data Shape |
|---|---|---|
| Metsä Machinery Oy | Industrial maintenance / construction (Lemonsoft-shaped buyer) | Wärtsilä, ABB, Caverion, NCC · 3.2K POs · 320 spare-part SKUs · 285 maintenance/construction projects · 46 months of history |
| Aurora Retail Oy | Multi-channel retail (Oscar / ERPly-shaped buyer) | Valio, Marimekko, L'Oréal · 5.3K POs · 3.2K SKUs · 18K orders · 6.5K price points |
| Helsinki Studio | Professional services (horizontal SaaS buyer) | Adobe, AWS, Figma · 3.2K POs · 435 client engagements · 2.1K assignments |
Each profile filters which views appear in the side nav. The right-rail Aito panel re-tones with persona-specific examples: Metsä's panel quotes Wärtsilä → account 4220; Aurora's quotes Valio → account 4010; Studio's quotes Adobe → account 5530. Switch tenants in the TopBar — same code, different conditional probability distribution.
Three Signature Interaction Patterns
Three small, reusable components carry the predictive-application UX. Anyone porting this pattern to another vertical should keep them.
PredictionExplanation — the $why renderer
Pure component that turns Aito's $why factor tree into:
- Prediction value + confidence bar
- Base rate (
baseP) - Top 3-5 pattern matches with token-level highlighting
- The multiplicative chain
baseP × lift₁ × lift₂ × … = finalP - Top 2-3 alternatives, clickable to override
WhyPopover — confidence-aware ledger annotation
A ? / ! button anchored to a row that opens a popover. Visual prominence scales inversely with confidence — faint at ≥85%, gold at 50-85%, pulsing red ! at <50%.
SmartField — three-state input
Single DOM input that's the same field whether the value came from a prediction or the user. Three visual states: empty / predicted (gold-italic with 🤖 badge) / user (normal). Tab promotes, Esc rejects, typing replaces.
These match the patterns in the Smart Forms and Prediction Explanations guides.
Predictive ERP vs. Traditional Procurement Automation
Traditional procurement automation means: write a routing rule, write a coding rule, write an approval rule, write an anomaly rule. Maintain them. Watch them rot. Hire people to clean up the 70% that doesn't fit.
A predictive ERP flips it: load your transactions, query for predictions, promote patterns to rules with governance. No retraining, no MLOps, no feature engineering. The data is the model.
| Approach | Coverage |
|---|---|
| Traditional rules-only procurement automation | ~21% ceiling, high maintenance |
| Predictive ERP on Aito | 21% rules + 51% predictions + 28% honestly flagged for review = 72% real automation |
Technical Implementation
Simple API Integration
Every predictive ERP feature reduces to a SQL-like JSON query:
{
"from": "purchases",
"where": {
"supplier": "Wärtsilä Components",
"description": "Hydraulic seals #WS-442",
"amount_eur": 4220
},
"predict": "cost_center",
"select": ["$p", "feature", "$why"]
}
Response in ~30 ms with the prediction, confidence, top-3 alternatives, and the full factor decomposition.
Aito Operators Used
| Operator | What it does | Used in |
|---|---|---|
_predict | Predict a field value from context | PO Queue, Smart Entry, Approval, Anomalies, Catalog, Demand, Projects |
_relate | Discover statistical patterns with support and lift | Supplier Intel, Rule Mining |
_recommend | Goal-oriented ranking over an impressions table | Cross-sell, similar-product |
_search | Retrieve records | Aggregate metrics, learning curve, PPV |
Schema Evolution Without Migration
ERP schemas change. Tenants add custom fields, redefine cost-center taxonomies, split SKUs, introduce new GL accounts mid-year. In a typical ML pipeline, every schema change triggers a migration ticket: update the feature pipeline, re-extract features, retrain, redeploy.
In Aito: add a column, the next prediction reflects it. No migration step, no retraining trigger. Aito stores rows as semi-structured documents; the next _predict query that includes the new field uses it as another conditional in the probability calculation. Existing queries that don't reference it are unaffected.
This is what makes Aito viable for a 10-year ERP product. You can't ship a long-lived product on top of a feature pipeline that needs schema-coordination on every customer's chart-of-accounts change.
Multi-Entity, Multi-Currency in Production
The reference demo runs three single-entity profiles. Production customers handle multi-entity in one of three patterns:
- One Aito DB per legal entity. Cleanest isolation; predictions never cross entity boundaries. Right when entities have different charts of accounts, different approval hierarchies, or different statutory requirements. Cost: one Aito plan per entity.
- One DB with
entity_idinwhere. Same predictive database, conditional probability scoped per entity in the query. Right when entities share a chart of accounts but want predictions to learn from each other (e.g., subsidiaries of the same group). Same multi-tenant pattern ascustomer_idfor SaaS. - Hybrid: federated DBs + cross-entity
_evaluate. Per-entity Aito DBs for prediction, plus a roll-up DB that ingests all entities' transactions for cross-entity rule mining and group-level benchmarking. Right when group analytics matters but entity-level isolation is required for SOX or statutory reasons.
For multi-currency: store amounts in the transaction currency plus a normalized base currency (EUR, USD, etc.). Predict against the normalized field; display in the original. Aito's conditional probability doesn't care about units, but consistency in the column matters.
What's Intentionally Out of Scope
The reference implementation owns its gaps. Three-way matching, GL period control, multi-country chart of accounts, segregation of duties, multi-entity / multi-currency, audit trail persistence, schema evolution, multi-worker cache coherence, p99 load testing, e-Invoice generation — these are real ERP concerns, intentionally not in the demo. Each one is documented in the README's "What this demo does NOT show" section with the production path forward.
Prove It on Your Data in 15 Minutes
The fastest way to disqualify Aito for your ERP use case is to run _evaluate on a slice of your real transactions.
- Export 1,000-10,000 POs (or sales orders, journal entries, work orders) as CSV — supplier/customer, amount, description, the field you'd predict, and any context columns.
- Upload to a free Aito sandbox.
- Run
_evaluateon a held-out slice. Get per-class accuracy, top-3 accuracy, confusion matrix, and a baseline-vs-Aito diff. - Compare to always-predict-majority and to whatever rule set you have today.
If the lift is convincing, schedule a technical review. If not, an afternoon saved a procurement cycle.
Build vs. Buy: The Honest Math
For a 5-15 person product team building a predictive ERP SaaS:
Build it yourself. A working prediction loop with multi-tenancy, retraining, evaluation, and override capture takes ~6 months and ~1.5 FTEs (one ML engineer, ~0.5 backend for plumbing). At €100-130K loaded ML salary plus infrastructure: year-1 TCO €200-400K, year-2 €120-200K maintenance. Plus you're operating retraining infrastructure in production.
Drop in Aito. API key and SQL-like queries, 1-2 weeks to a working prediction loop. Multi-tenancy is customer_id (or tenant_id) in the where clause. Aito plans start at €0 (sandbox), €75/mo (small production), €350/mo (growth) — see pricing. You give up some control over model internals; you gain ~5 months of engineering and the right to delete user data without a model-retraining ticket.
The breakeven question. Time to first paying tenant matters more than build-vs-buy purity. Six months later means six months less revenue and a smaller dataset to learn from when you do ship.
Throughput & Sizing Per Plan
Latency is per-prediction (~30 ms typical). Throughput is what you provision for, and Aito plans differ by API-call quota and storage:
| Plan | Cost | API calls / month | Storage | Right for |
|---|---|---|---|---|
| Sandbox | €0 | 5,000 | 100 MB | Evaluation, PoC, _evaluate runs on sample data |
| Dev | €75 | 500,000 | 500 MB | One small production tenant or pilot |
| Prod | €350 | Unlimited | 1 GB (extendable) | Single-instance production at SME scale |
| Enterprise | Contact | Custom | Custom | Multi-tenant SaaS, multi-entity groups, dedicated infra |
Worked example. A predictive ERP SaaS with 200 tenants averaging 50 POs/day each = 10K POs/day. Each PO triggers ~5 predictions (cost center, account, approver, project, anomaly check) = 50K predictions/day. Add Smart Entry (4 predictions per supplier-pick, ~20K supplier-picks/day) = ~150K predictions/day. Comfortable on Prod (€350/mo, unlimited). Storage at ~10K rows per tenant fits 1GB at this stage; extends as you grow.
For multi-tenant SaaS beyond ~500 tenants or multi-entity ERP groups, contact us — Enterprise pricing is per-instance with dedicated infrastructure. Nordic enterprise AP workloads have run at this tier since 2018.
How This Compares: SAP Joule, Oracle AI, GPT-4 + a Vector DB
The four honest alternatives we hear:
vs. SAP Joule / Oracle Adaptive Intelligence / NetSuite SuiteAnalytics. These are bundled with the underlying ERP — great if you're already there, locked in if you're not. They don't help you build a new predictive ERP product. Aito is the substrate for vendors building one.
vs. GPT-4 + a vector database for procurement. LLMs reason well over unstructured input but cost ~1-3 sec per call, are opaque (no $why), and don't learn from corrections. For volumetric ERP work — thousands of POs/day per tenant — the unit economics break. Use LLMs for free-form supplier-message classification, Aito for the structured prediction.
vs. building it on scikit-learn / Vertex AI / SageMaker. You can. You'll spend the 6 months above. The thing you build is a worse predictive database with retraining infra you operate.
vs. RPA-based procurement automation (UiPath / Blue Prism with rule scripts). Rules cap at ~21% coverage and rot. Aito reaches 70%+ real automation by routing high-confidence rows automatically and honestly flagging the rest. Most predictive-ERP customers run UiPath and Aito — RPA for the deterministic plumbing, Aito for the decisions.
Security, Compliance & Data Residency
- EU data residency by default. Hosted in AWS Frankfurt (eu-central-1). US deployment on request.
- Encryption. TLS 1.2+ in transit; AES-256 at rest.
- Tenant isolation. Per-customer Aito instances by default; shared multi-tenant pattern is opt-in.
- DPA. GDPR-aligned Data Processing Agreement on request.
- Audit logging. Every API call logged with timestamp, key ID, query, and response time.
- Right to be forgotten. No model artifact derived from user data —
DELETEthe rows and predictions reflect it from the next query forward.
We do not currently hold a SOC 2 Type II attestation; we share our security posture and pen-test results under NDA. For procurement that requires SOC 2 today, contact us — we work with regulated-finance customers under DPA + security questionnaire.
Platform Stability & Long-Term Commitment
ERPs ship for 10+ years. Before you bet a product roadmap on Aito, the questions you should ask:
- API stability. The core query API (
_predict,_relate,_search,_recommend,_evaluate,_match) has been stable since the v1 release in 2018. We version at the API level — breaking changes ship as new endpoints, never as silent behavior changes on existing ones. - Deprecation policy. Minimum 12 months notice before any deprecation. Migration guides published with each.
- Operating history. Aito has run in production since 2018 across multiple corporate owners — Nordic enterprise AP deployments processing thousands of invoices per month at 95%+ accuracy. See About for the current corporate posture.
- Source of truth, not lock-in. Your data goes in via standard JSON. It comes out via
_search. There is no proprietary format you can't export. Worst case migration: read your rows, write them somewhere else. - Open-source reference implementations. The accounting and ERP reference apps are Apache 2.0. If our company posture changes, the patterns we taught remain yours to operate.
For the company posture, funding, and team behind Aito — see About or contact us for current details under NDA. Multi-year procurement reviews welcome.
Where Predictive ERP Fits
For ERP SaaS vendors — bake predictions into your product. Smart Entry, anomaly flags, and approval routing become default features instead of premium add-ons.
For ERP integrators — bolt a predictive layer onto an existing customer install. Aito sits alongside SAP / Oscar / Lemonsoft / NetSuite as a prediction service called via API. See the accounting solutions page for the AP-automation pattern.
For internal IT — augment your ERP UI with predicted fields without going through the model-training-and-deployment cycle. Add a row, the next prediction reflects it.
Get Started Today
Ready to ship a predictive ERP — or add predictive features to one you already operate?
Try erp.aito.ai → — see what 14 predictive ERP views look like across three industry profiles.
Read the source on GitHub → — Apache 2.0, 14 use-case guides, three-tenant reference architecture.
Schedule a Demo — walk through your specific ERP automation use cases with our team.
Start Free Trial — point Aito at your own transaction data in our sandbox environment.
Why we built all of these on one substrate
Predictive Accounting, Predictive ERP, and Predictive E-commerce are not three separate products. They are three instances of the same pattern: a SaaS application designed around the premise that the user should never make a decision the data has already made for them. The substrate is a predictive database. Prediction becomes a query rather than a project.
For the full architectural argument, see The Predictive Application. The canonical explanation of why per-prediction cost determines what gets built, and what changes when that cost collapses.
Address
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429







