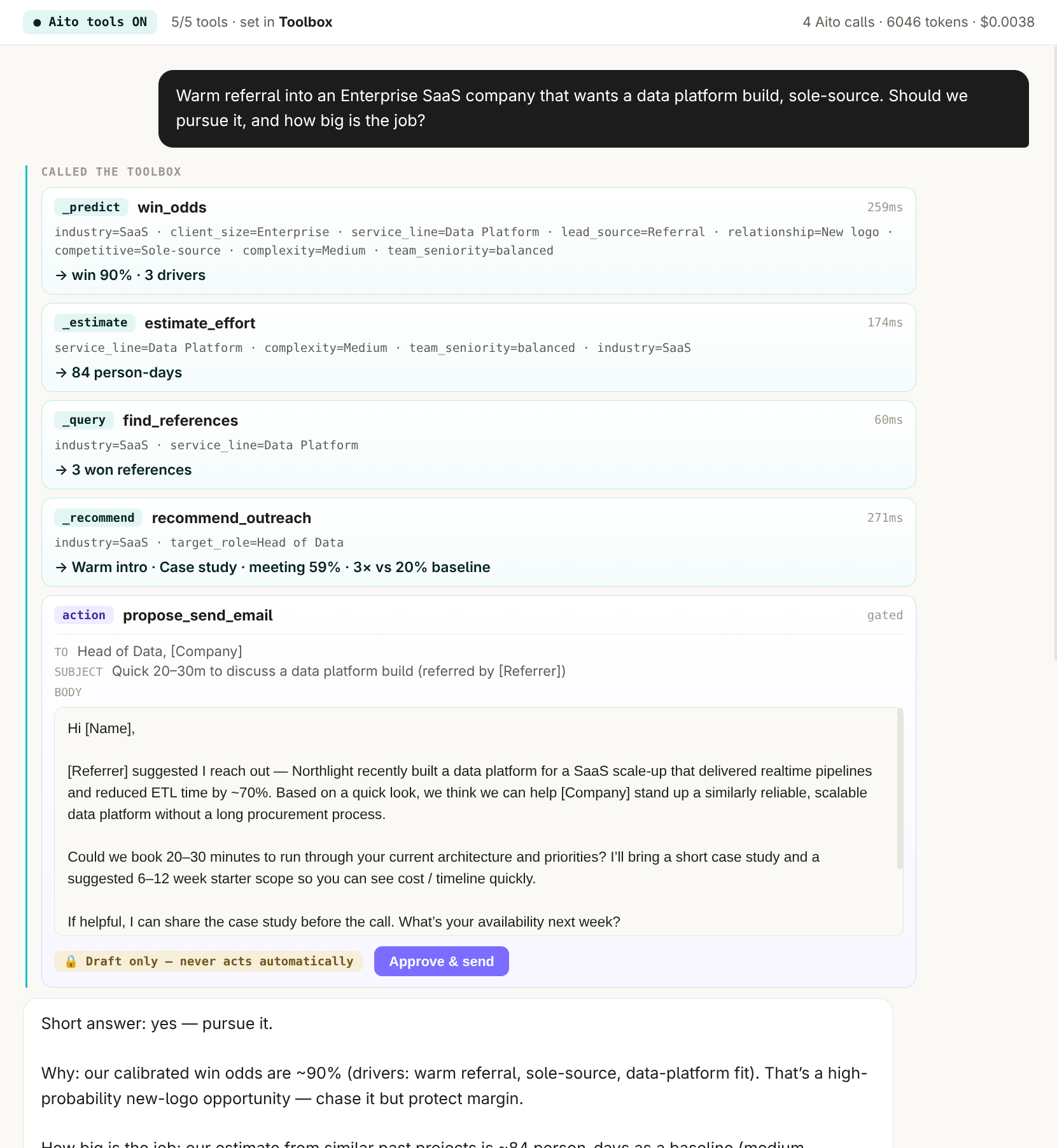
The problem
Agents pick their next action from a tool catalog, and the catalog grows. With a dozen tools, stuffing every tool description into the prompt works fine. At hundreds of tools it stops working twice over: the prompt gets expensive on every single step, and the standard fix, an embedding-retrieval shortlist over tool descriptions, starts dropping the right tool out of the top-k. In the live benchmark, handled-correct fell from 58 to 40 out of 75 as the catalog grew from 12 to 340 tools.
The shortlisting decision is structured, not semantic. Which tool handles this intent, for this customer, in this state, is a conditional-probability question over the agent's own call history. That makes it a prediction, not a similarity search.
How it works
A single _predict on the tool-call history table returns the most likely tools for the incoming request, each with a calibrated probability. The application keeps the candidates above a threshold and hands only those to the LLM for the final pick. In the live benchmark the prompt drops from 3,842 tokens to 237 for the same shortlist, roughly 16× fewer, and the shortlist quality holds as the catalog grows because the prediction conditions on usage, not on how the tool descriptions happen to be worded.
Every resolved request writes back: the tool that actually handled it becomes the next training row, so a tool added today is shortlist-eligible as soon as its first calls land in the table. The benchmark (telco-tool-routing-bench) runs live at agent.aito.ai with the short-list view open.
{
"from": "tool_calls",
"where": {
"intent": "change_subscription_tier",
"customer.segment": "consumer"
},
"predict": "tool",
"select": ["$p", "tool"],
"limit": 5
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🤖 Agent demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
Why not embedding retrieval over the tool descriptions?
Descriptions are written once and similarity over them ignores how tools are actually used. In the live benchmark the embedding shortlist degraded from 58 to 40 of 75 handled-correct as the catalog grew to 340 tools; the predictive shortlist conditions on the agent's real call history and holds. The two can also compose: embeddings for cold-start description matching, _predict once usage data accumulates.
How does this fit MCP and function-calling APIs?
Aito is a query the agent calls like any other tool, or exposes as an MCP endpoint. The shortlist step runs before the LLM's function-calling pass, so the LLM sees a handful of candidate tools with probabilities instead of the full catalog. No orchestrator or platform change; the agent framework stays the brain.
What happens with a brand-new tool that has no call history?
It starts at low confidence, like any unseen value. Teams include a fallback slot in the shortlist for low-history tools or seed a few example calls. After the first handled requests enter the table, the tool ranks normally; a few observations are enough for a stable shortlist position.
How much latency does the extra shortlisting call add?
One _predict, typically well under 200ms, and it can run while the prompt is being assembled. Against a prompt that is roughly 16× smaller on every agent step, the shortlisting call is usually a net latency and cost win, not an overhead.