The problem
An LLM agent is fluent, but on any question that turns on your data it has two bad options: invent a number, or call out to a tool that can answer. Ask it to qualify an opportunity and a pure-LLM agent will produce a confident win probability, an effort estimate, and a list of references that all sound plausible and none of which come from your history. For anything that drives a real decision, plausible is not good enough, and there is no confidence score to decide whether to act.
The fix is not a bigger model or a better prompt. It is giving the agent calibrated tools to call, so the reasoning stays with the LLM and the numbers come from the data. The agent decides what to ask; the predictive database answers with a probability and a $why.
How it works
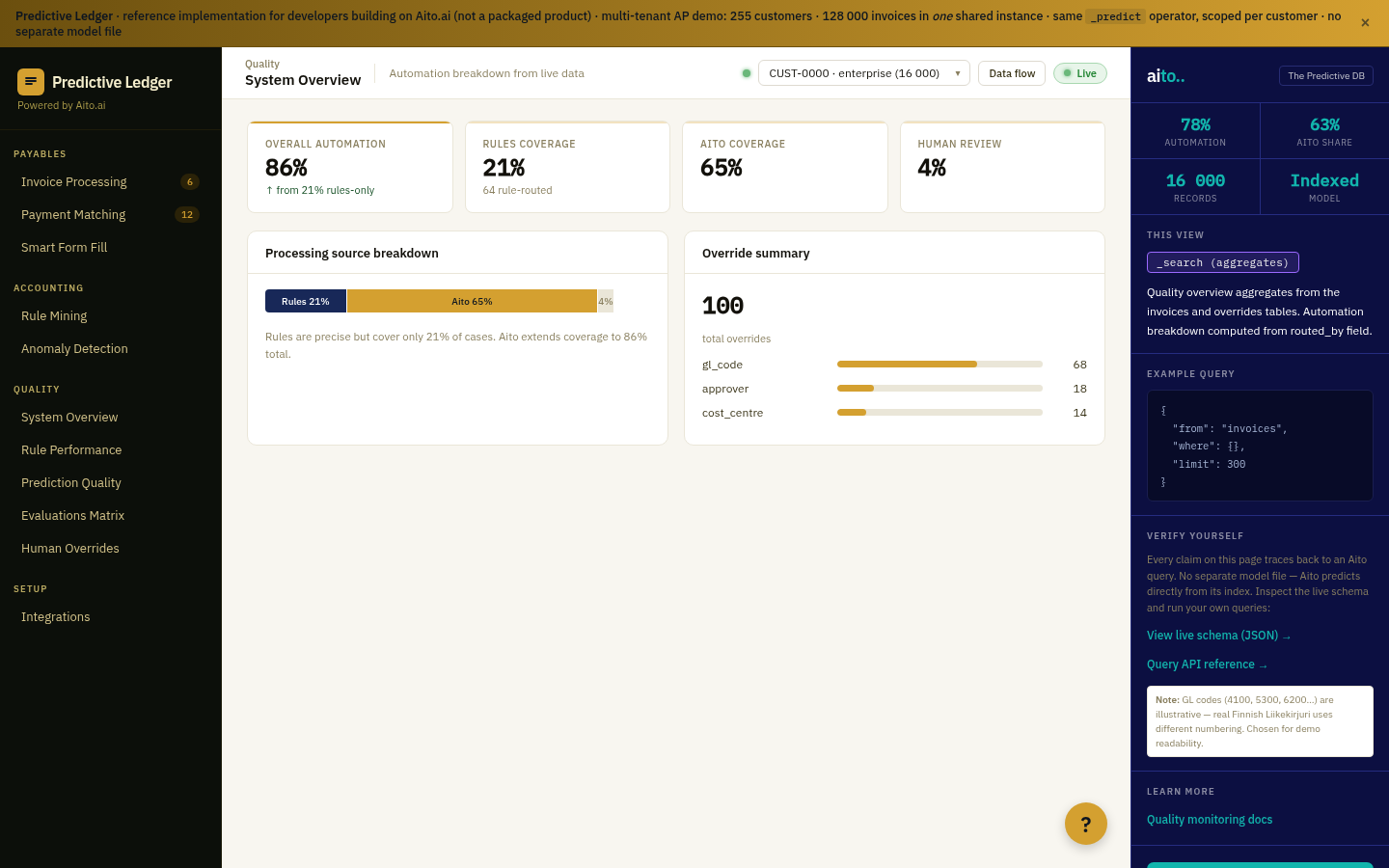
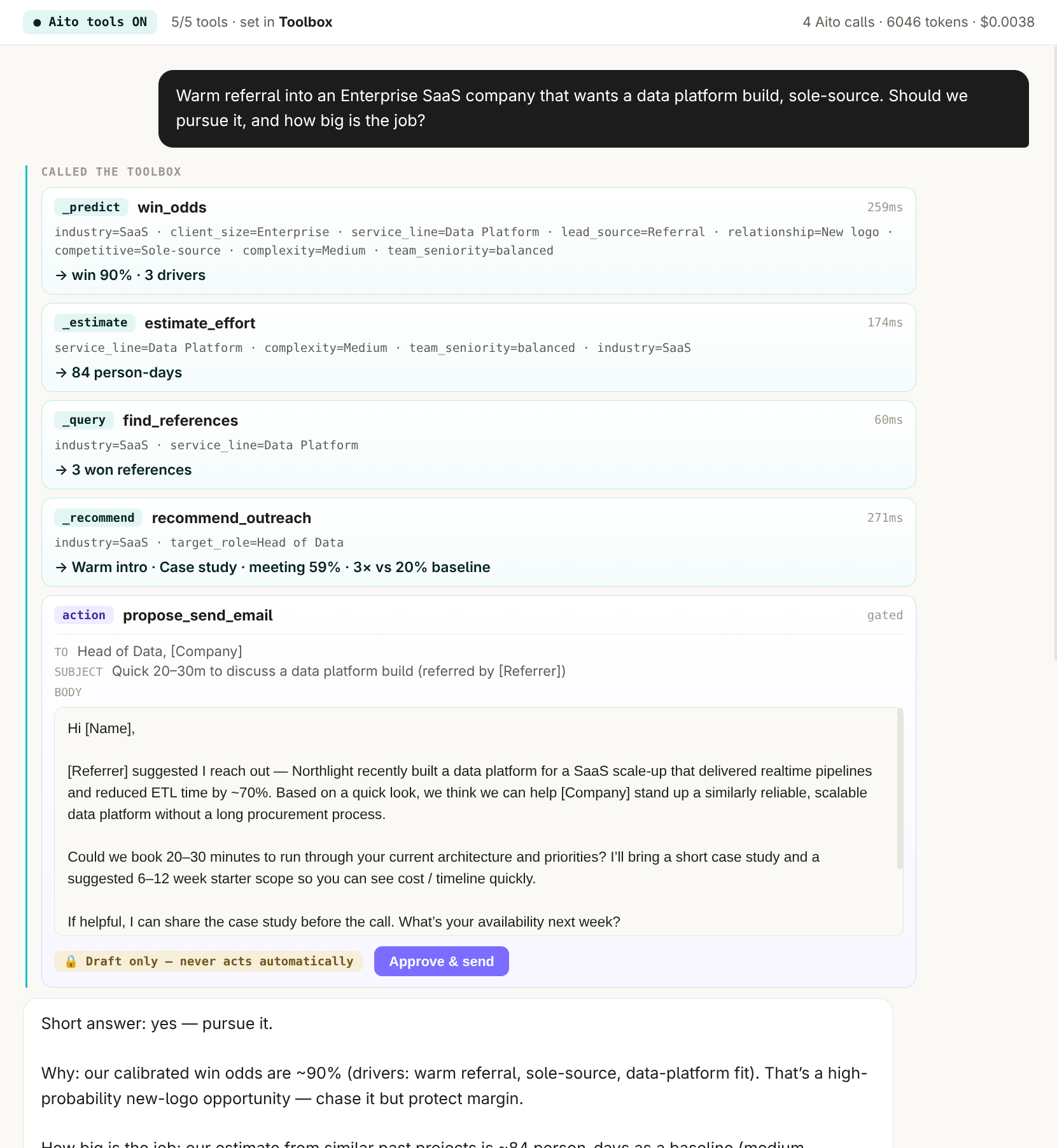
Each Aito operator is exposed to the agent as a tool. In the live sales demo the agent calls four of them on one opportunity: _predict for the win odds with its drivers, _estimate for the effort in person-days, a query for matching won references, and _recommend for the outreach angle that maximises a booked meeting, with the lift over the unoptimised baseline. The LLM orchestrates the calls and writes the reply; every figure in that reply traces to a query over the firm's own history, and the whole exchange runs in roughly 760ms across the four calls.
Actions are gated separately. The agent can draft the outreach email, but the send is a confidence-gated action it is never allowed to take on its own. The same toolbox pattern works for any agent framework or MCP client: Aito is a set of query endpoints the agent calls, not a platform it has to adopt.
{
"from": "engagements",
"where": {
"industry": "SaaS",
"client_size": "Enterprise",
"service_line": "Data Platform",
"lead_source": "Referral",
"competitive": "Sole-source"
},
"predict": "outcome",
"select": ["$p", "$why"]
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🤖 Agent demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How is this different from regular LLM function calling?
The mechanism is function calling; the difference is what sits behind the function. A typical tool wraps a CRUD endpoint or a search. These tools wrap calibrated predictions, so the agent gets a probability and a $why it can reason about and gate on, not just rows. The LLM still decides which tool to call and when.
Does the agent ever act on its own?
Not for anything that matters. Read-style tools (predict, estimate, recommend, query) run freely; actions that change the world, like sending an email, are gated and surfaced for approval. In the demo the draft is produced but the send button is the human's, regardless of how confident the prediction is.
Which agent frameworks does this work with?
Any that support tool or function calling, and MCP clients. Aito is a set of HTTP query endpoints; the tool definitions wrap them. There is no Aito-side orchestrator or runtime to adopt, so the agent framework stays the brain.
What does it cost and how fast is it per call?
Aito calls are sub-200ms each and effectively free relative to LLM tokens; the four-call opportunity workup in the demo totals roughly 760ms. The dominant cost stays the LLM tokens, which is why shortlisting and predicting with Aito instead of stuffing context often lowers the total bill. See Agent Tool Shortlisting for the token math.