The problem
Customer support and internal-help systems have spent years moving from "search for the answer" to "ask the question, get the answer." The current generation routes questions to LLMs; the answer quality is variable, the confidence is uncalibrated, and the cost per query is non-trivial.
The most-asked questions have answers that the team has already written, tagged, or recorded. Help articles, FAQ pages, internal docs, previous ticket resolutions — the corpus is large. The job at decision time is: given the user's question, which canonical answer from the corpus is the right one? With what confidence?
How it works
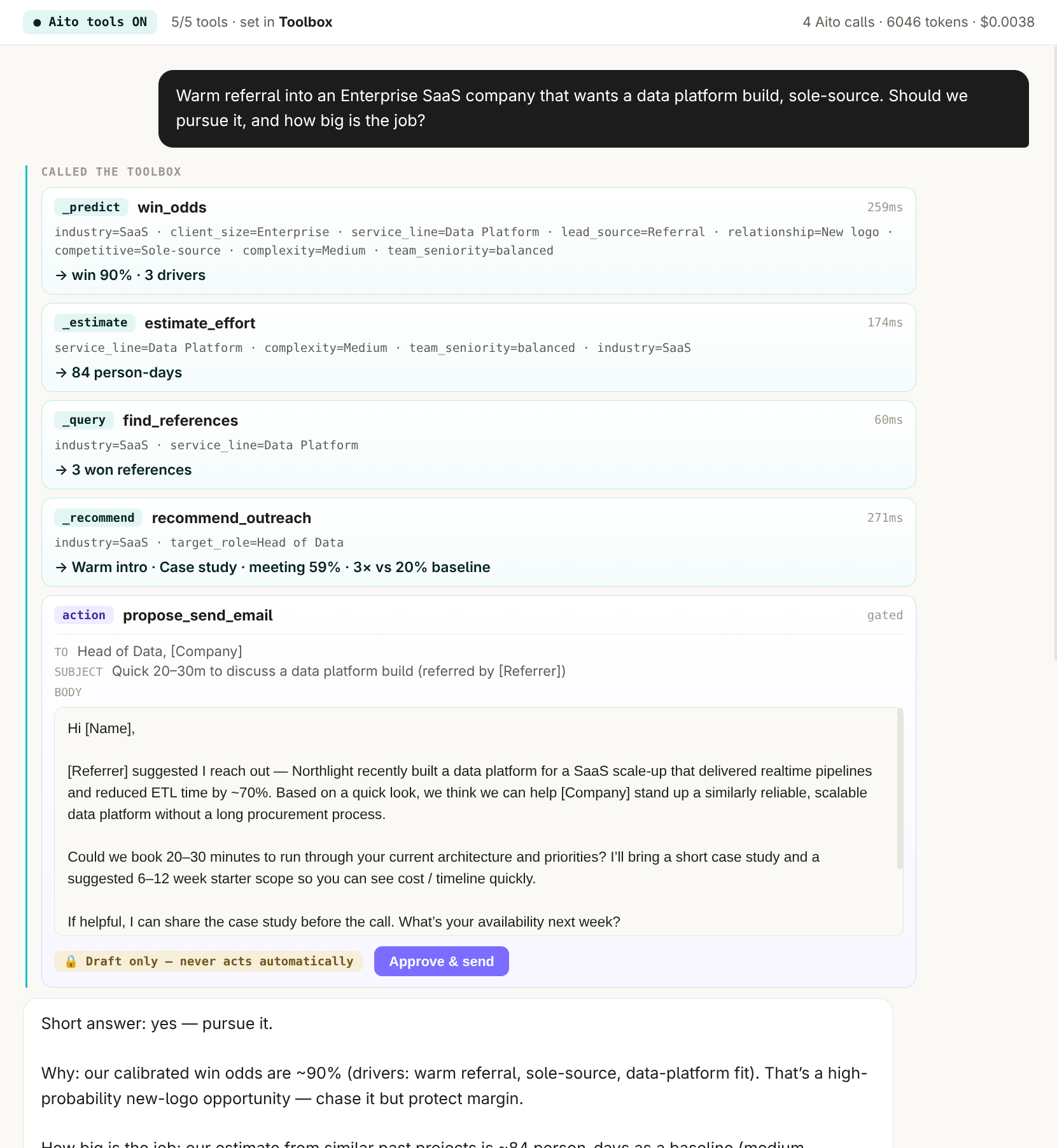
_predict on a prompts-and-answers table returns the most likely canonical answer for a given user question. The system learns from historical question-answer pairs: which questions phrased which way map to which canonical answers, and how confidently. New questions get a predicted answer with calibrated probability.
Above the auto-answer threshold, the application returns the predicted answer directly. Between thresholds, the application returns it as "likely answer, please confirm." Below the threshold, the question routes to a human responder — and the human's response becomes the new ground truth. The corpus expands by usage.
{
"from": "prompts",
"where": {
"prompt": "Which payment methods do you provide?"
},
"predict": "answer",
"select": ["$p", "$why", "answer"],
"limit": 3
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛍 Grocery demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to GPT-style question answering?
GPT generates answers from its training data plus the prompt. _predict returns answers from YOUR corpus, ranked by conditional probability that this canonical answer matches this question. The two are complementary: GPT for open-ended questions outside your domain; _predict for the questions your team has already answered before.
How accurate is this on questions that have never been asked before?
Genuinely novel questions return low confidence; the system says it doesn't know and routes to human. Variations on previously-asked questions get high confidence — the system reads the variation as a known-question with new wording. The conditional-probability machinery handles paraphrasing through the column distribution.
Can the same answer apply to many different question phrasings?
Yes. The conditional probability is over (question → answer). Many question phrasings can map to the same answer with high confidence. The corpus learns the mapping from observation.
Does this need a separate knowledge base, or does it work on existing docs?
Existing docs work if they have a question-and-answer structure. Help-center articles with FAQ sections; support-ticket history with resolved-question and resolution pairs; internal wikis with structured topic pages. The corpus shape is "prompt + canonical answer" — whatever format your team has used.
How quickly does the system learn new canonical answers?
Three observations of a new question-answer pair reaches stable prediction. The system can answer the new question with reasonable confidence by the third occurrence. By ten occurrences, the answer is fully calibrated and safe for auto-answer.