The problem
Conversational interfaces have become the default expected UX for product discovery and support. The customer types or speaks a question; the system answers. Most teams build this by routing the question to an LLM with a system prompt and hoping the answer is accurate. Sometimes it is; often it isn't, and the answer is uncalibrated, expensive per call, and untraceable to source data.
The right architecture composes the LLM with a predictive database. The LLM handles language — parsing the user's question, generating natural-language responses, managing the dialogue. The predictive database handles the structured-data decisions — which products to recommend, which answers are statistically supported, which routing is correct. The two together produce conversational interfaces that are natural-feeling AND grounded in real data.
How it works
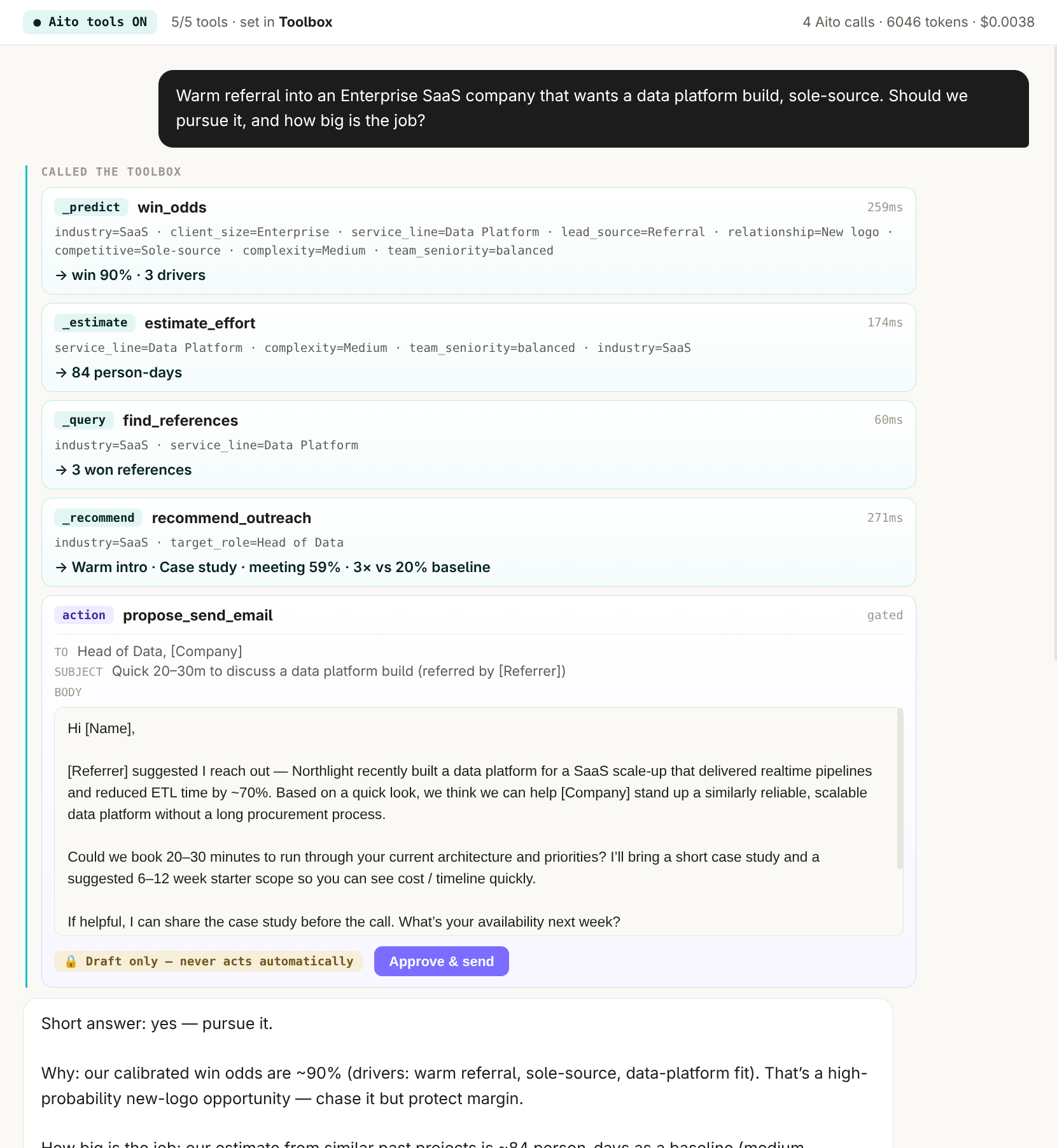
The conversation flow: user types a question. The LLM parses intent ("this is a product recommendation request") and extracts the structured parameters (user identity, mentioned categories, constraints). The application queries Aito with those parameters — _recommend products for this user with these constraints. Aito returns the ranked predictions with calibrated probabilities. The LLM frames the result as a natural-language response, citing the predicted top picks and the confidence behind them.
The split keeps each system doing what it's good at. The LLM handles language; the predictive database handles decisions. The LLM never decides which product to recommend on its own; it always asks the predictive layer. The result is a conversational interface where the conversational quality comes from the LLM and the recommendation quality comes from the predictive database.
{
"from": "impressions",
"where": {
"customer": "alice@example.com",
"product.text": { "$match": "lactose-free milk" }
},
"recommend": "product",
"goal": { "click": true },
"limit": 5
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
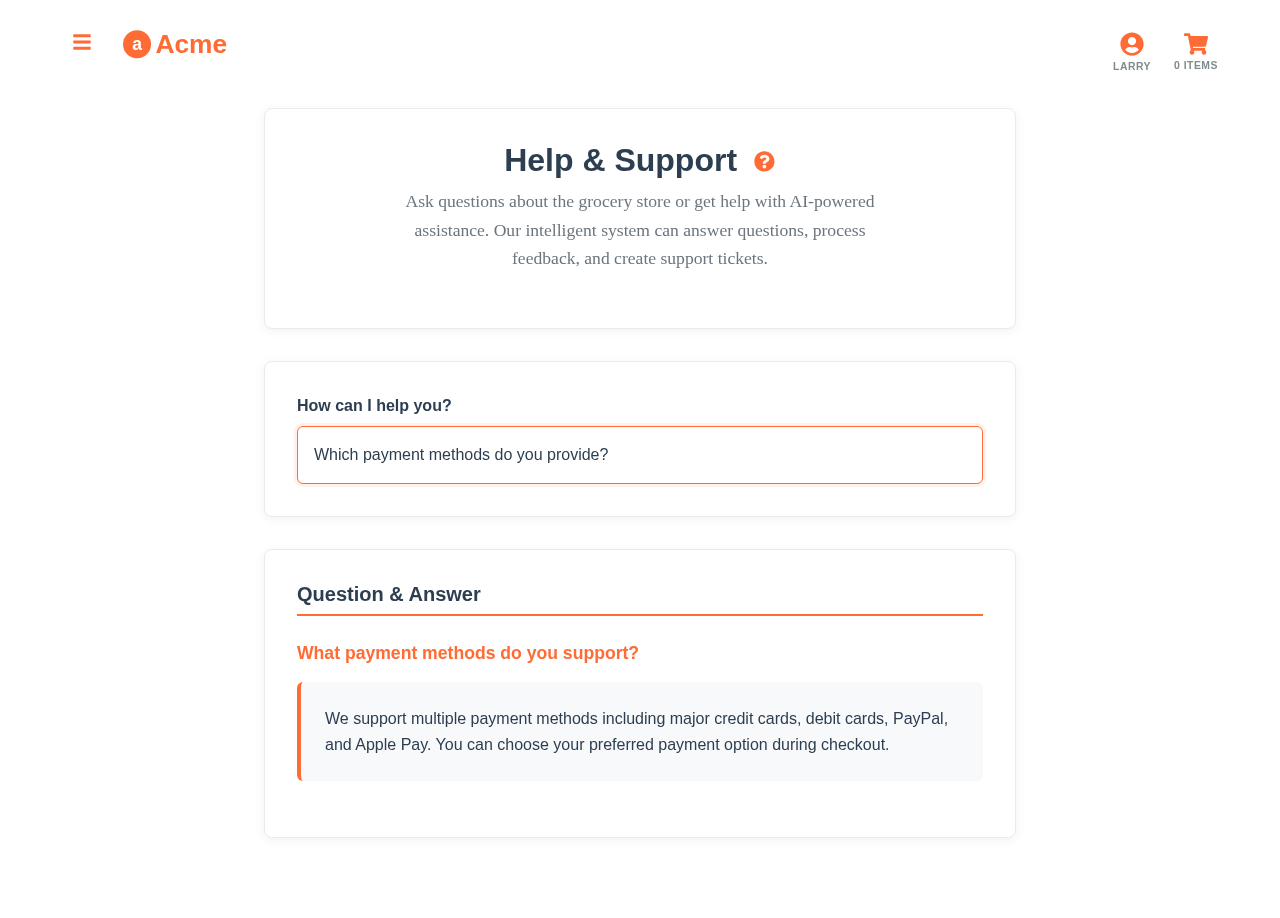
This use case runs in the 🤖 Agent demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
Why not just use an LLM with retrieval-augmented generation (RAG)?
RAG retrieves text passages and lets the LLM compose the answer. For factual lookup over documents, RAG works well. For structured-data decisions (recommendations, routing, predictions with calibrated confidence), RAG produces uncalibrated answers because the LLM generates the confidence from language, not from the underlying probability. The split-architecture approach keeps calibration intact.
How does the assistant handle dialogue context across turns?
Dialogue context is the LLM's job. The LLM maintains the conversation state; on each turn, it decides whether the user's new input needs a new prediction or builds on the previous one. The predictive database is stateless per query; the application layer sequences the queries to match the dialogue.
What about latency — does this double the response time?
Two calls in series (LLM intent → Aito prediction → LLM response) typically adds 100-300ms to a pure-LLM response. Modern dialogue UX accepts this latency; users perceive a coherent response. For very latency-sensitive applications, the calls can be partially parallelised.
Can the assistant explain its recommendations?
Yes. The predictive layer returns $why factor decomposition; the LLM phrases the explanation in natural language. "I'm suggesting this lactose-free milk because you've bought lactose-free products 8 of the last 10 visits." The explanation is grounded in actual signal, not generated.
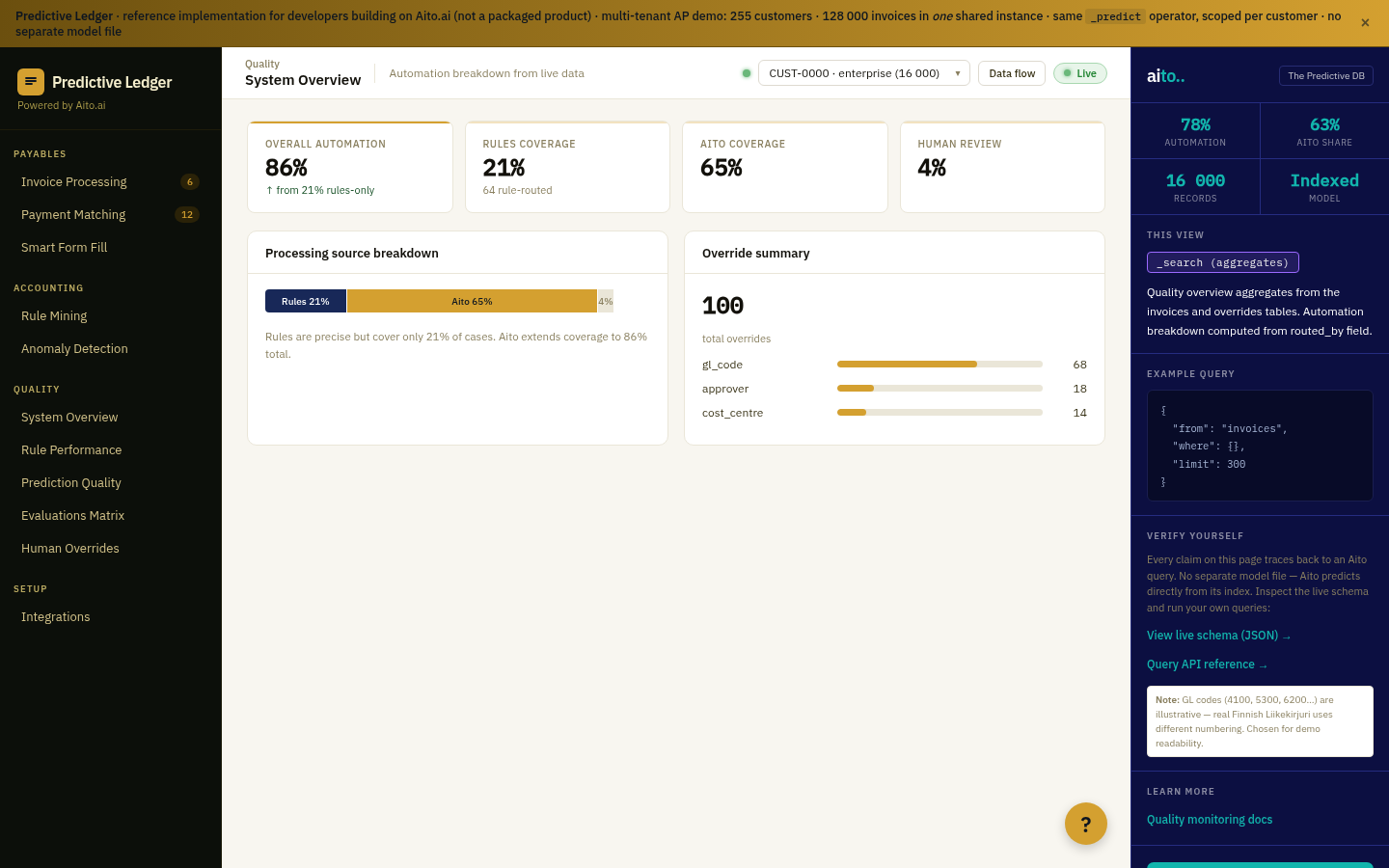
How does this scale to high-volume use cases (millions of conversations)?
The predictive layer scales with infrastructure; the LLM layer scales with token cost. The total cost per conversation is dominated by LLM tokens. Caching common predictions in the application layer reduces per-conversation cost; well-tuned deployments handle millions of conversations on a single Aito instance.