The problem
Autocomplete in product UIs has gone from "prefix match against a static list" to "AI completion via LLM API" in five years. The new approach works but it's expensive (LLM tokens per keystroke), latency-sensitive (each call adds 100-300ms), and uncalibrated (the suggestions feel plausible but aren't grounded in what users actually type).
The data that should drive autocomplete is in the system already. What the user typed last week, what other users in the same segment typed, what search terms produced results that got clicked. The prefix the current user is typing + the available history defines the conditional probability over likely completions.
How it works
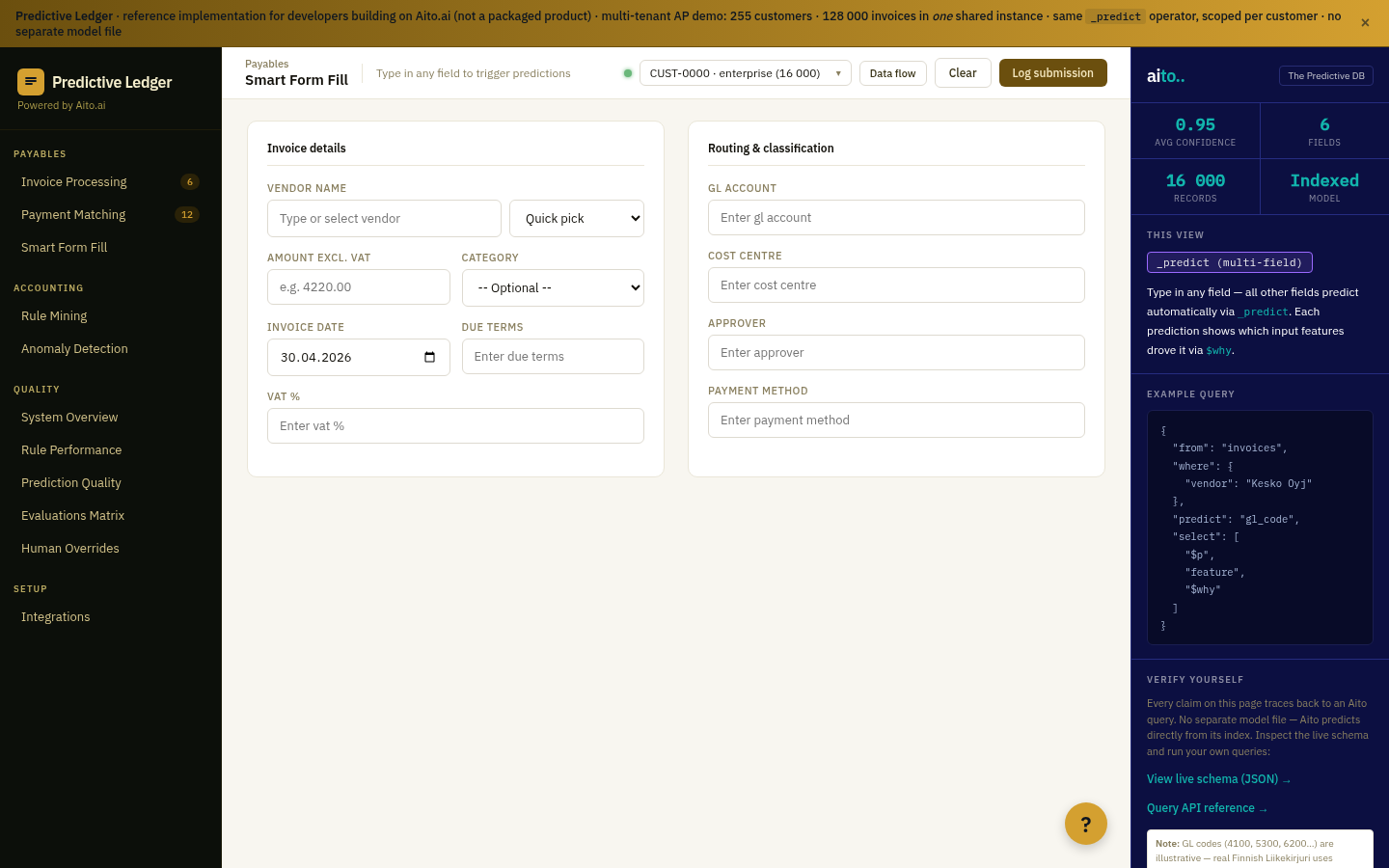
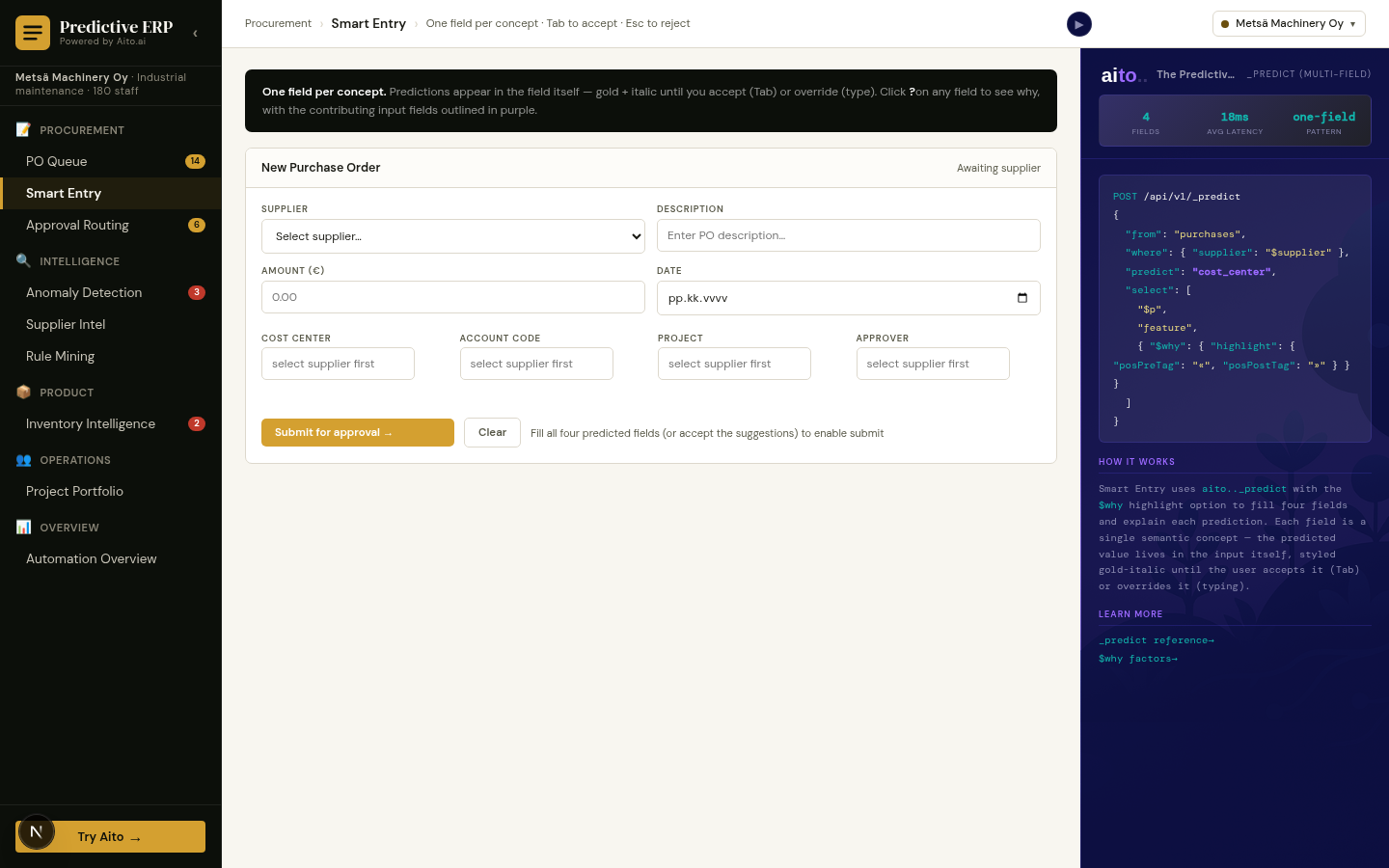
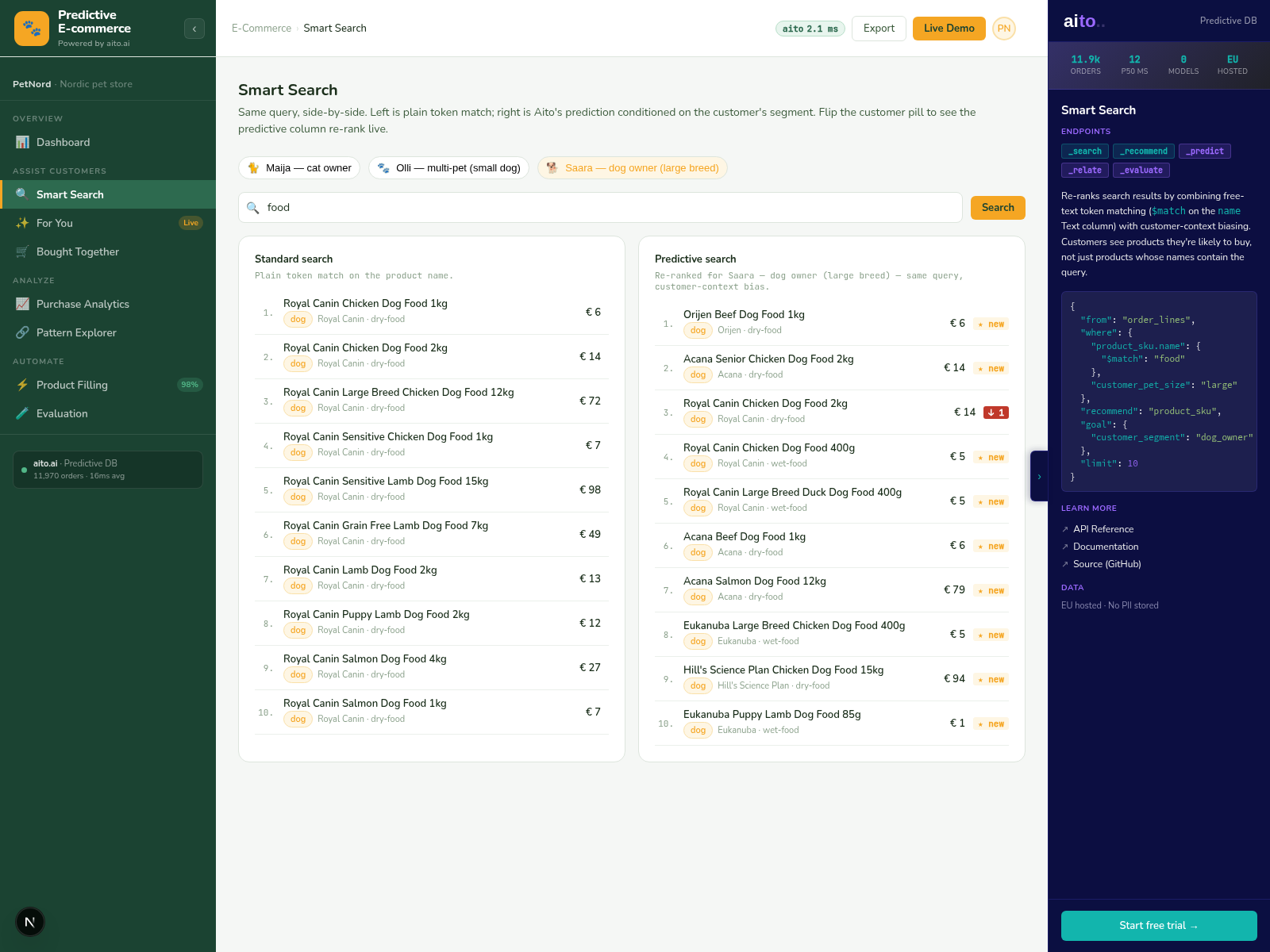
_predict on the query corpus conditioned on the user's prefix and segment returns the ranked likely completions. The keystroke fires the query; sub-50ms response; the dropdown updates with the top-N completions. Each completion is a real prior query (or a real navigation target) — not a generated string.
The mechanism handles typos via column distribution similarity. The user types "shampu"; the system finds the highest-conditional-probability completions that start similarly — "shampoo," "shampoo organic," "shampoo for kids." Each completion is grounded in what users have actually typed, weighted by what produced successful interactions.
{
"from": "search_queries",
"where": {
"query.prefix": "sham",
"customer.segment": "family"
},
"predict": "query.text",
"select": ["$p", "query.text"],
"limit": 8
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛍 Grocery demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to LLM-based autocomplete (OpenAI, Anthropic)?
LLM autocomplete generates plausible-sounding strings; _predict returns real strings from your data. For product or catalog autocomplete, the latter is more accurate because the suggestions are grounded in what users actually typed. For free-text composition (writing email, drafting documents), the LLM approach is better-suited.
Does this work for non-search autocomplete (form fields, address inputs)?
Yes. Any text field with a corpus of prior values works. Address autocomplete on an address-history table; tag autocomplete on a tag-corpus table; product-name autocomplete on the catalog. Same _predict pattern, different corpus.
How fast is the autocomplete (per keystroke)?
Sub-50ms per keystroke in production. The columnar index does the prefix match plus conditional probability in one pass. For high-volume autocomplete (millions of QPS), the same query latency holds; only the infrastructure scaling changes.
Can autocomplete suggestions be ranked by segment or persona?
Yes. The where clause includes the user's segment or persona; the conditional probability scopes to that segment. "sham" autocompletes differently for family-segment than for single-shopper-segment, derived from the data.
Does this learn from accepted vs ignored suggestions?
Yes. The accept/ignore signal enters the index; subsequent predictions reflect it. Suggestions that consistently get accepted rise in rank; suggestions that get ignored despite being shown sink. No retraining; just normal data flow.