The problem
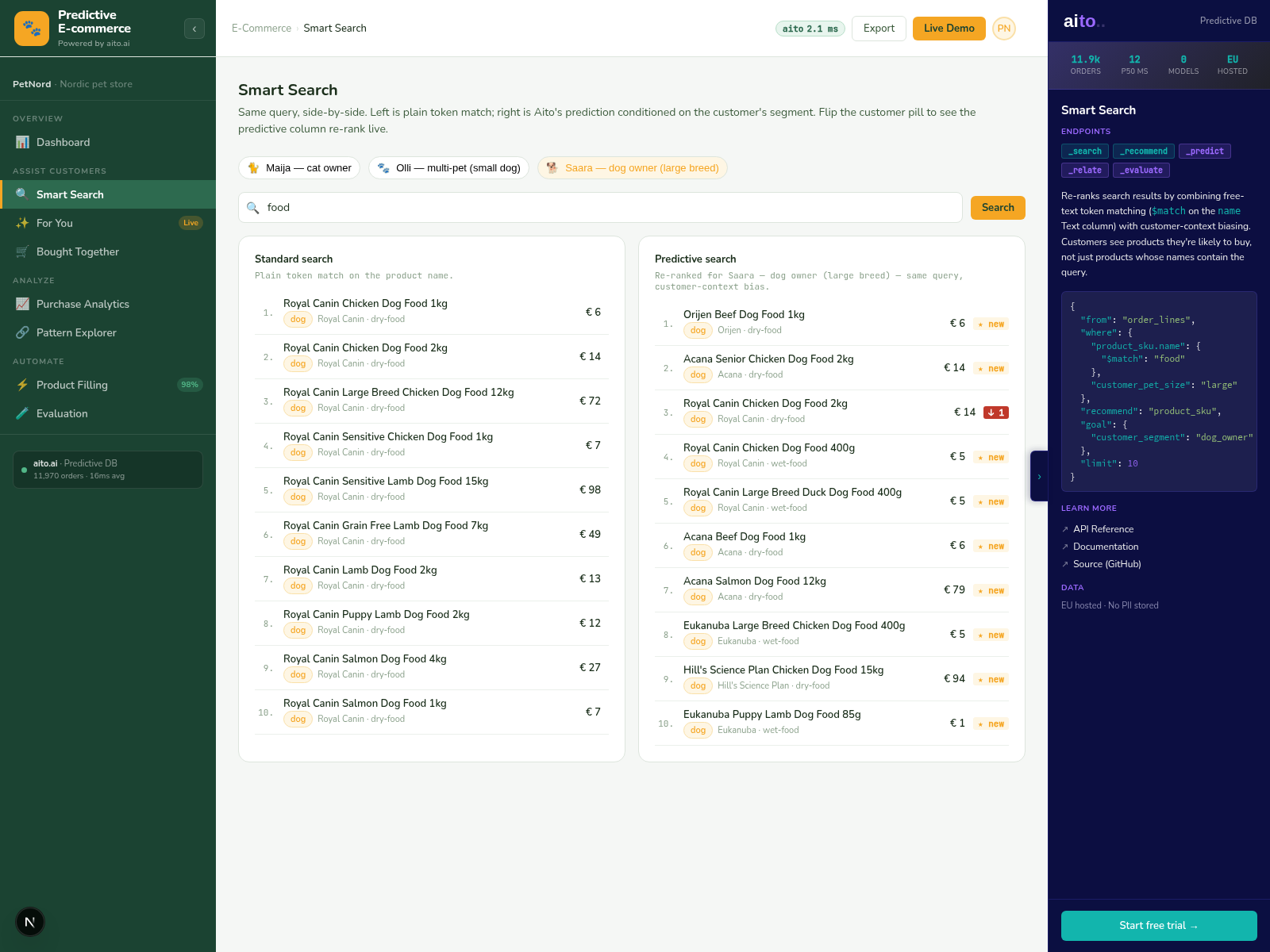
Search in e-commerce is a solved problem if you only care about keyword matching. Plug in Elasticsearch or Algolia and you get fast, scalable retrieval that knows how to handle typos, plurals, and stemming. What those tools do not do is rank results by what this specific user is likely to buy.
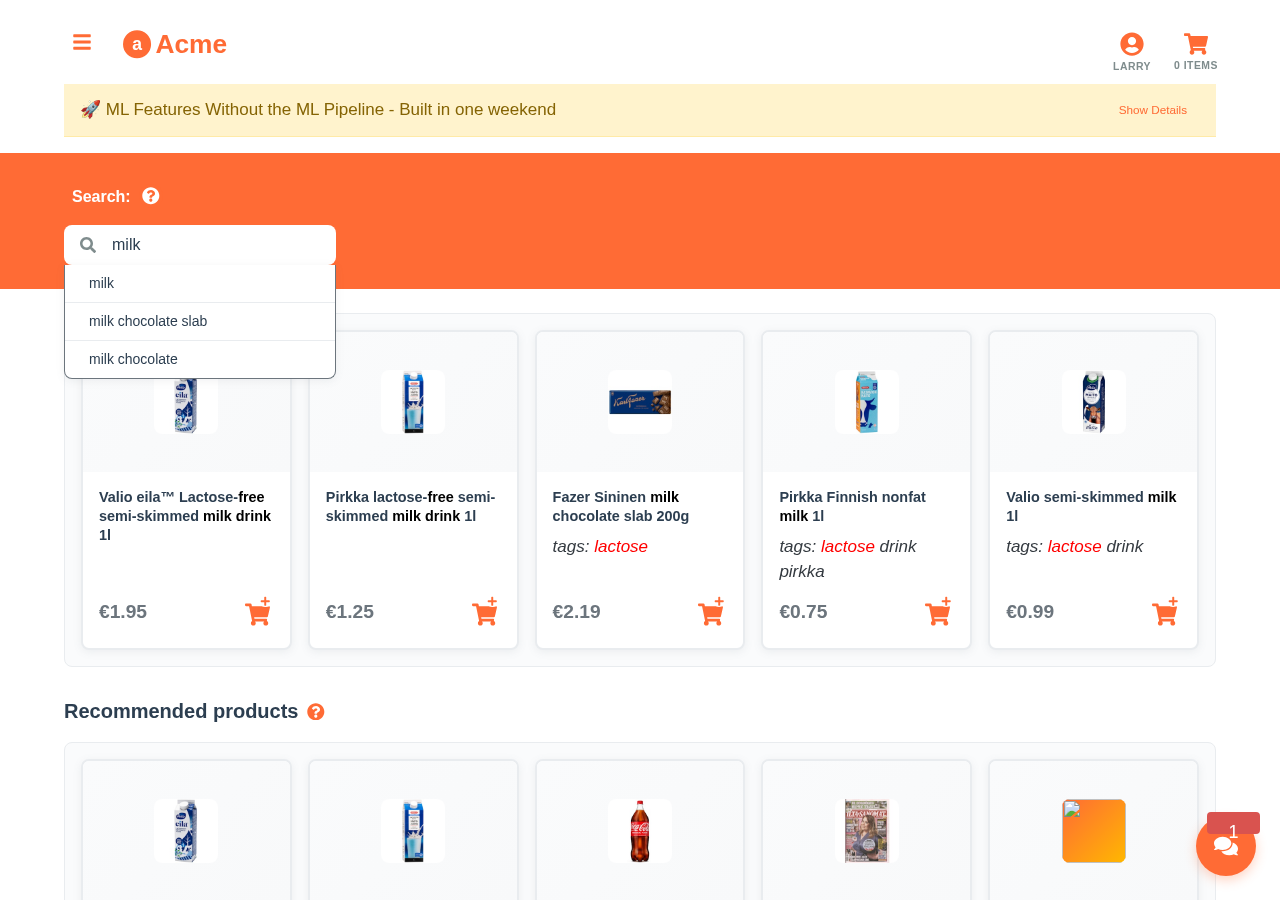
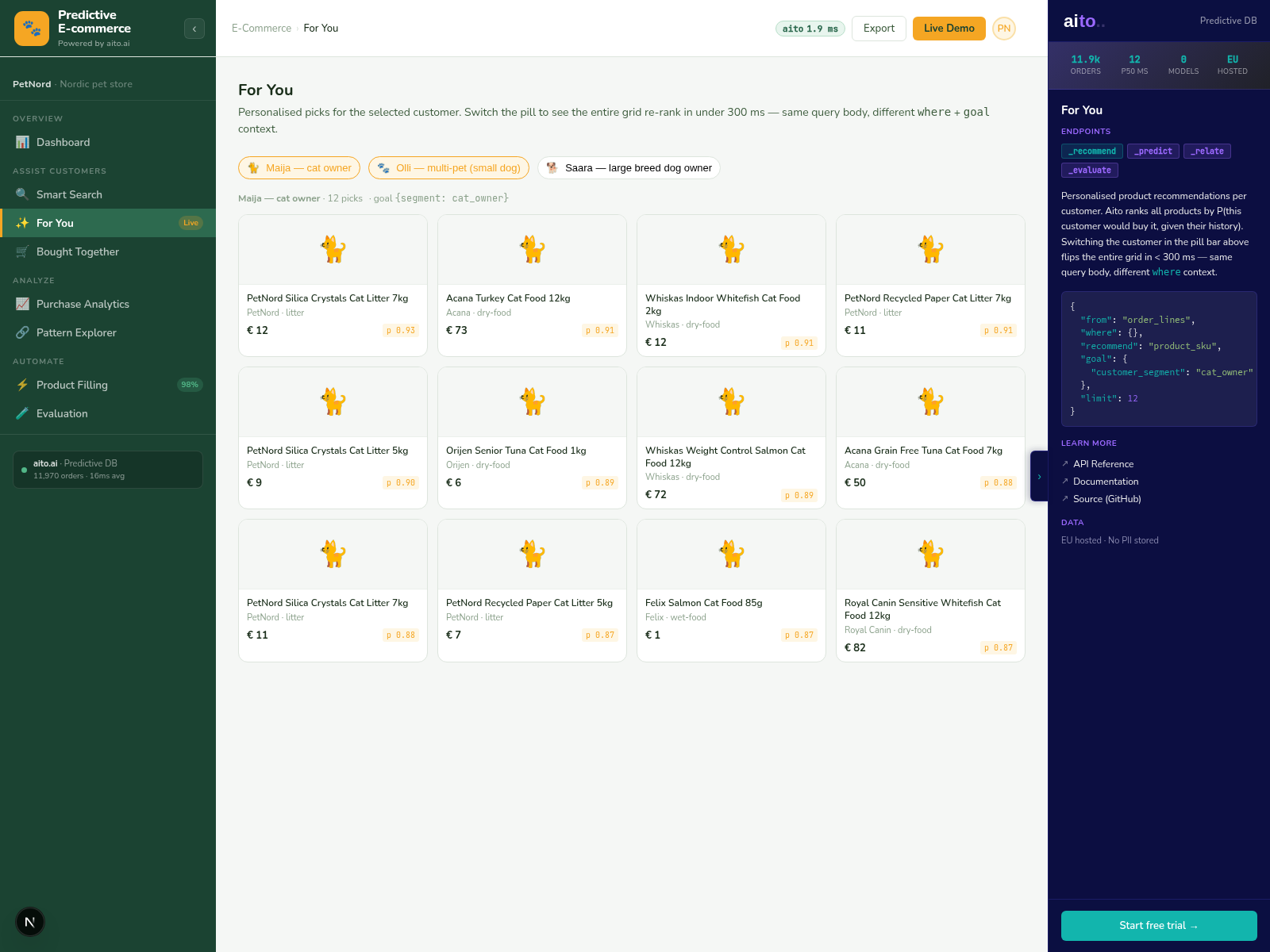
The persona-conditioned ranking is the differentiator that matters for conversion. A search for "milk" from a lactose-intolerant customer should return lactose-free milk first. A search for "shampoo" from a parent should return family-size bottles. A search for "router" in a small-office segment should return SMB-grade hardware, not consumer wifi. The data has the answer — purchase history, browse history, segment membership — but most search stacks do not have a clean way to use it.
Smart Search adds the conditional ranking layer on top of the keyword match. The retrieval is still fast and scalable; the ordering of the results is conditioned on what the system has learned about this user.
How it works
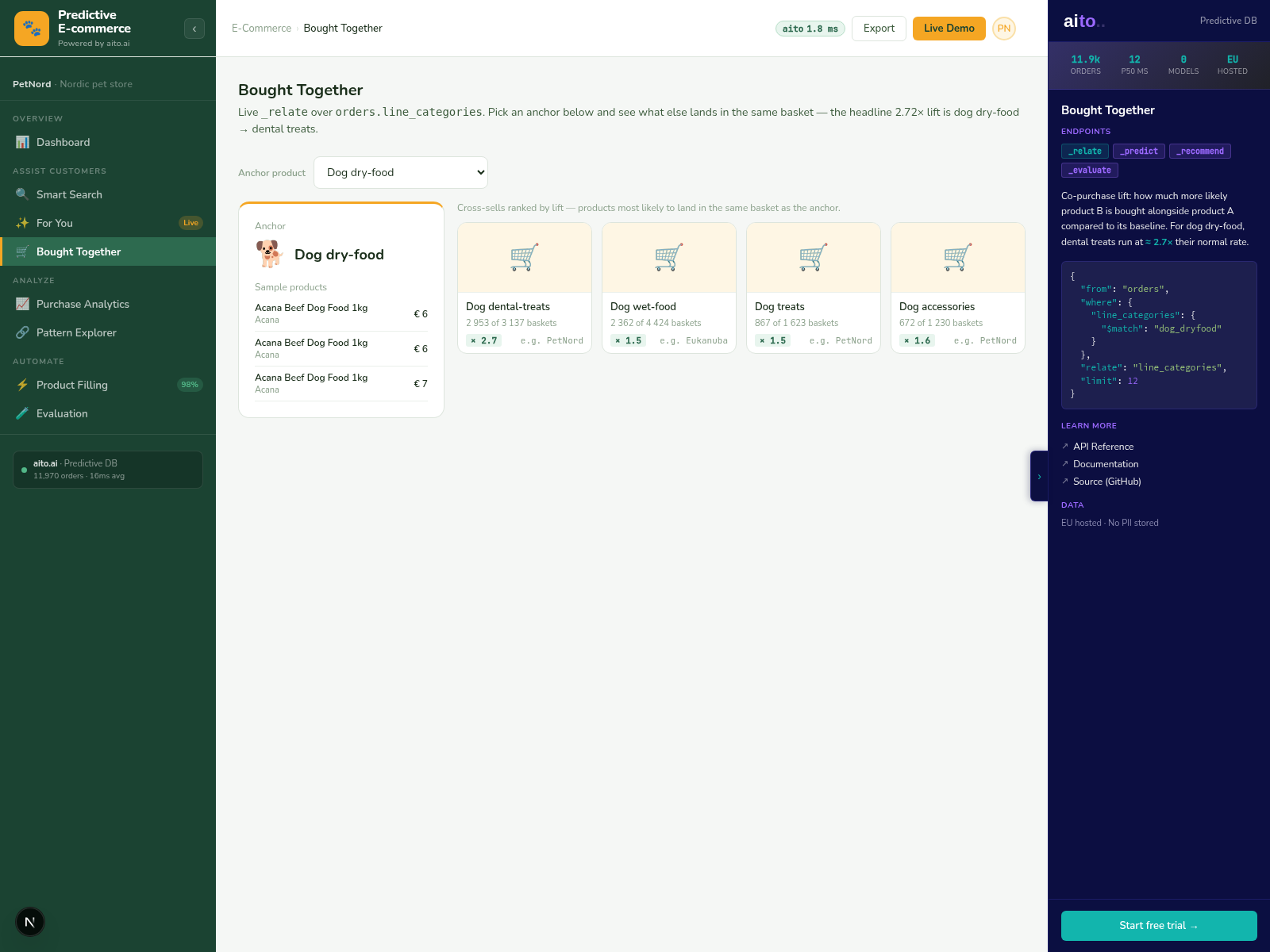
Aito's _search operator returns text-matched results; _recommend returns the same set ranked by user-conditional probability. Smart Search runs both together: retrieve by keyword match, re-rank by the conditional probability that this segment of users will click or purchase each result. The two operators compose in a single query.
The re-ranking signal is not a curated rule. It is the same conditional probability that drives prediction elsewhere — P(click | search_term, user_segment). The system learns from impressions and clicks; high-CTR results for a segment rise; low-CTR results sink. New products without history default to the keyword ranking until enough impressions accumulate for the conditional probability to take over.
{
"from": "impressions",
"where": {
"customer": "alice@example.com",
"product.text": { "$match": "milk" }
},
"recommend": "product",
"goal": { "click": true },
"limit": 10
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛒 E-commerce demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to Algolia + a separate personalization layer?
Algolia and similar tools do the retrieval brilliantly; the personalization is usually added with a separate ranking model that the team has to train and maintain. Smart Search collapses retrieval and personalization into one query — no separate model, no separate pipeline. On raw text-matching, Algolia is often faster; on the combined task of retrieval plus personalized ranking, the consolidated query is cleaner and the personalization is calibrated.
What about new visitors with no history?
New visitors fall back to the keyword ranking until enough impressions accumulate to estimate their segment. After 3-5 impressions, the system can usually place the visitor in a behavioral segment and the conditional ranking begins to apply. Cold-start visitors get the keyword-only ranking — the system honestly says it does not have enough signal yet.
How quickly does the re-ranking adapt to new patterns?
Every impression and click enters the index immediately; the next query reflects it. No retraining schedule, no batch update. Seasonal patterns, trend shifts, new product launches — all visible in the ranking within seconds of the supporting data being recorded.
Can we control the balance between text-match relevance and personalization?
Yes. The query lets you weight keyword match vs. user-conditional ranking. A pure keyword query returns text-match order; a pure recommend query returns user-conditional order without text constraints; the combined query interpolates. Most production deployments weight 60-70% toward keyword match (relevance) and 30-40% toward personalization (ranking refinement).
Does this work for catalog search inside enterprise SaaS (not just e-commerce)?
Yes. The pattern is "retrieve text matches, re-rank by user-conditional probability." It applies anywhere a user searches a catalog — knowledge bases, ticket systems, document repositories, partner directories. The retrieval is the same; the conditional ranking differs by what "preferred result" means in each domain.