The problem
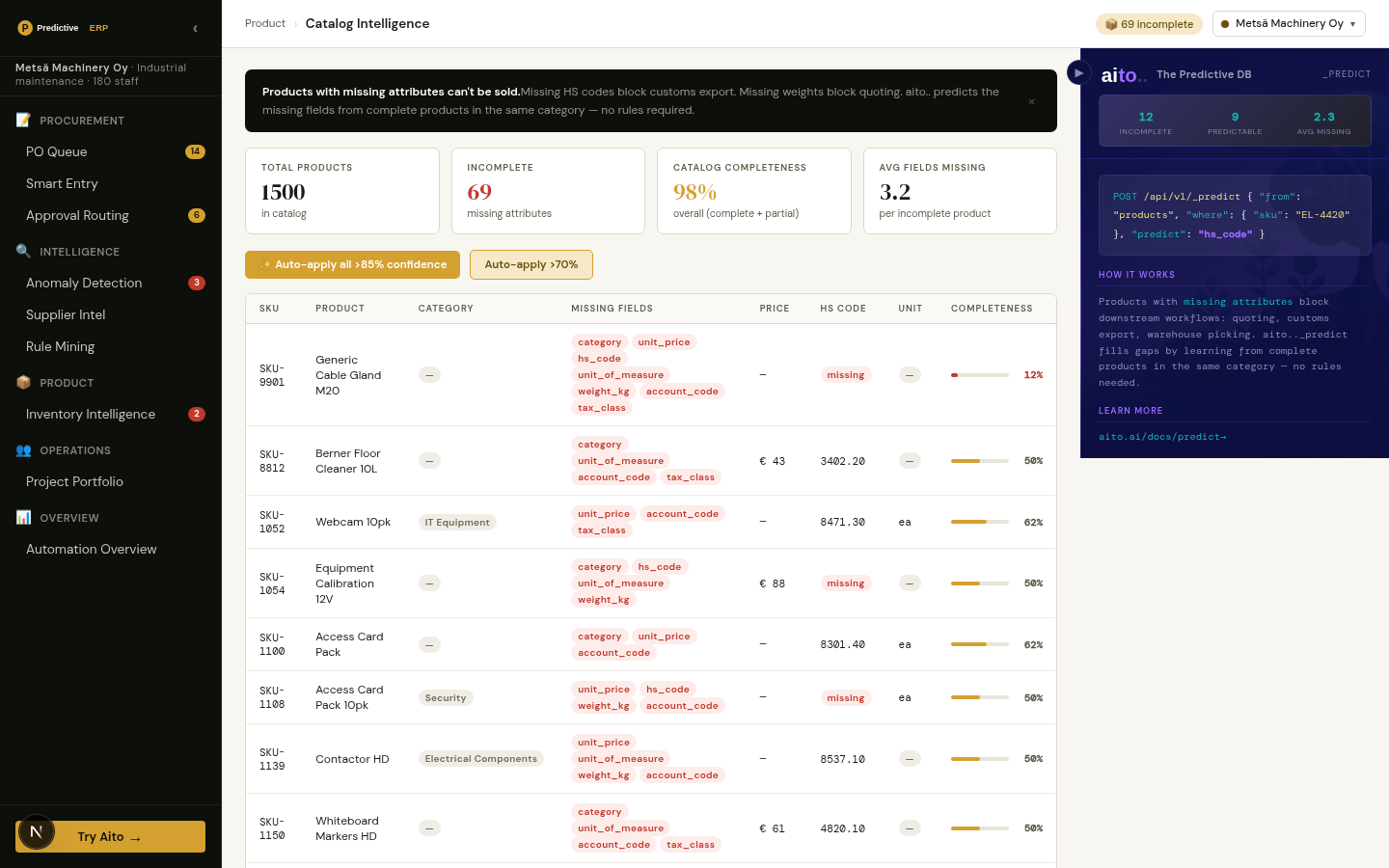
New product onboarding into an e-commerce catalog is the slowest part of catalog management. The buyer accepts a new product from a supplier; the supplier provides the title and a partial attribute set; the catalog team manually fills in the rest — category, dietary tags, weight, dimensions, similar-product cross-references. Multiplied across hundreds of new SKUs per quarter, the cost compounds.
The attributes the team is filling in by hand are predictable from the title, the supplier, the partial attributes, and similar existing products. The supplier+title combination strongly predicts the category; the category strongly predicts the dietary tag patterns; the title strongly predicts the weight class. The data already contains the answer for most fields.
How it works
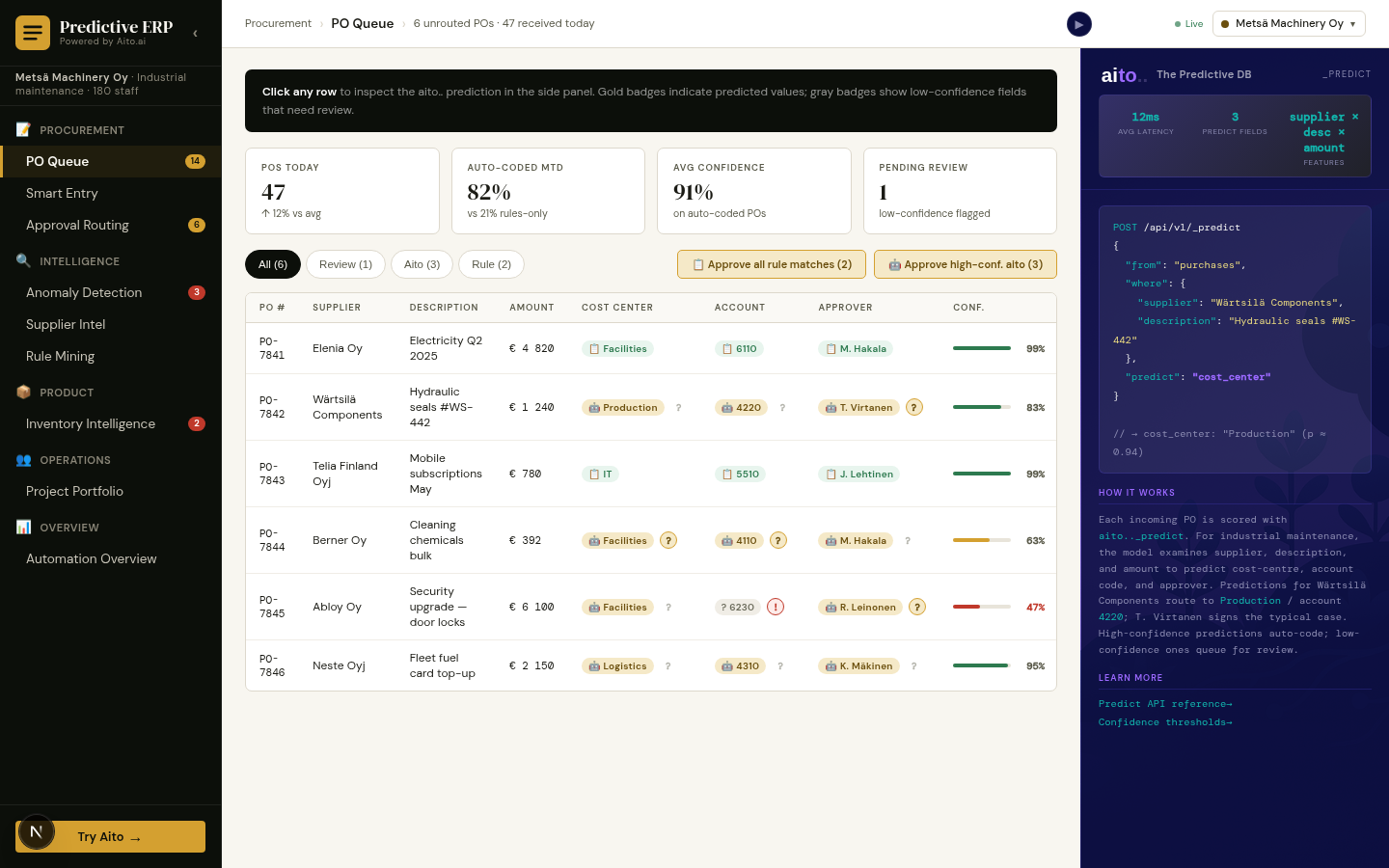
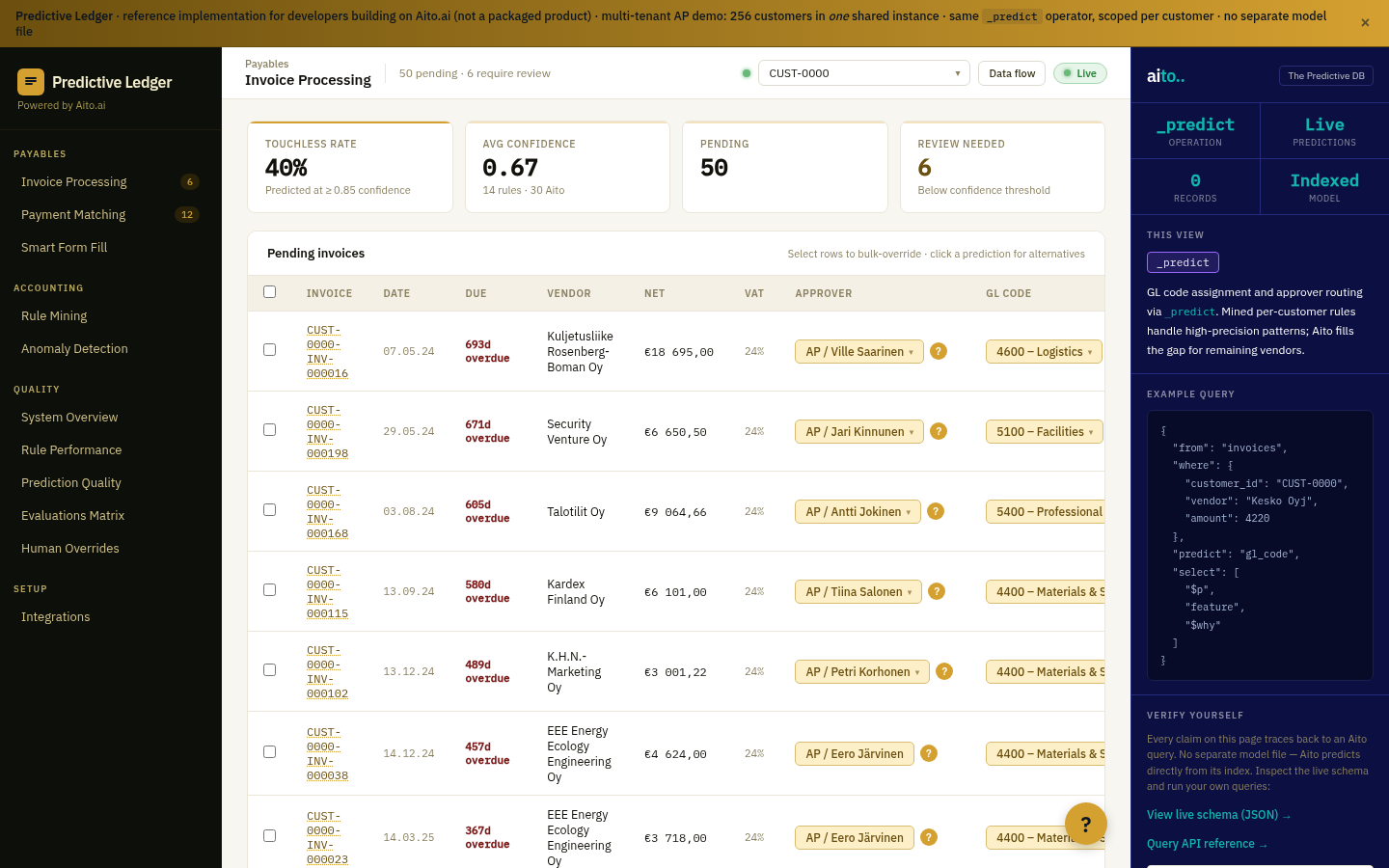
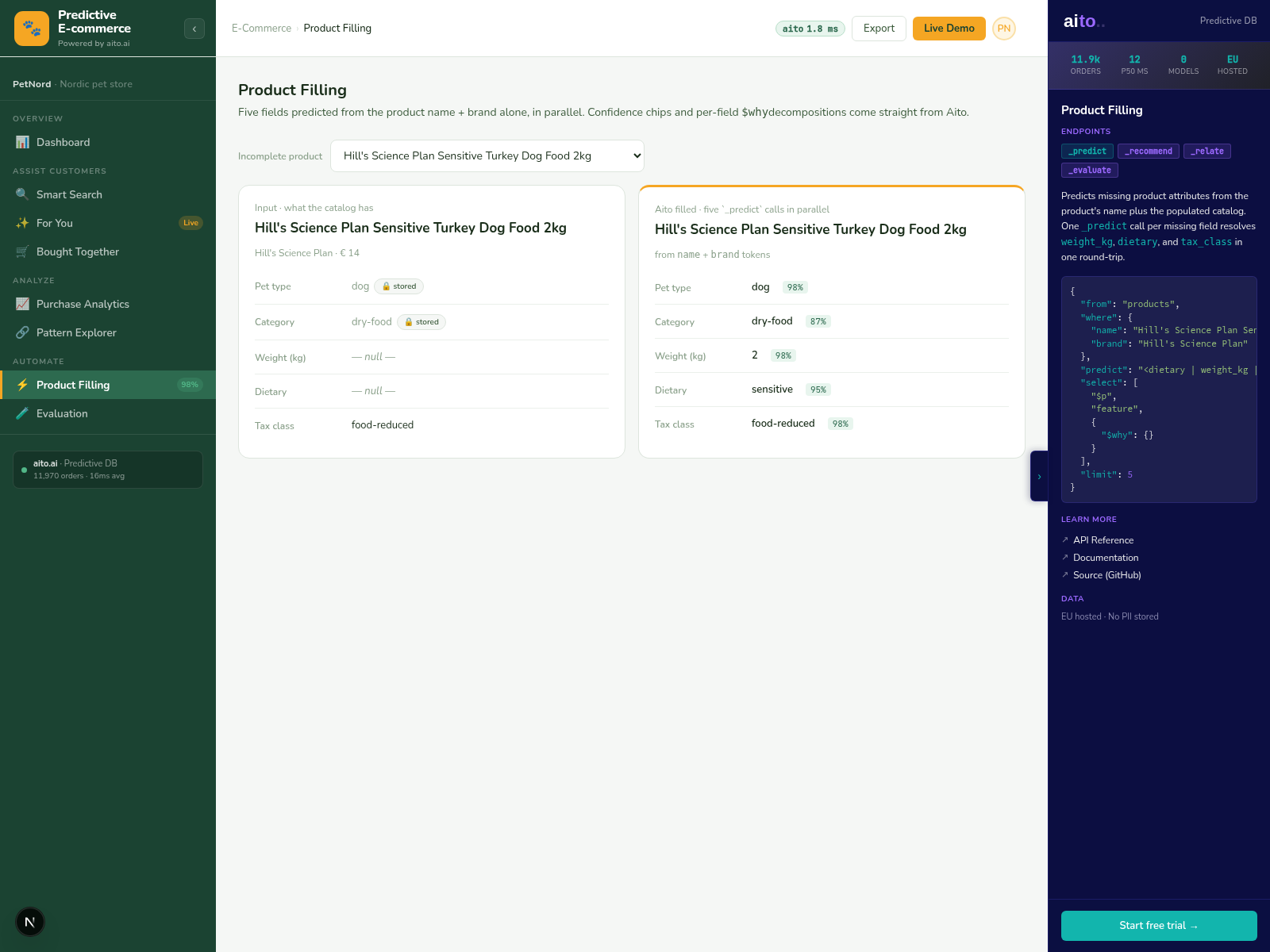
Product Filling is multi-field _predict on the products table. Given the supplier, the title, and any provided attributes, predict the remaining attributes — category, dietary tags, weight, dimensions, brand. Each field returns its own confidence; high-confidence fields auto-fill, mid-tier surface as suggestions, low-tier stay empty for human attention.
The pattern is identical to catalog gap-fill applied to new products at intake. The form variant runs at supplier-feed import; the team reviews the predicted attributes per SKU and approves or overrides. Overrides flow back as training signal; the next batch of similar SKUs gets higher confidence on the same attributes.
{
"from": "products",
"where": {
"supplier": "PetFood Nordic",
"title": "Premium grain-free dry food 2kg"
},
"predict": ["category", "dietary_tags", "weight_kg", "price_range"],
"select": ["$p", "$why"],
"limit": 1
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛒 E-commerce demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
What if the supplier feed contains structured attributes — is the prediction still useful?
Use supplier data where present; predict where missing. Most supplier feeds provide 40-70% of fields; product filling handles the remaining 30-60%. The two compose: structured data first, prediction for the gaps, human review for high-stakes fields.
How accurate is product filling on a genuinely new product category?
New categories get low confidence — the system has nothing comparable. Manual entry seeds the category; after 3-5 SKUs in the new category, the prediction stabilises for subsequent SKUs in the same category. The first few SKUs do the work; the rest auto-fill.
Can the prediction generate product descriptions (free text)?
Free-text generation is the LLM's job. Predicted attribute values feed an LLM that drafts a description; the human reviews. The split: predictive database for structured attributes, LLM for the prose.
How does this integrate with PIM (Akeneo, Salsify, inRiver)?
Aito returns predictions as JSON; the PIM consumes them as suggested values per attribute. The PIM's existing review-and-approve workflow stays in place; the prediction layer slots in as a default-value provider.
Does this work for B2B catalog onboarding (industrial parts, software products)?
Yes. The pattern is "predict missing fields from available signal." Industrial parts get category and HS code predictions; software products get tier and license-class predictions. The domain differs; the mechanism is the same.