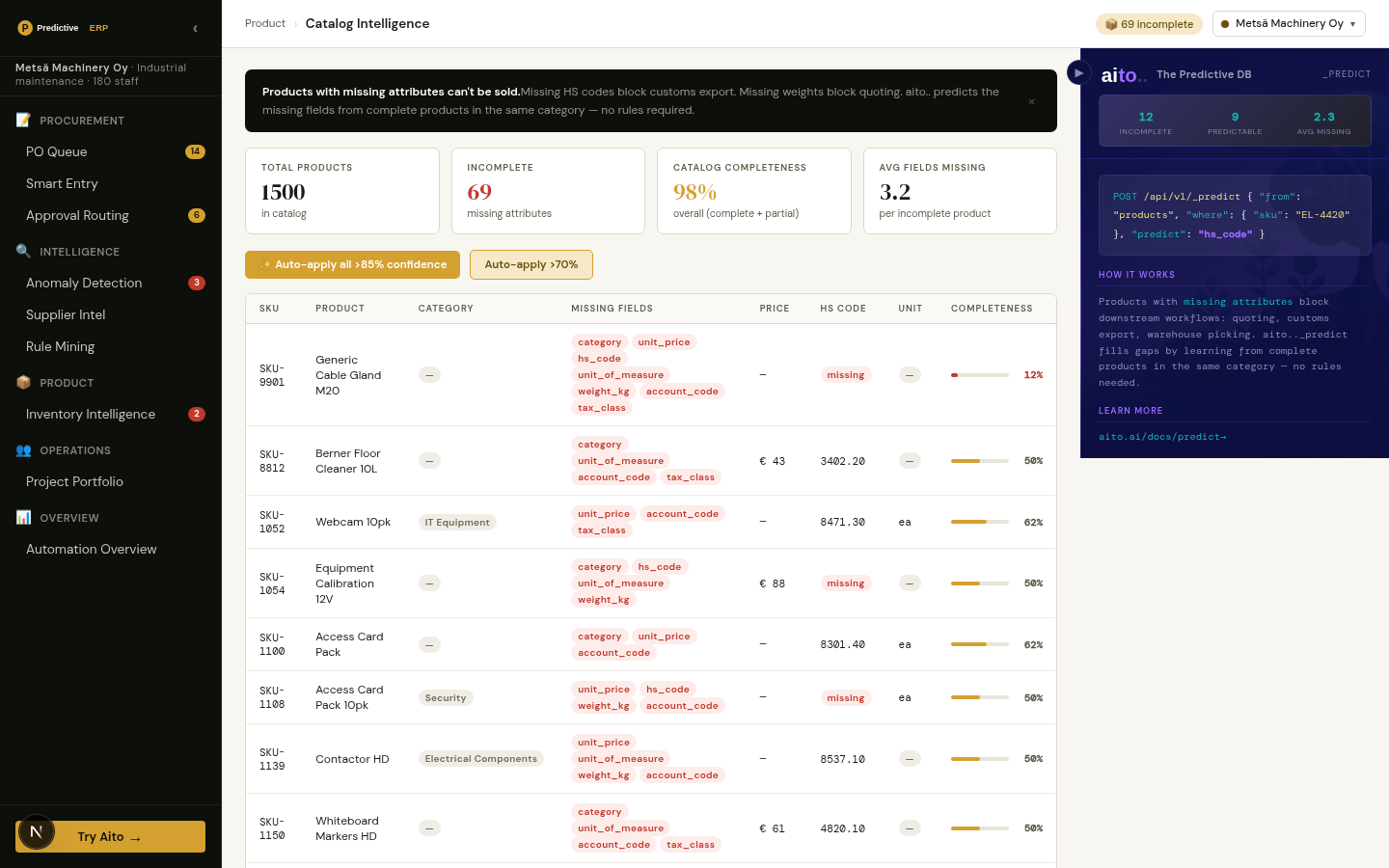
The problem
Product catalogs accumulate gaps over time. New SKUs land without the full attribute set; old SKUs were imported before the current taxonomy existed; vendor-provided data is incomplete in predictable places. The gaps do not matter until they block a workflow — a missing HS code stops international shipping, a missing category breaks faceted search, a missing unit price blocks the PO autoroute.
The team that owns the catalog usually fills the gaps by hand. The same SKU appears in shipments, in similar-product clusters, in supplier feeds — the data to fill the gap exists somewhere, but the human is the one synthesizing it. The cost compounds: every new gap requires the human to be the conditional-probability engine again.
How it works
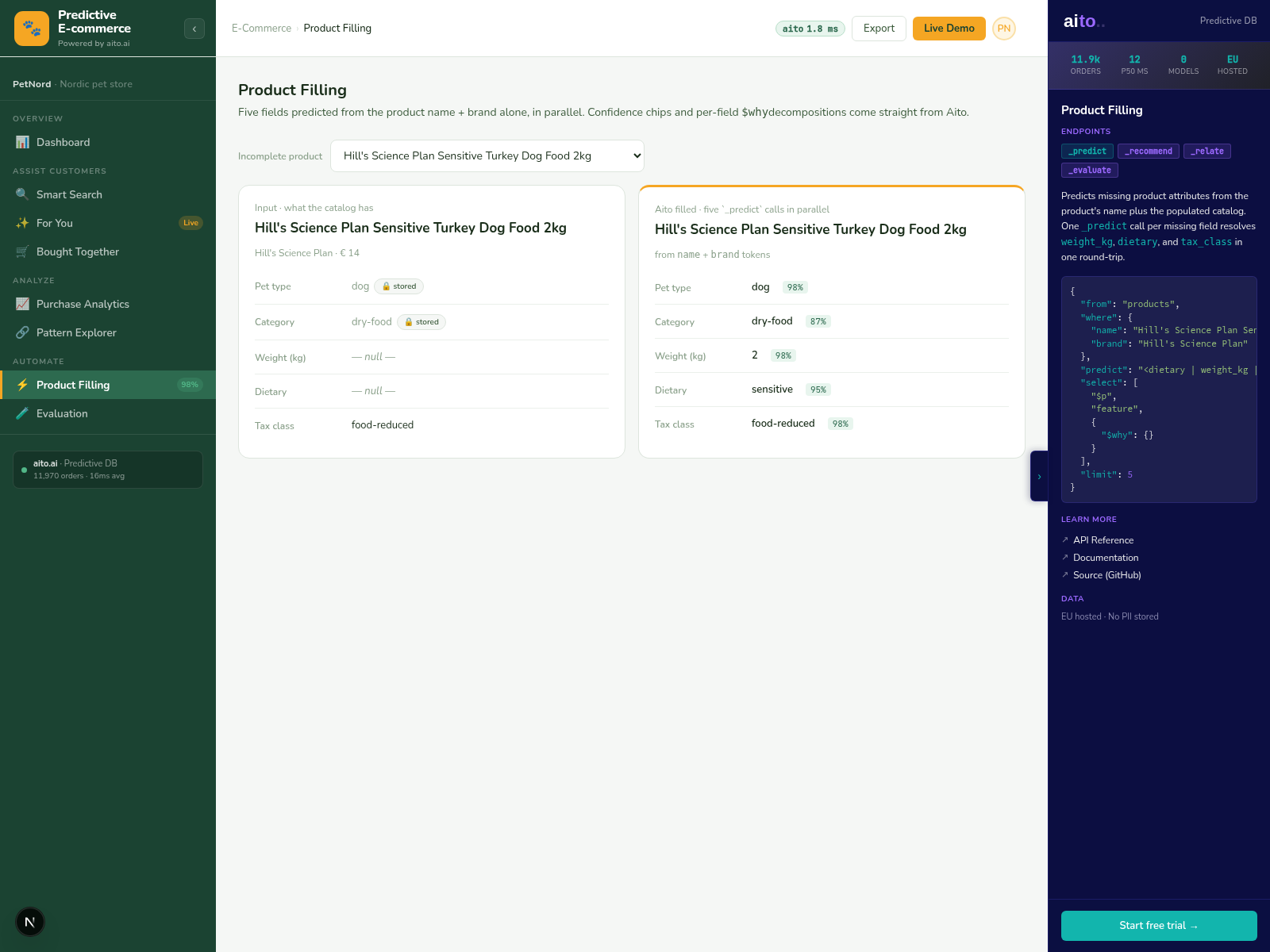
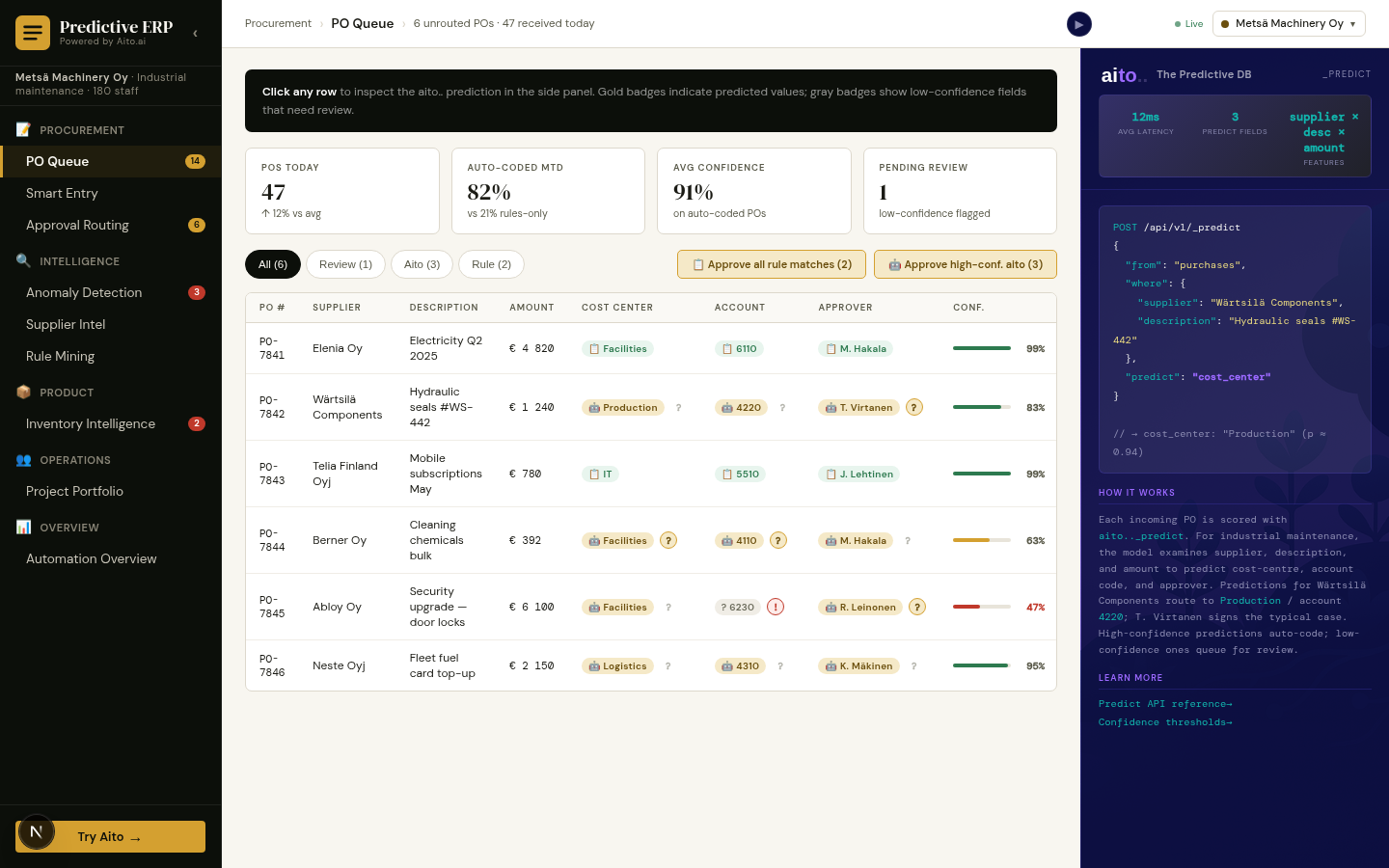
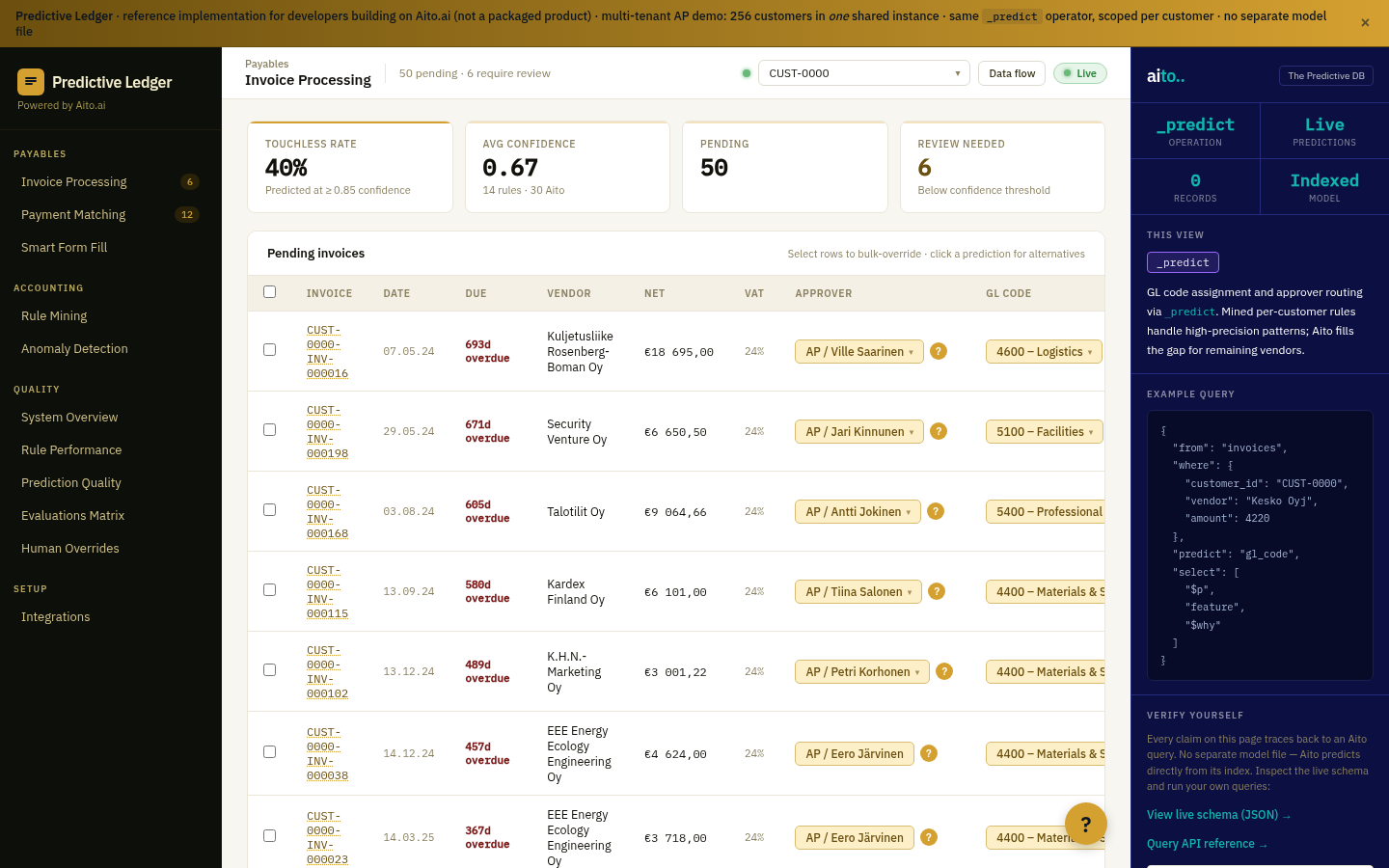
Multi-field gap fill is _predict applied across multiple target columns from the available context. Given the SKU's title, supplier, similar-SKU attributes, and shipment history, predict the missing fields — category, HS code, unit price, weight, dimensions, dietary tags — in one query. Each predicted field has its own confidence; high-confidence fields auto-fill, mid-tier surface as suggestions, low-tier stay empty.
The pattern matches Smart Form Fill but applied to data rather than to input UI. The form variant runs at user-input time; the gap-fill variant runs in batch over the existing catalog. Both use the same query shape — predict the unknown fields conditional on the known fields, with calibrated per-field confidence.
{
"from": "products",
"where": {
"sku": "WIDGET-1042",
"title": "Premium Widget 50ct",
"supplier": "Acme Widgets Oy"
},
"predict": ["category", "hs_code", "unit_price", "weight_kg"],
"select": ["$p", "$why"],
"limit": 1
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 📋 ERP demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this handle products with very little reference data?
Products with few similar siblings get low-confidence predictions. The system honestly says "I do not have enough comparable products to fill this gap" and leaves the field for human input. As similar products accumulate (or as the SKU itself accumulates history), the confidence rises and the field auto-fills.
Can we run this in batch across the entire catalog?
Yes. The query is the same; it just runs against many rows. A typical batch gap-fill on a 50k-SKU catalog runs in tens of minutes and surfaces a ranked list: high-confidence auto-fills, mid-tier suggestions for human review, low-confidence rows that need source-data correction.
What about supplier-provided data — should we trust it or predict?
Trust supplier data first; predict where it is missing. The two compose: supplier data fills 60-80% of fields cleanly, the gap-fill prediction handles the remaining 20-40% where the supplier did not provide. For high-stakes fields (HS code, regulatory categories), the prediction is a suggestion not an auto-fill — humans confirm before commit.
How accurate is this on new product categories that do not exist yet?
Genuinely new categories return low confidence — the system has nothing to compare against. The fields for those products stay empty until either the human creates the category and applies a few examples, or similar enough products accumulate that the system can infer by similarity.
Does this work for service catalogs (not just physical products)?
Yes. The pattern is "predict missing fields from available context" — applicable to service catalogs, project templates, contract types, vendor profiles, anywhere a catalog of records has structured attributes. The threshold tuning differs by domain.