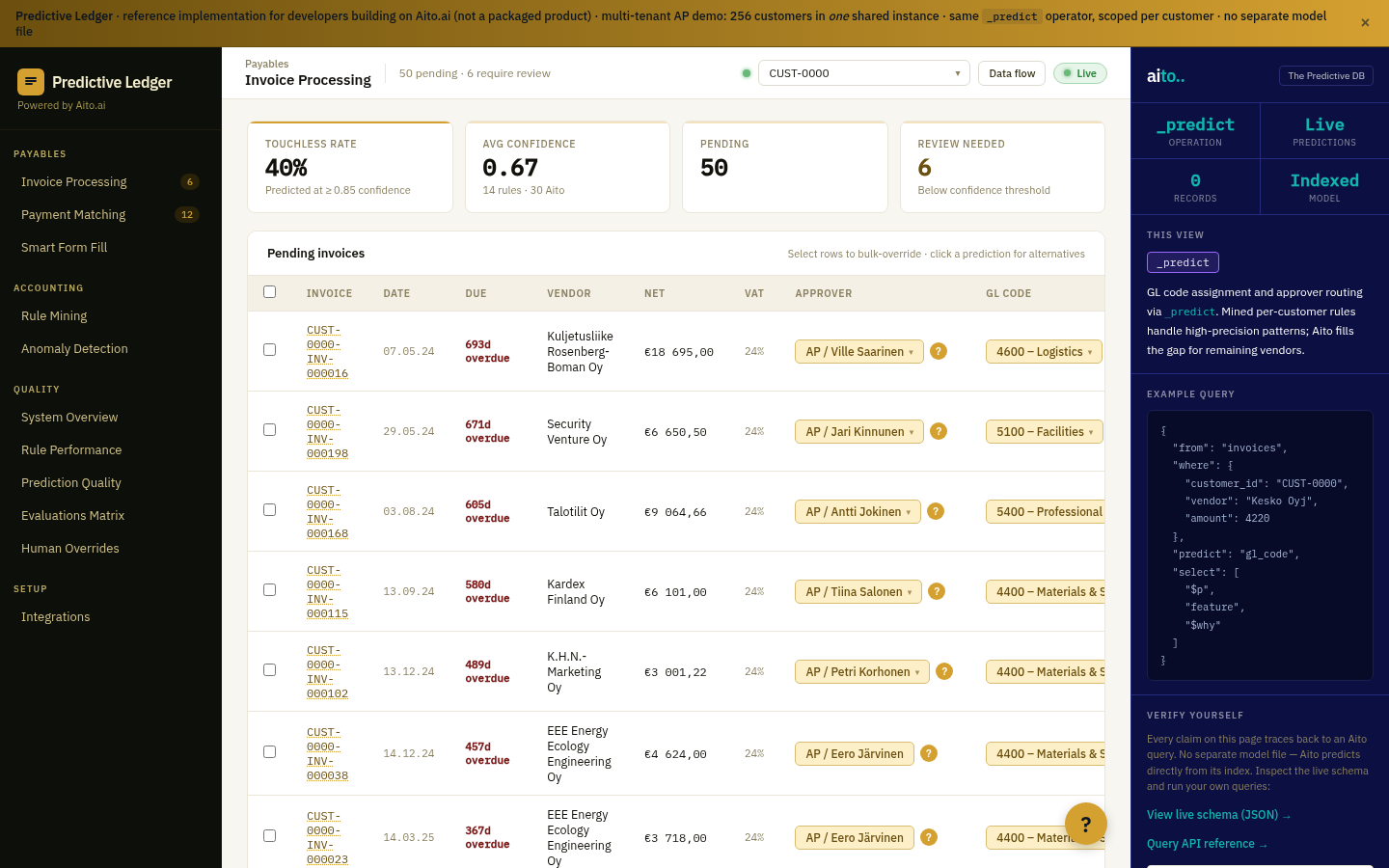
The problem
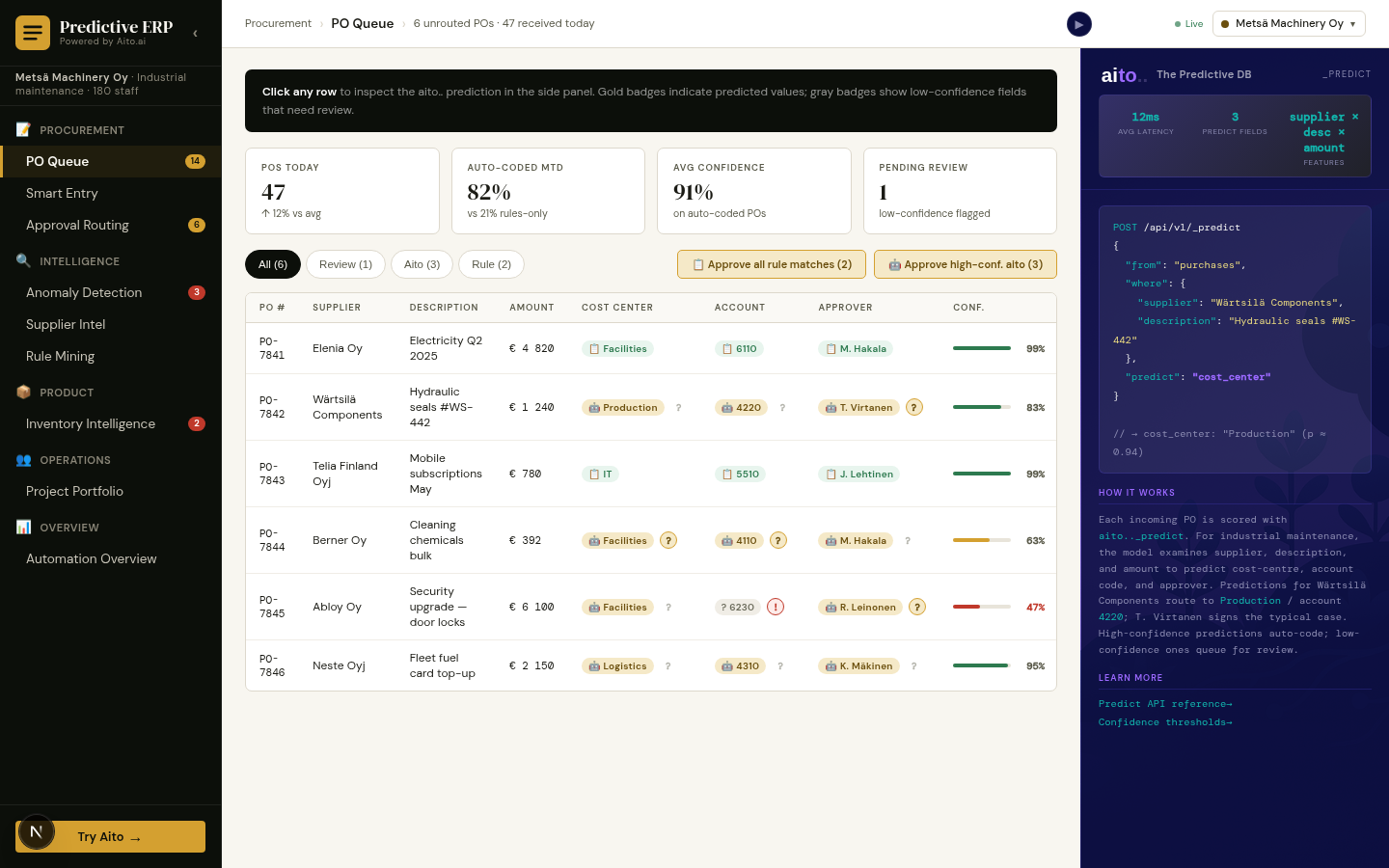
General ledger coding is the load-bearing decision in accounts-payable automation. Every invoice has to be coded to the right account before it posts; misclassified invoices show up in tax filings and in the next quarter's audit. The decision is regular by construction — the GAAP and IFRS consistency principles require companies to apply the same accounting methods consistently from period to period. Same vendor invoicing the same company in two consecutive months should hit the same GL account unless something documented has changed.
That regularity is exactly what makes the decision predictable. The same supplier × category combination maps to the same GL 95%+ of the time on real data. Yet most accounting workflows still ask an AP clerk to read the invoice, glance at the vendor history, and pick from a menu of accounts. The pattern lives in the data; the user is doing the matching by hand.
How it works
The query is a single _predict against the invoices table. Inputs: vendor, category, description, amount, customer_id (in multi-tenant deployments). Output: the predicted GL code, the top-3 alternatives, calibrated probability, and $why factor decomposition.
Automation tiers follow from the probability. Above 95% — auto-post. 50-95% — pre-fill and route to review. Below 50% — leave the field empty, surface as needing human input. The boundary moves naturally as the system accumulates more vendor history; mature deployments hit 60-80% touchless processing on common configurations, and best-in-class teams reach 95%+ on recurring B2B AP (the Posti shape — utilities, telco, scheduled supplier payments).
{
"from": "invoices",
"where": {
"vendor": "Telia Finland Oyj",
"description": "Mobile services Q4",
"amount": 1856.30,
"customer_id": "CUST-0042"
},
"predict": "gl_code",
"select": ["$p", "$why", "gl_code"],
"limit": 3
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🧾 Accounting demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to OCR + rule-based AP automation?
OCR extracts the fields; predictive GL coding decides what to do with them. The two are complementary. OCR + rules typically auto-codes only on rules that you've authored manually; predictive coding handles the long tail of "this combination we haven't seen before but resembles N similar combinations" — the cases rules can't enumerate.
What happens during a chart-of-accounts reorganization?
Chart-of-accounts reorganizations cause a brief drop in account-keyed accuracy after the reorg, then recovery within ~3 observations of the new mapping. The system reflects the new mappings immediately because there's no separate model to retrain — every override is the next prediction's training signal.
Can we audit individual GL coding predictions?
Yes. Every prediction returns $why showing the base probability, the per-feature lift factors, and the highlighted patterns that mattered. Deterministic and reproducible — the same query against the same data returns the same prediction. Auditors get a structured explanation, not a black-box score.
Will the system learn from human overrides?
Yes. When a human overrides a predicted GL, the override is the next prediction's training signal — the new row enters the index immediately. No retraining; no batch jobs; the system reflects the override in the next query against the same vendor pattern.
How accurate is GL coding at low data?
On regular accounting data, three observations of a stable pattern produces ~85-92% confidence with realized error around 1%. By five observations, error rates well under 1% are typical. The top confidence bucket (>95%) carries near-zero realized error in production.