The problem
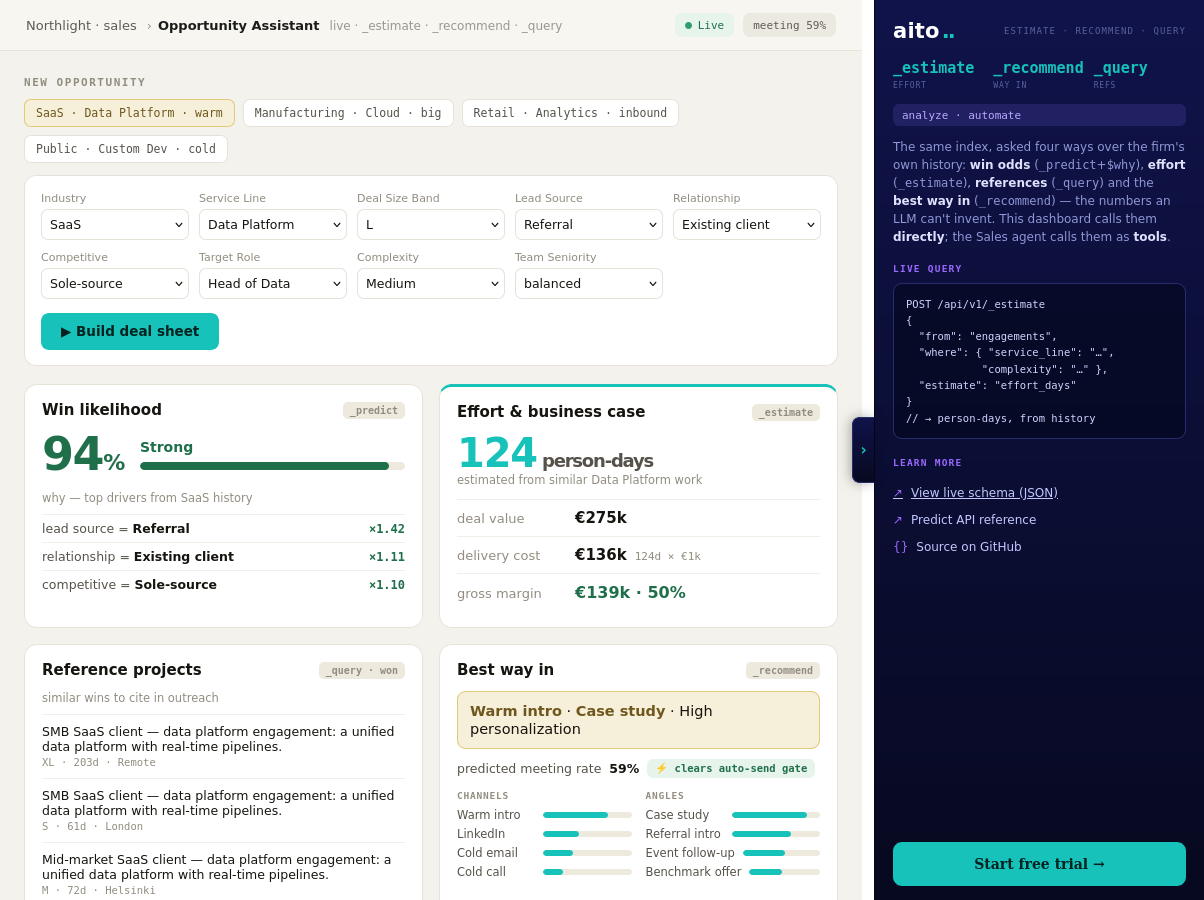
When a new opportunity comes in, the questions are always the same. How likely is this to close? How big is the job? What similar work have we won? Sales answers them with gut feel and whatever the CRM remembers, and an LLM assistant asked the same questions will produce confident numbers it has invented, because it has never seen the firm's deal history.
The history answers all three. Past deals of this shape, from this lead source, with this relationship, closed at a knowable rate. The effort they took is in the records. The references are the won deals that look like this one. The work is conditioning on the right attributes, which is a query, not a model project.
How it works
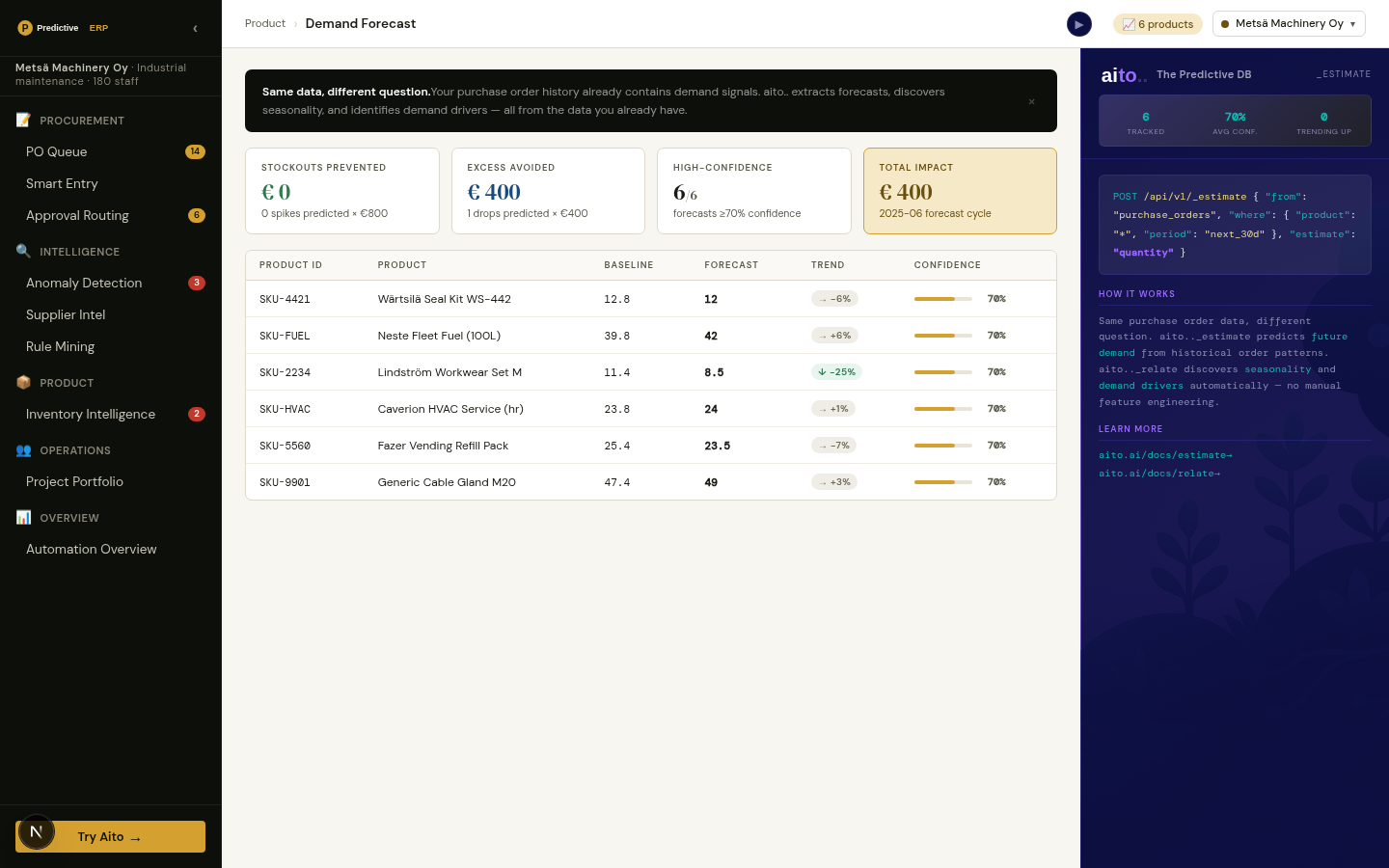
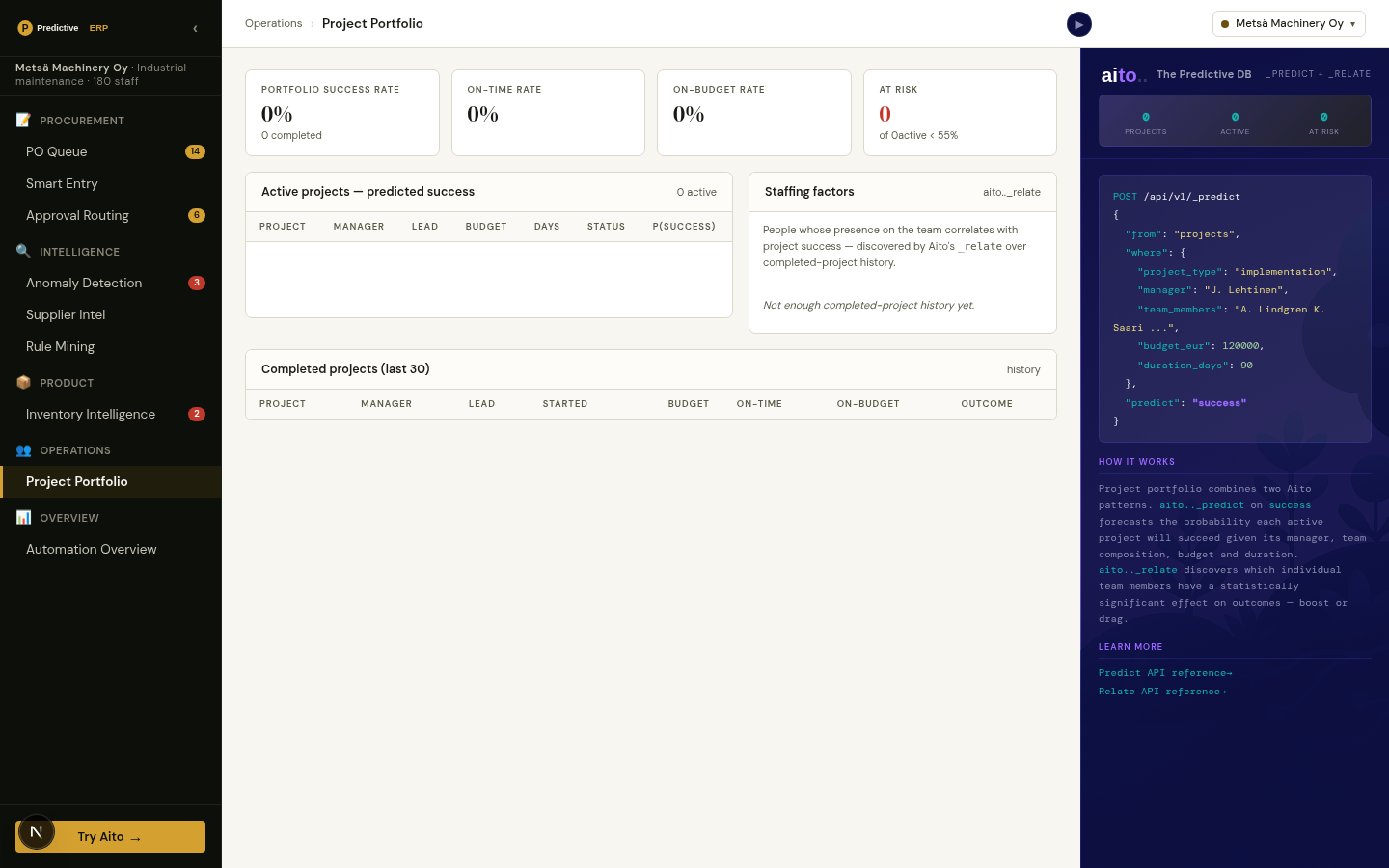
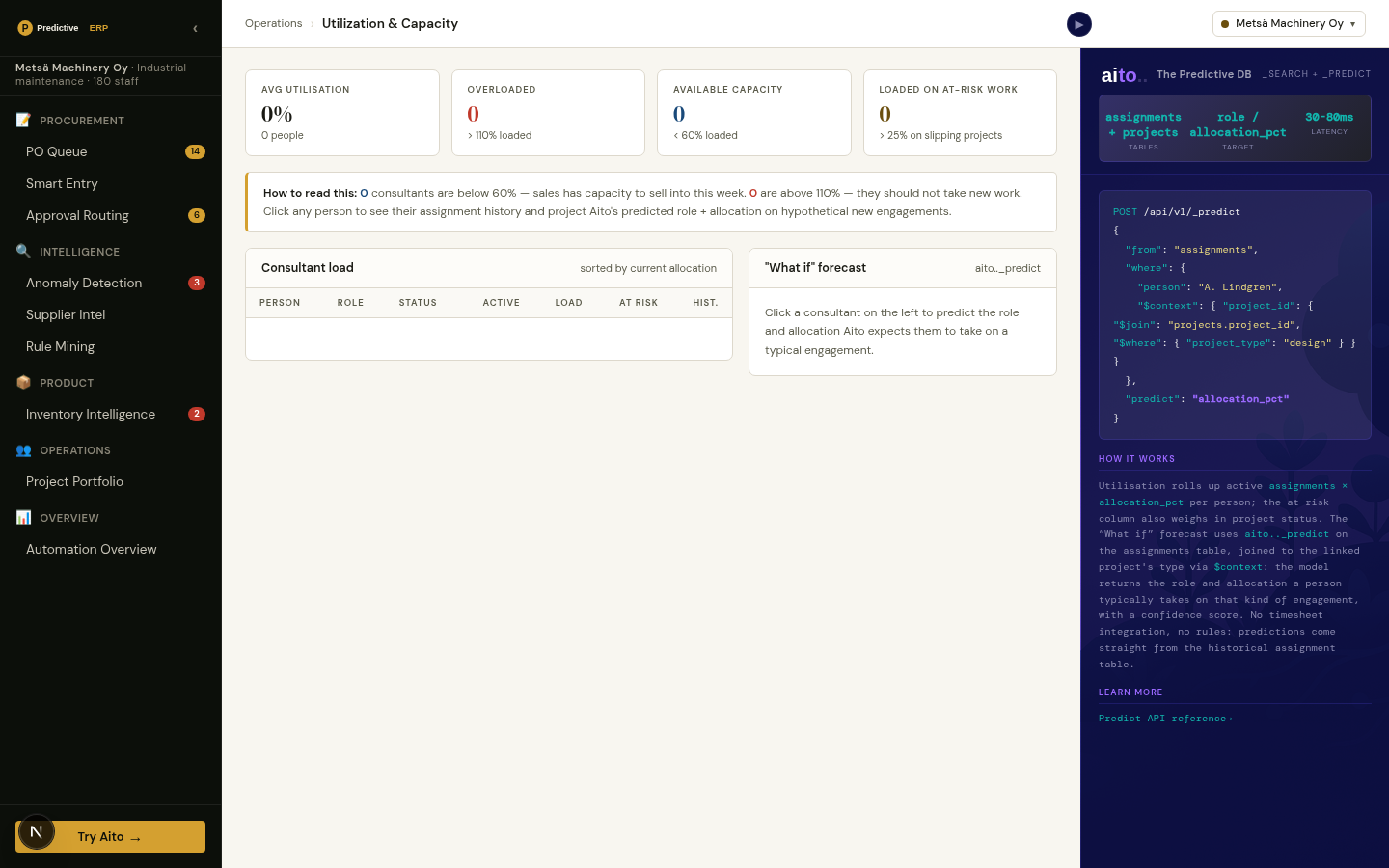
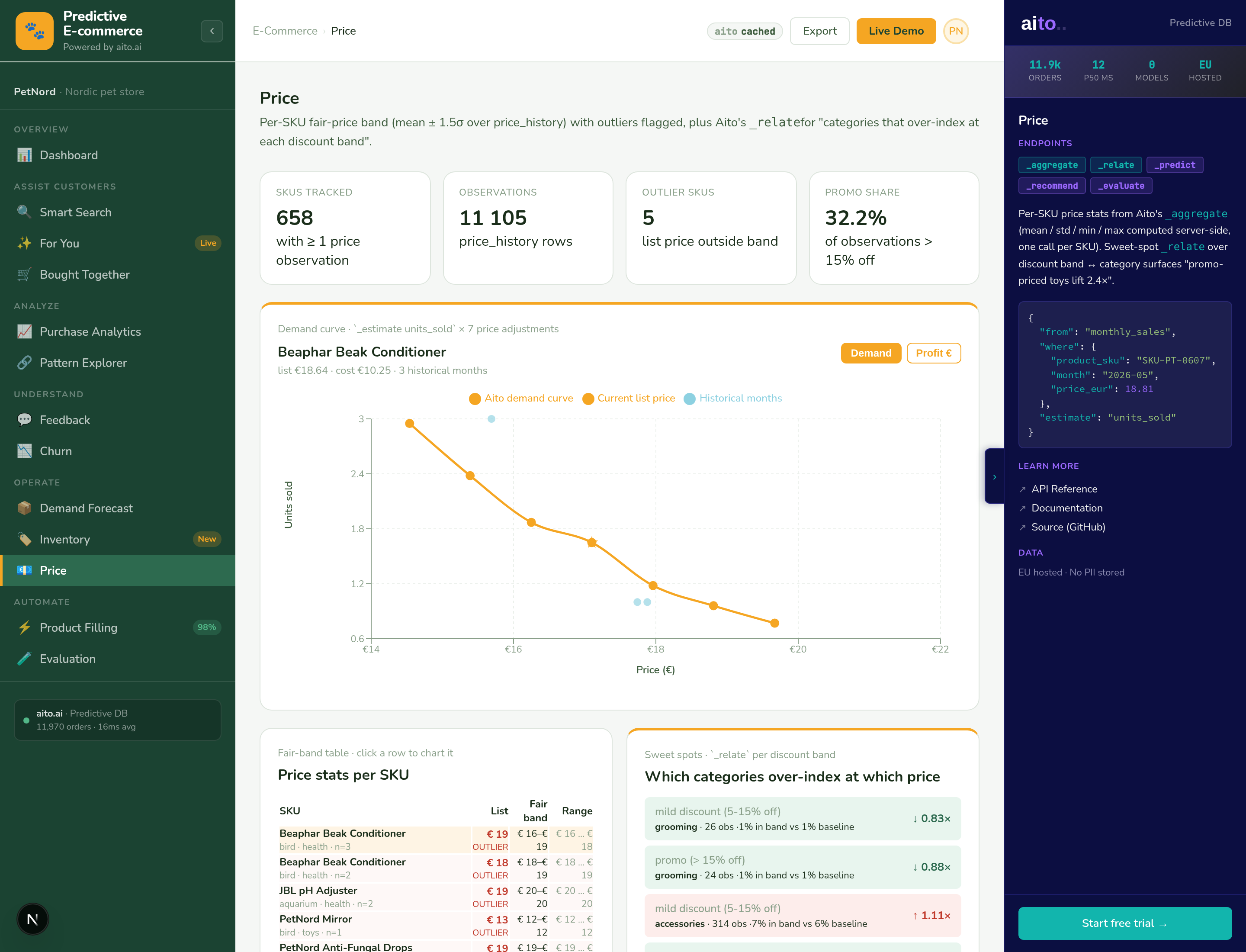
_predict the outcome of the new deal conditioned on its shape (industry, service line, deal size, lead source, relationship) and read the calibrated win probability with the $why drivers behind it. In the live demo a referral from an existing client predicts around 0.92 to close, and switching the lead source to cold outbound drops it sharply, because the history is what conditions the number. _estimate returns the effort in person-days from the same shape, and a query over won deals returns the reference engagements for the proposal.
The same numbers also work as agent tools: the demo's sales agent calls them in chat and quantifies its recommendation against the unoptimised baseline. Every closed deal writes back into the history, so the next score reflects it without any retraining step.
{
"from": "engagements",
"where": {
"client_industry": "SaaS",
"service_line": "Data Platform",
"deal_size_band": "L",
"lead_source": "Referral",
"relationship": "Existing client"
},
"predict": "outcome",
"select": ["$p", "feature", "$why"]
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🤖 Agent demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How is this different from CRM lead scoring?
Most CRM scoring is a hand-tuned point system: +10 for a referral, +5 for the right title. _predict computes the probability from the actual outcome history, calibrated, with the drivers visible in $why. When the market shifts and referrals stop converting, the score follows the data without anyone re-tuning weights.
How much deal history does this need?
Hundreds of closed deals give usable calibration on the common deal shapes; the demo runs on 1,800. Rare shapes return low confidence rather than a made-up number, which is itself the signal to treat the deal as unscored.
Can the same scoring run inside an AI sales assistant?
Yes. The demo's sales agent calls win odds, effort, and references as tools mid-conversation. The LLM handles the dialogue and drafts the email; the numbers come from Aito queries over the firm's history, so the assistant cites grounded figures instead of inventing them.
What about the effort estimate, is that a separate model?
No. _estimate is the same engine returning a number instead of a class: expected effort_days conditioned on the deal shape. One dataset serves the win odds, the effort, and the references, which is the point of querying instead of building per-question models.