The problem
Demand forecasting in an ERP traditionally requires a separate forecasting model: time-series ARIMA, exponential smoothing, or a more sophisticated ML pipeline that someone has to train, deploy, and retrain quarterly. The cost of building that pipeline is what keeps demand forecast as a specialist feature in a corner of the ERP, not an everyday tool. Smaller-scale teams either go without — and overstock or stockout — or buy a separate demand-forecast SaaS that does not integrate cleanly with the operational data already in the ERP.
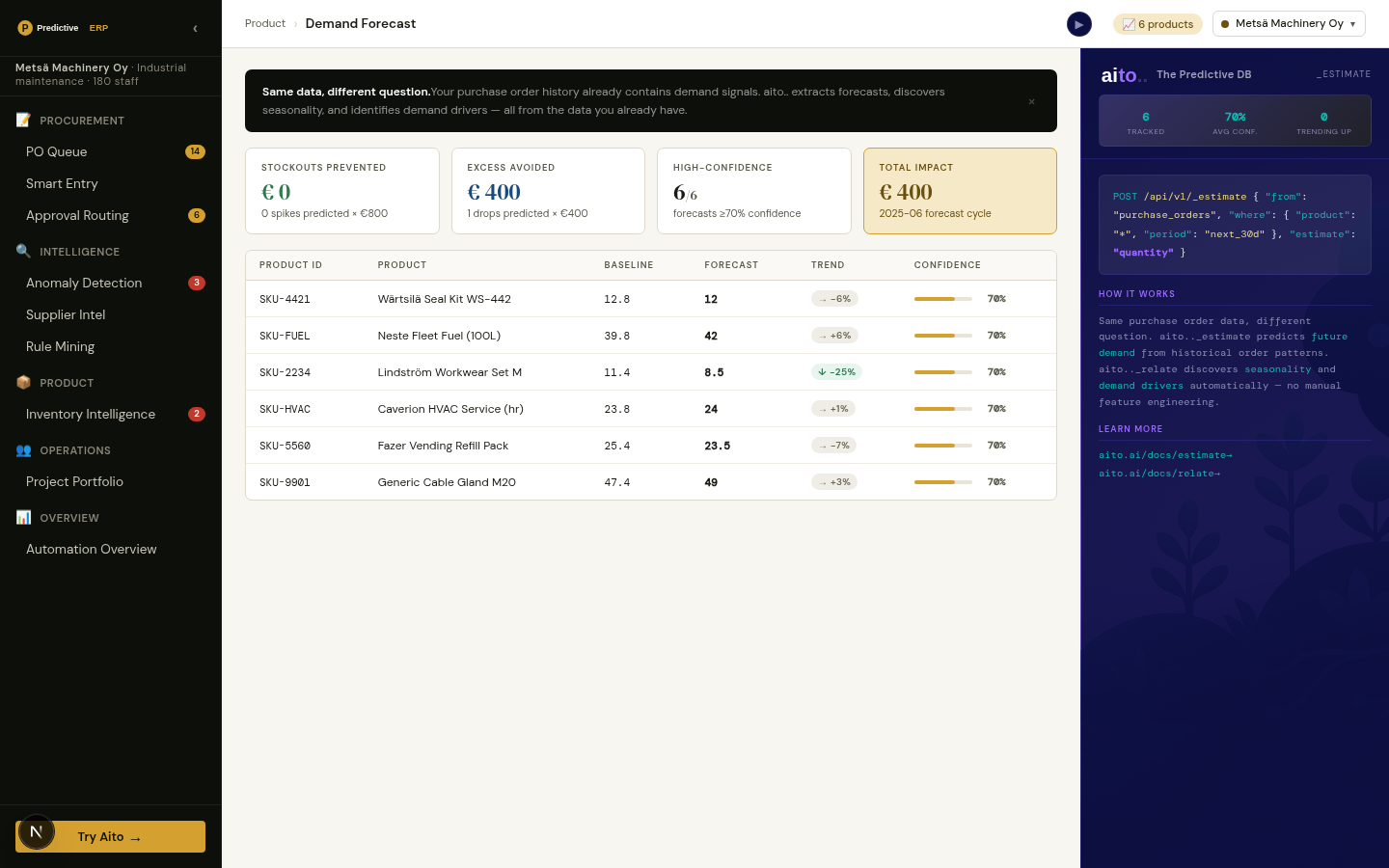
The data the forecast needs is already in the ERP: monthly units_sold history, seasonality, supplier lead times, project pipeline. The conditional structure is there. What is missing is a way to predict units_sold without buying a separate model and retraining it monthly.
How it works
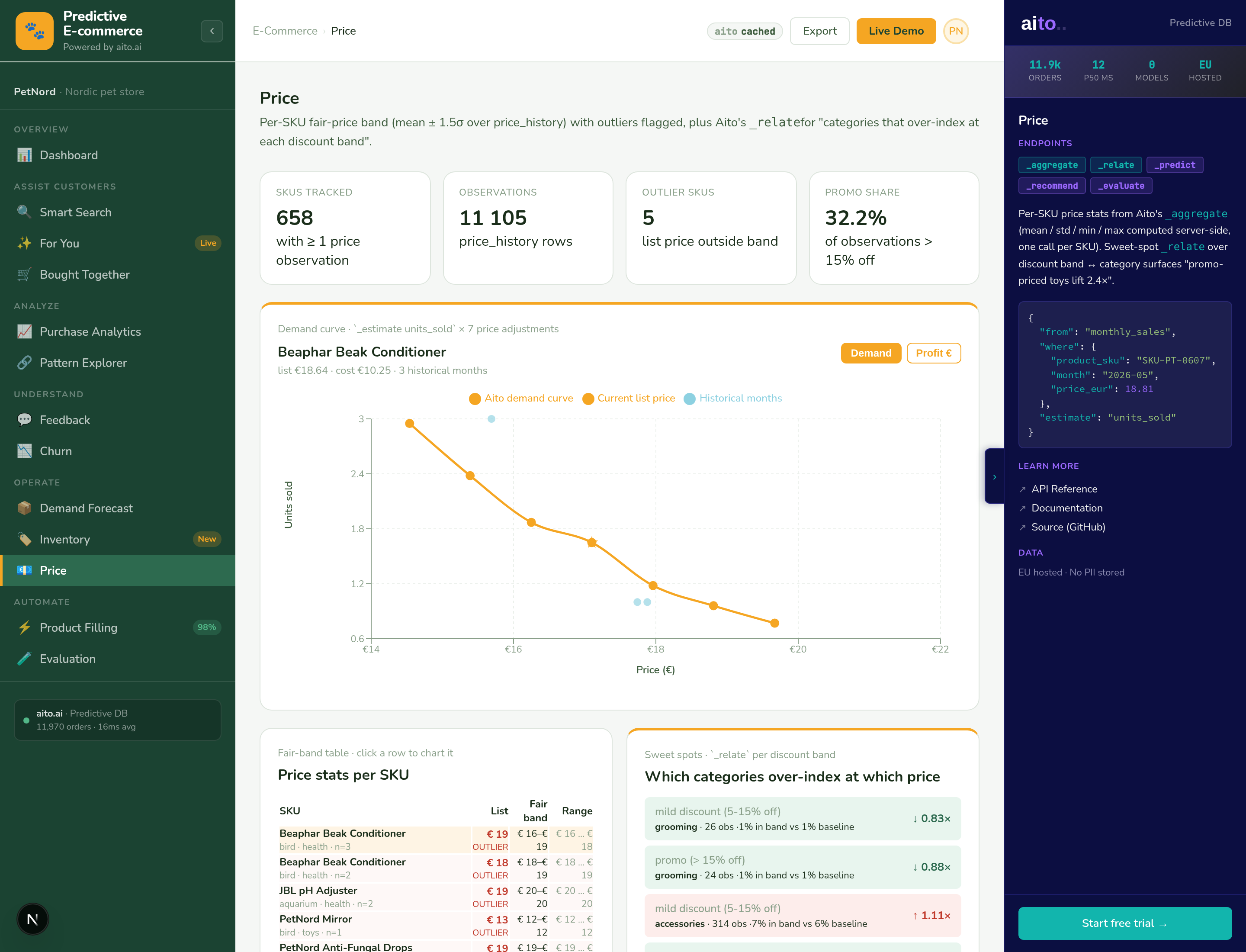
Aito's _predict operator on the orders or sales table returns predicted units_sold conditioned on the SKU, the month, the customer segment, and any other available context. Seasonality factors come from the same-month historical data — there is no separate seasonal decomposition step. The forecast updates live as new orders land; no retraining schedule, no batch job, no quarterly tuning.
Predicted units_sold drives downstream replenishment automatically. The inventory-intelligence view shows days-of-supply, stockout risk, and weekly margin-at-risk by SKU. When predicted demand exceeds current on-hand by the lead-time buffer, the system surfaces a "reorder now" suggestion with the predicted volume.
{
"from": "sales",
"where": {
"sku": "WIDGET-1042",
"month": "2026-08",
"customer_segment": "mid-market"
},
"predict": "units_sold",
"select": ["$p", "$why", "units_sold"]
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 📋 ERP demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to dedicated forecasting tools like Prophet or ARIMA?
Dedicated tools optimize for forecast accuracy on a specific time-series shape. Aito's prediction is more general — it works across SKUs, customers, segments, and projects in a single query. On long stable time-series, dedicated forecasters often have a small accuracy edge; on the long tail of SKUs without dense history, the conditional-probability approach degrades more gracefully than a single tuned model.
What if our demand is project-driven (lumpy, irregular)?
The _predict query conditions on the project pipeline as one of the inputs. Predicted units_sold reflects the projects in flight, not just the historical baseline. For very lumpy demand (one-off engineering builds), the prediction returns low confidence — and the system honestly says it cannot help, which is the right behavior.
How quickly do new SKUs reach useful forecast accuracy?
Three observations of stable demand on the new SKU produces ~85-90% confidence on the conditional probability. For SKUs with similar attributes to existing SKUs, even the first observation can carry useful signal through similarity (_relate). Cold-start on completely novel SKUs follows the same path as any prediction with no history — the system says it doesn't know yet.
Does this support multi-tenant demand forecasting (per-customer SaaS)?
Yes. Add customer_id to the where clause; the conditional probability is computed only over that tenant's rows. Same engine, different forecast per tenant, no per-tenant model. The accounting demo runs 255 simulated customer companies on one shared Aito instance using this exact pattern.
How does latency scale with data volume?
Query latency is sub-200ms at 10M rows in production. The columnar index does the heavy lifting at ingest time; prediction at query time is feature selection plus posterior calculation over indexed statistics — bounded operations regardless of table size.