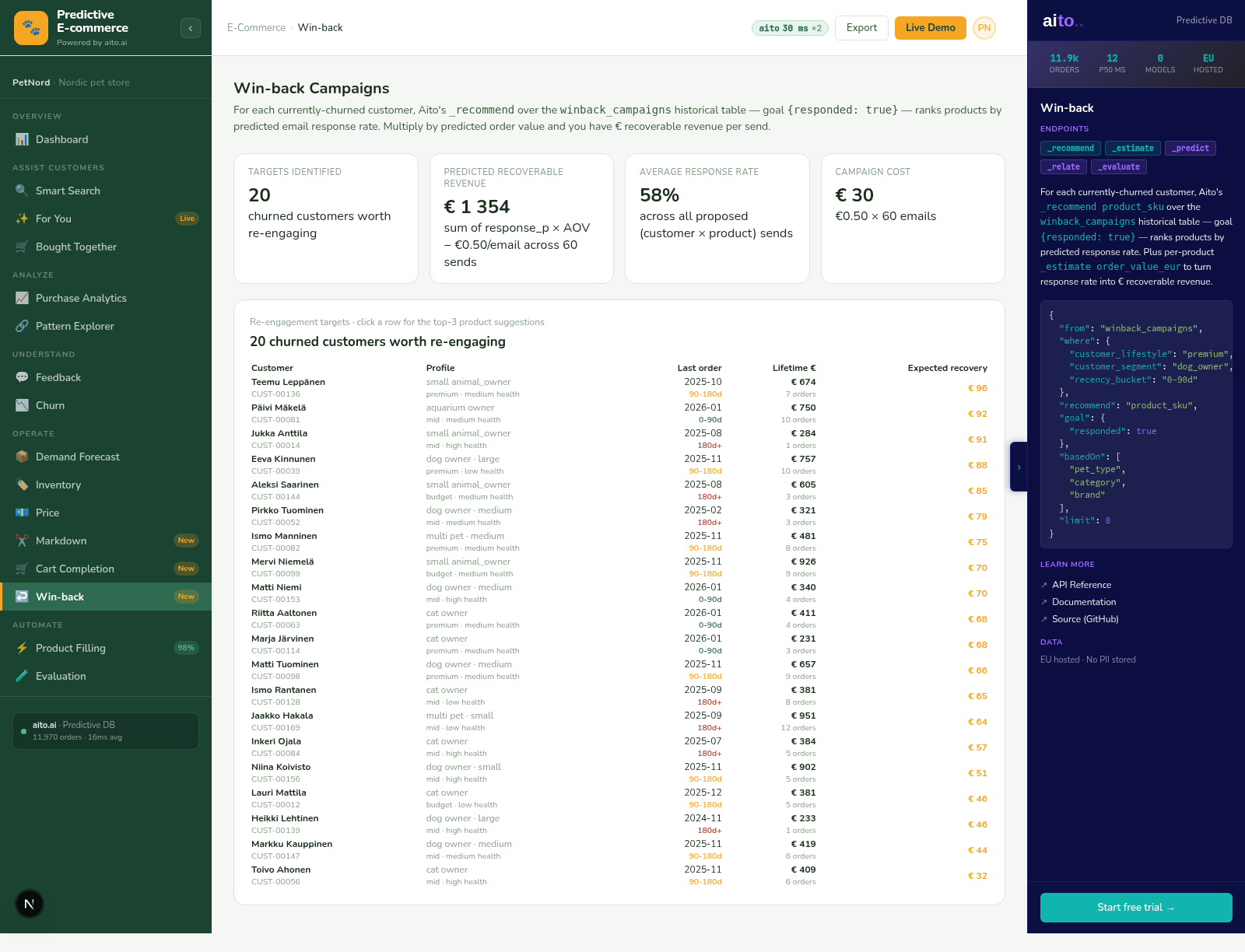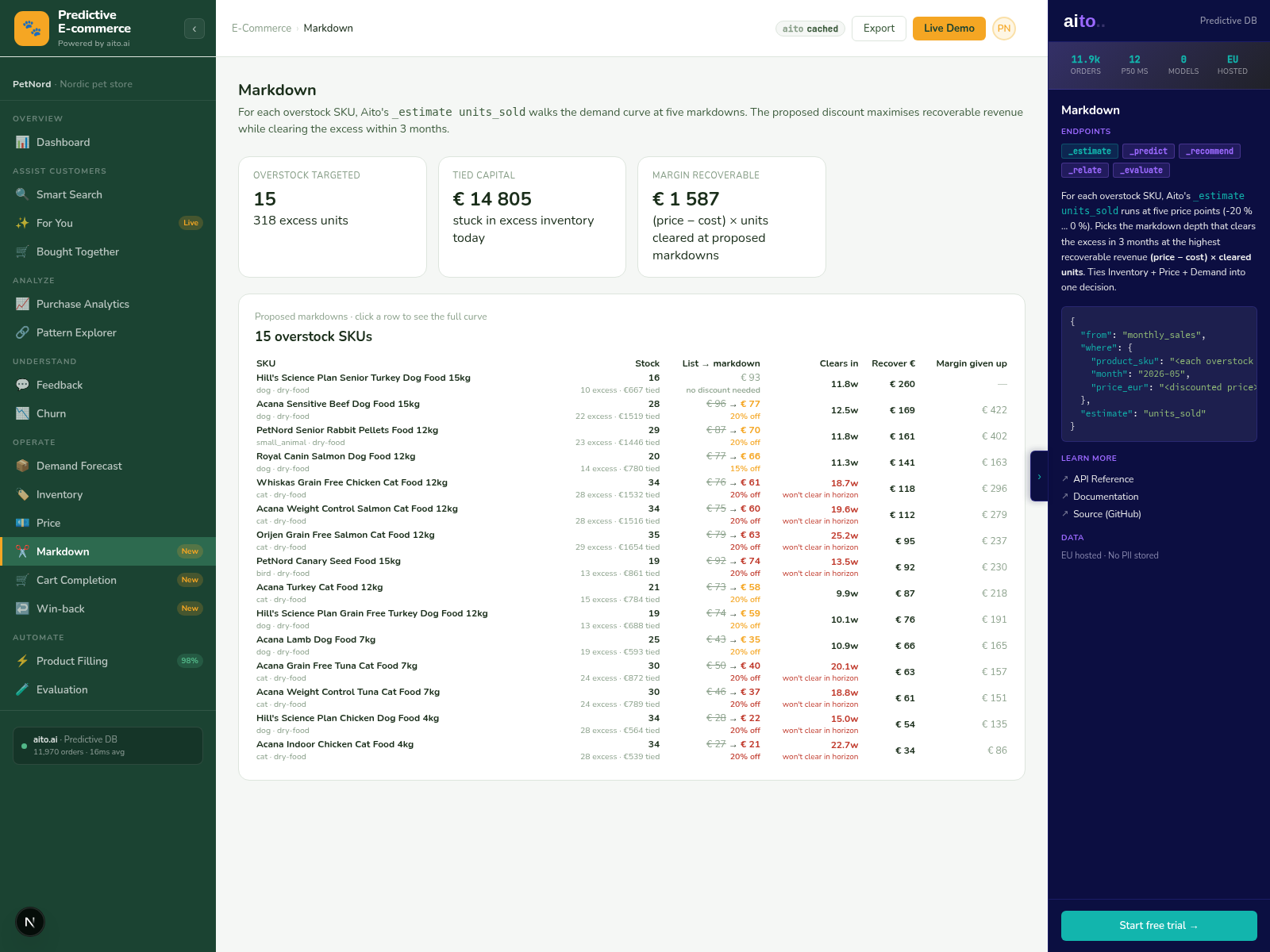
The problem
Markdown decisions in retail are usually made by category managers who watch sell-through rates and intuit when to discount. The intuition is informed by experience but it is not statistical — the manager guesses at the right discount level, posts it, and hopes the recovered demand offsets the margin loss. Half the time the discount is too shallow and inventory still ages out; the other half it is too deep and margin is left on the table.
The data has the answer. Historical markdown events show how demand responded to each discount level for similar SKUs. For a given SKU at a given days-in-stock with a given on-hand quantity, the conditional expected demand at each discount tier is computable from prior events. The right discount is the one where predicted recovered margin × predicted demand exceeds the alternative of holding the inventory at full price.
How it works
_estimate is the operator for "predicted quantity at a query point." Run _estimate across discount levels (5%, 10%, 15%, 20%, 30%, 40%) for a given SKU and customer segment; the result is the predicted demand at each level. Combine with the margin math: estimated_demand × (price minus cost) per discount level. Pick the level where total margin is maximized.
The trigger logic is calibrated. Above a confidence threshold on the predicted demand, the system can auto-post the markdown. Below the threshold, it surfaces the recommendation with the predicted curve for the category manager to override. The threshold tunes the auto-vs-review boundary by category — fashion shifts faster than home goods, so the auto-tier is higher for home goods than for fashion.
{
"from": "markdown_events",
"where": {
"sku": "DRESS-A-LINE-MEDIUM",
"customer_segment": "regular-shopper",
"discount_pct": 20
},
"estimate": "units_sold_in_2_weeks",
"select": ["$p", "units_sold_in_2_weeks"]
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛒 E-commerce demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to dedicated markdown optimization SaaS?
Dedicated tools optimize for accuracy on a specific time-series shape (seasonal apparel, perishables, etc.). _estimate is more general — works across product categories without per-category tuning. Dedicated tools often win 1-3 percentage points on margin in their target category; the general approach trades that for broad applicability across the catalog without separate model maintenance per category.
What about cross-product effects (markdown one SKU, demand for sibling SKUs shifts)?
The query can include sibling-SKU markdown state in the where clause to condition on it. The conditional probability reflects the cross-product effect to the extent that historical events show it. For deeper modeling of substitution effects, the application can run multiple _estimate queries (one per markdown scenario) and pick the joint maximum.
How does this handle promotional events (sale weekends, holidays)?
Add the event flag to the where clause; the conditional probability conditions on it. Historical Black Friday markdowns inform future Black Friday markdowns automatically. For new events without history, the prediction returns lower confidence — the system honestly says it has not seen this combination before.
Can it predict optimal markdown depth for never-discounted SKUs?
SKUs with no markdown history return low confidence. The system can infer through similarity (similar SKU, similar category, similar customer segment) but with a wider confidence band. The category manager gets a suggested range, not a single answer; the manager makes the call on first markdown.
How does this integrate with our pricing or inventory system?
Aito returns the prediction as JSON; the pricing system reads the predicted optimal discount and either applies it or surfaces for review. Most deployments wire this through the existing pricing pipeline: the inventory system queries Aito for the recommendation, the pricing system applies it (or surfaces). The integration is HTTP and JSON.