The problem
Churn is the slow leak that kills SaaS unit economics. Every product team knows it; every retention team knows it; the question is always "which customers are about to churn, and what should we do about them?" Most teams answer this with a mix of usage-decline rules ("logins dropped 50% in the last 30 days") and intuition from the account-management team. Both work to a degree; both also generate false positives that drown the retention team and miss the silent-churn cases that do not show declining usage until the week before cancellation.
The data the prediction needs is already in the product. Usage, support tickets, billing events, feature adoption, contract milestones, contact patterns — all available, all correlated with churn outcomes. The pattern the rules try to encode is a conditional probability — and conditional probabilities have a proper home in a predictive query.
How it works
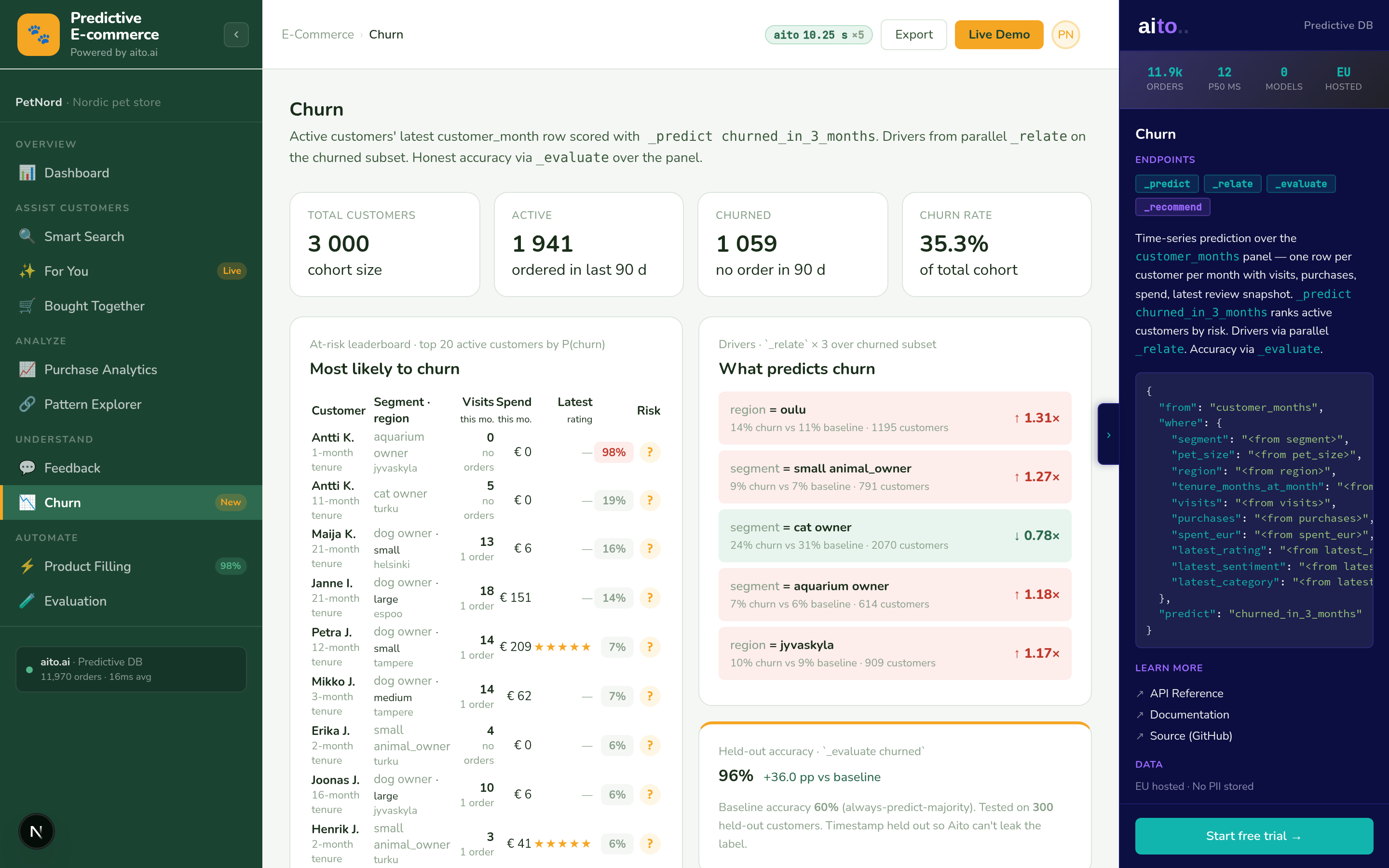
The system runs _predict churn on each active customer conditioned on the available signals. The result is a calibrated probability per customer plus a $why factor decomposition. The retention team works the top-N by predicted churn probability; high-confidence high-risk customers route to senior account managers, mid-confidence customers route to automated outreach (in-app messages, email sequences), low-confidence customers stay un-routed.
The ranked-outreach framing matters because retention is throughput-limited. The retention team can only call so many customers per week. Ranking the queue by predicted recoverable revenue (predicted churn probability × predicted lifetime value) means the team's hours go to the highest-leverage save attempts. Mature deployments combine the prediction with predicted "save probability given outreach type" to pick the right outreach action per customer.
{
"from": "subscriptions",
"where": {
"status": "active",
"renewal_date_within": "60_days"
},
"predict": "will_churn",
"select": ["$p", "$why", "customer_id", "lifetime_value"],
"orderBy": "$p:desc",
"limit": 100
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
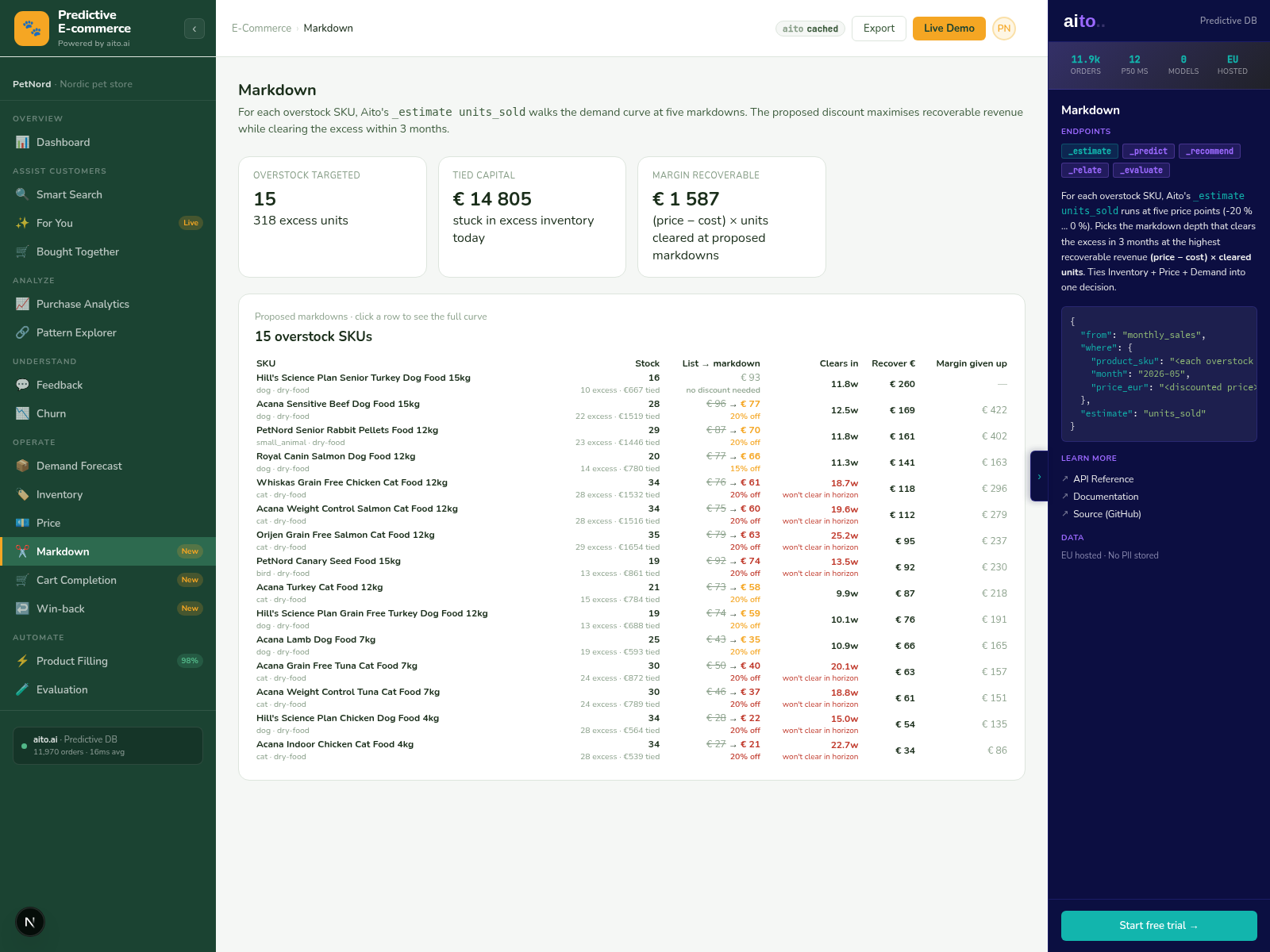
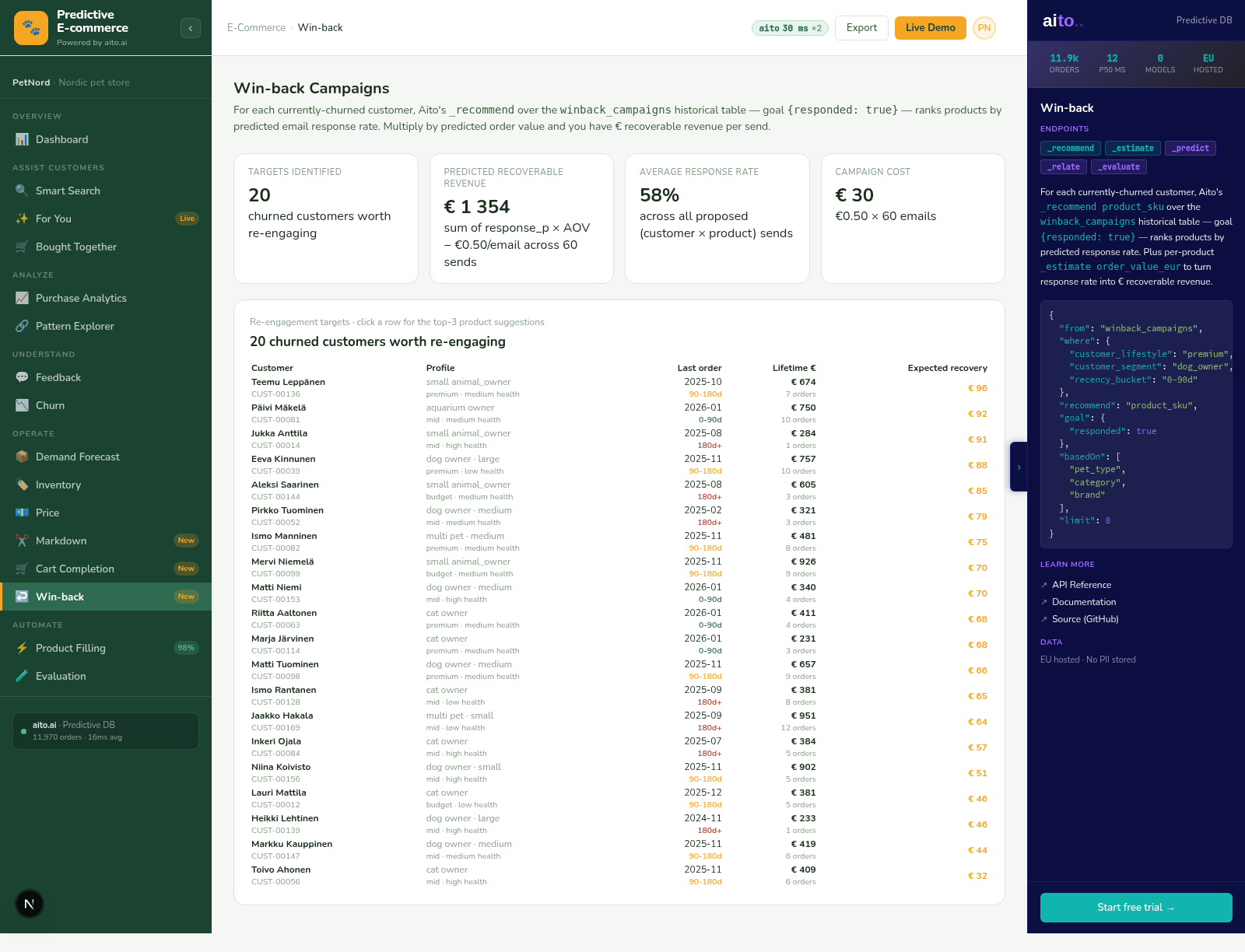
See it live
This use case runs in the 🛒 E-commerce demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to dedicated churn-prediction tools (Gainsight, ChurnZero)?
Dedicated tools have UI for the retention workflow — case management, playbook orchestration, contact tracking. _predict on subscriptions is the prediction layer; you still need the retention CRM. The two compose: Aito predicts the ranked list, Gainsight/ChurnZero (or a custom workflow) drives the outreach. For teams that want to avoid a separate vendor, the prediction plus a simple ticket-routing workflow is often enough.
What if our churn rate is low (under 5% per year)?
Low churn means few positive examples — the system has less signal to learn from. The conditional probability is still computable but the predictions are less differentiating. Mature deployments at low churn rates report ~70-80% precision in the top-N by predicted churn (vs. ~95% at higher churn rates). The retention queue is still meaningfully ranked, just with more uncertainty in the tail.
Can the prediction recommend WHICH outreach to use, not just who to call?
Yes, as a second prediction. _predict save_probability conditioned on the customer profile AND the outreach type. The result is a per-customer ranking of outreach types by predicted save probability. Mature deployments run both: rank customers by churn × LTV (which to call), and rank actions by save probability (what to say). The two together drive the retention playbook.
Does this work for one-time-purchase products (not subscription)?
The pattern translates to "predict which customers are about to lapse." For subscription products, lapse is churn. For one-time-purchase products, lapse is "no purchase in N months when historical purchase cadence was M months." Same conditional probability, different definition of the negative outcome. Mature e-commerce deployments use this for win-back ranking.
How quickly does the prediction adapt when our product changes?
New product features, pricing changes, segment shifts — all enter the conditional probability through the data they produce. No retraining schedule. The prediction reflects the most recent N customer cohorts in proportion to their representation in the data. For very abrupt product changes (major UI overhaul, large price change), the prediction quality temporarily drops while the new cohort accumulates — typically recovers within 30-60 days of the change.