The problem
The hard question in automation is rarely whether the system can produce an answer. It is who is allowed to act on it. An LLM asserts with the same fluency whether it is right or guessing, so teams either gate everything behind review, which kills throughput, or trust everything, which is how the wrong refund goes out. Neither policy survives an audit conversation.
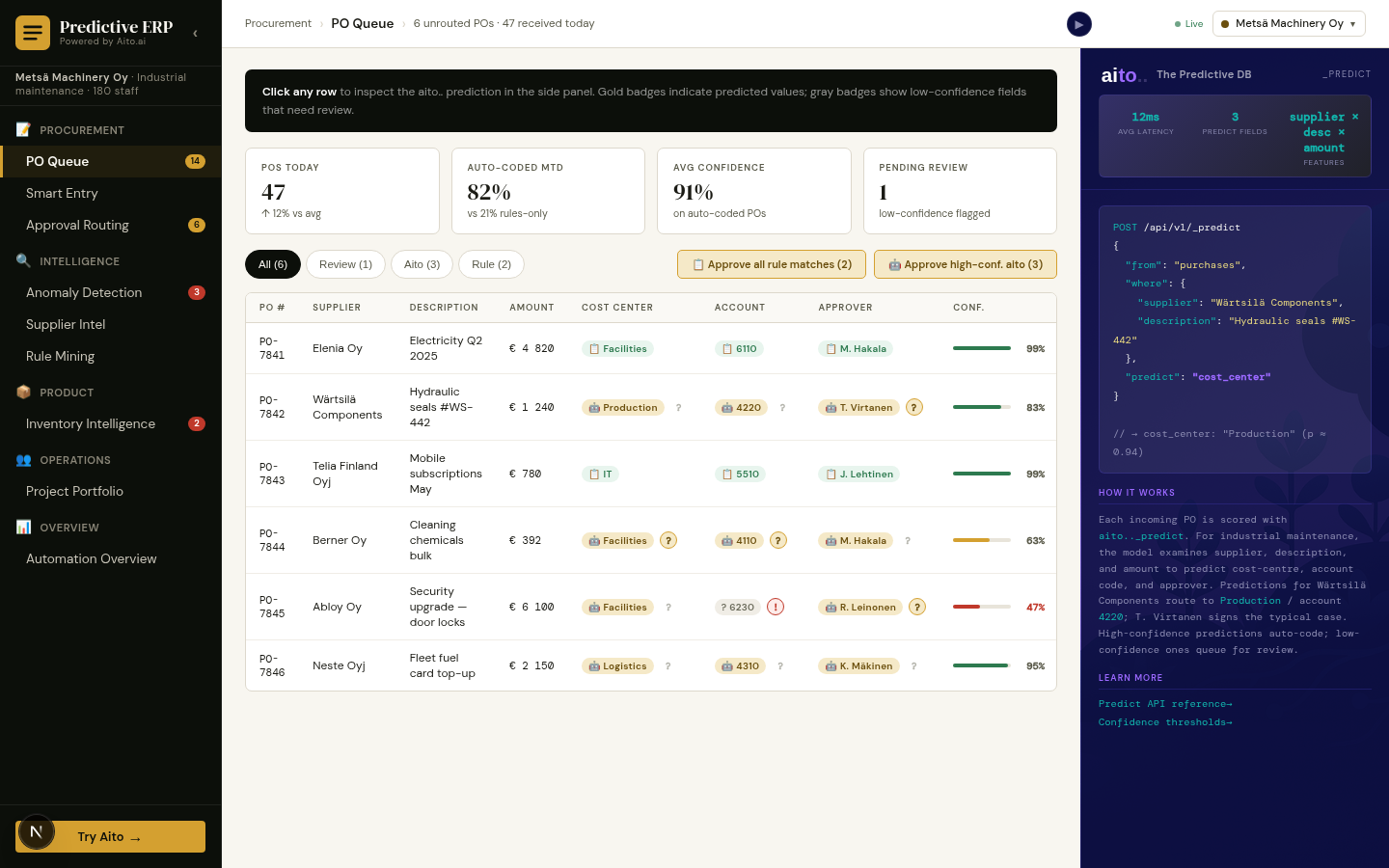
Governance needs a number, per decision, that says how sure the system is, and the number has to be calibrated: when it says 0.9, it should be right about nine times in ten. With that number, the automation boundary stops being a feeling and becomes a policy you can write down, defend, and tune.
How it works
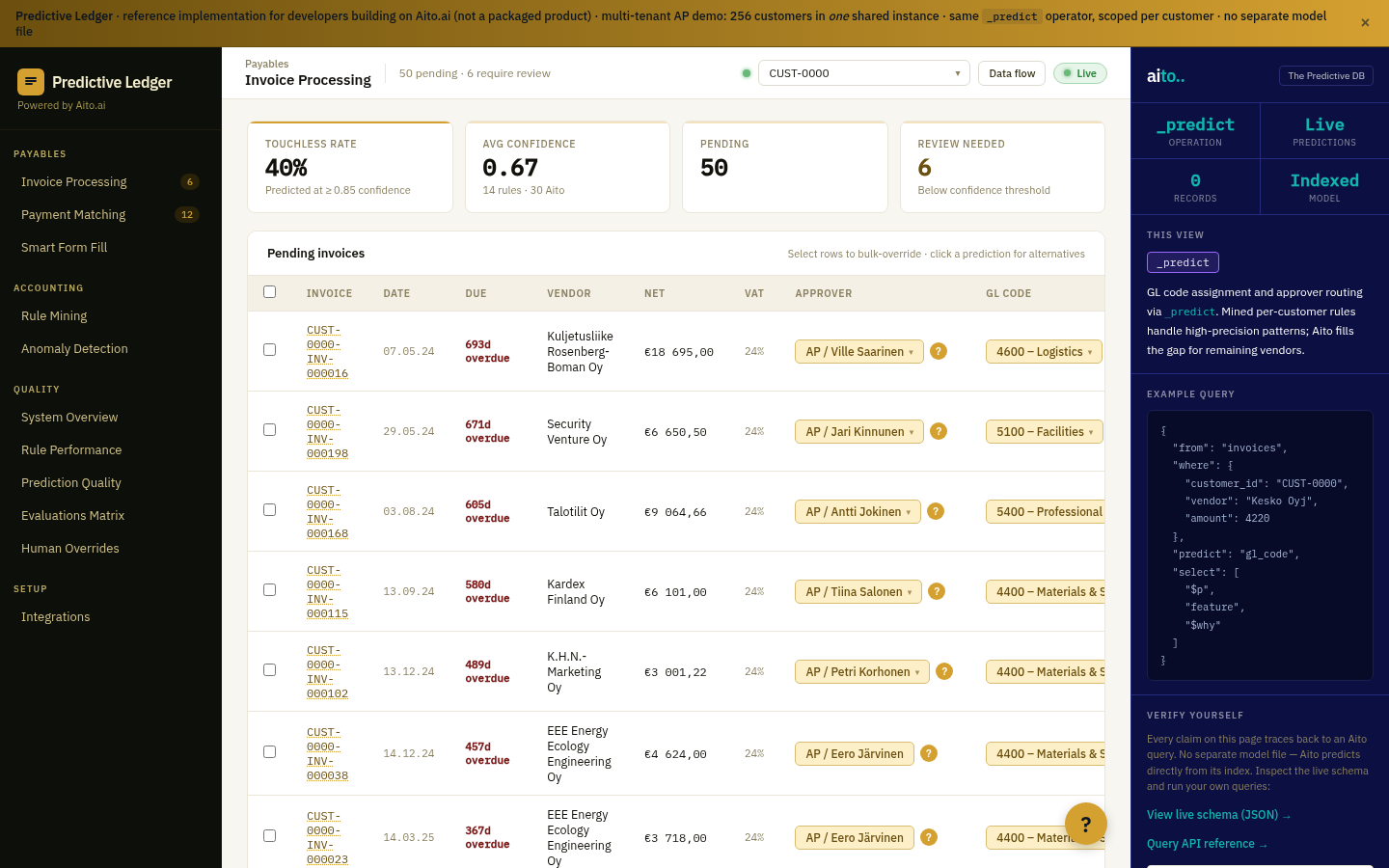
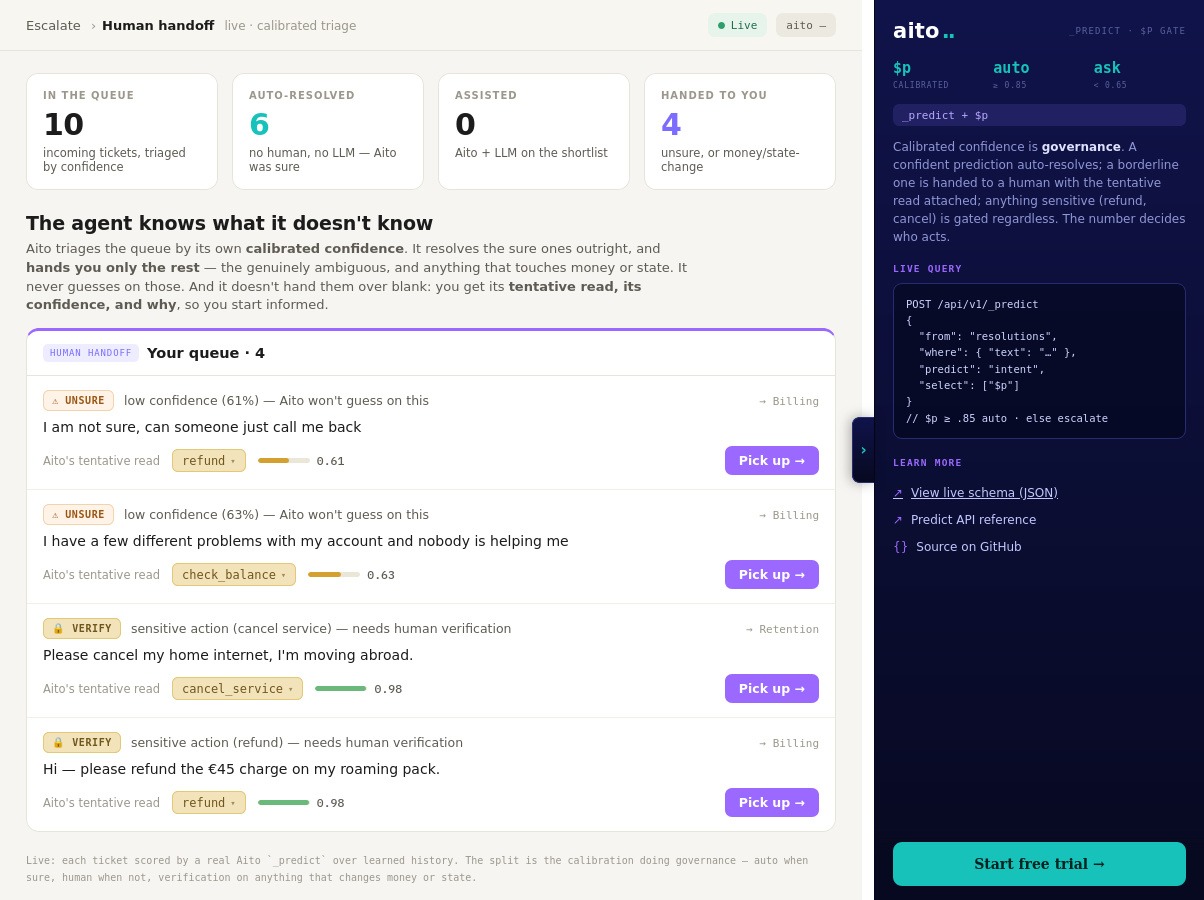
_predict returns a calibrated $p with every prediction, and the $p drives the routing. In the live demo the support queue is bucketed by the policy: at or above 0.85 the resolution auto-applies, between 0.65 and 0.85 the item is handed to a human with the tentative read attached so triage starts from a draft instead of a blank queue, and below 0.65 it escalates as too ambiguous to auto-act. Anything that moves money, such as a refund or a cancellation, is gated for human action no matter how confident the prediction.
The thresholds are application policy, not model internals, so risk and compliance can set them per decision type and adjust them as trust accumulates. Every human correction writes back, which moves borderline cases toward the auto-resolve bucket over time. The same gate works in front of an agent's actions: the demo's sales agent must clear a confidence gate before its drafted email is allowed to send.
{
"from": "resolutions",
"where": {
"subject": "Mobile data not working abroad",
"customer.plan": "consumer"
},
"predict": "intent",
"select": ["$p", "intent", "$why"]
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🤖 Agent demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
Why does calibration matter more than accuracy here?
Because the policy acts on the number, not on the average. A 95%-accurate system whose confidence is uncalibrated still cannot tell you which 5% to send to a human. A calibrated $p sorts the individual cases, which is what an auto-versus-review boundary needs.
How do we choose the thresholds?
Start from the cost of a wrong auto-action per decision type. The demo's 0.85 and 0.65 are sensible defaults for support resolutions; an invoice approval might gate higher. Because $p is calibrated, the threshold maps directly to an expected error rate you can put in the policy document.
Does this work for gating LLM or agent actions, not just predictions?
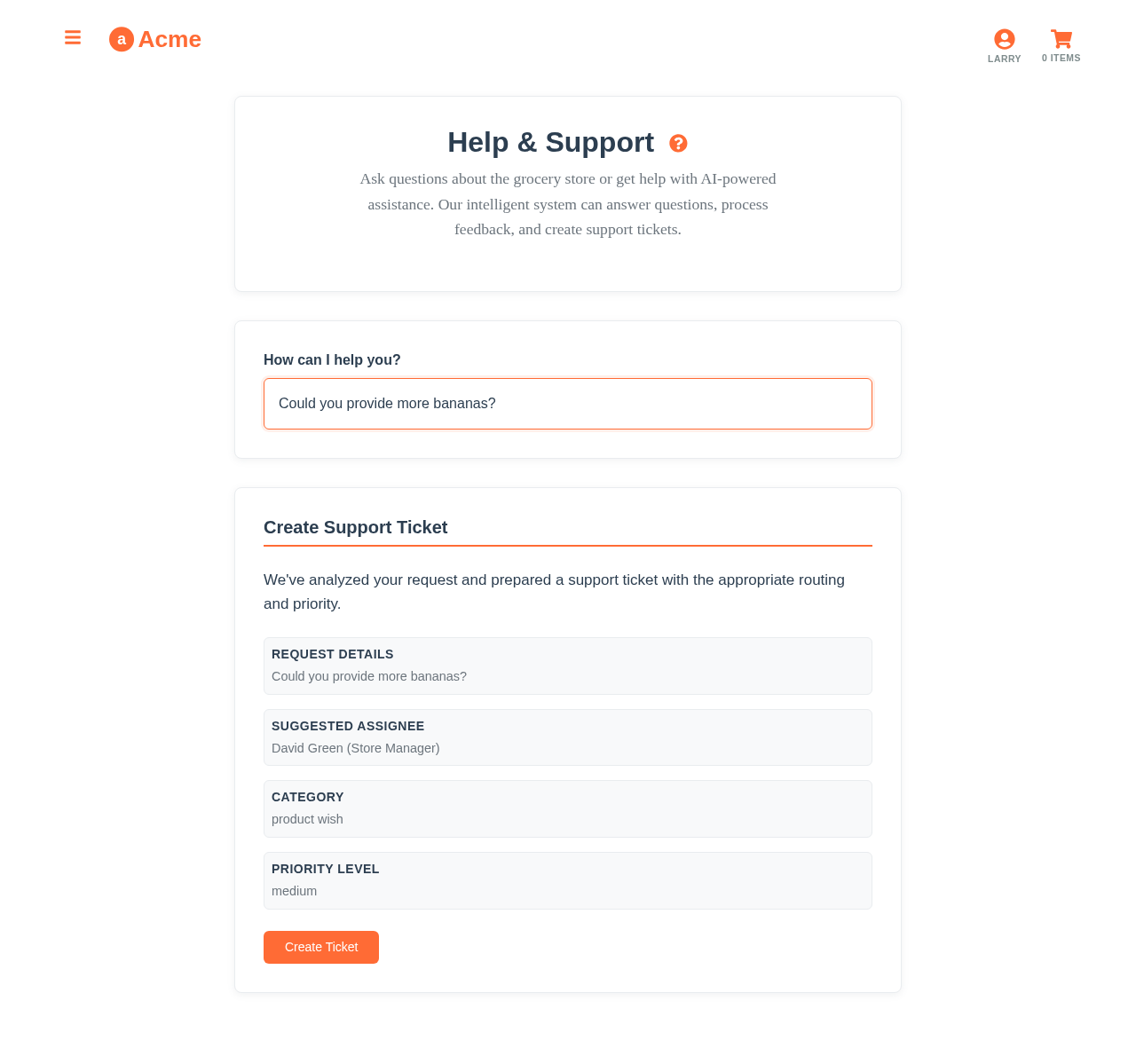
Yes. The gate sits between any proposed action and its execution. In the demo the agent drafts the outreach email, and the send button only clears when the predicted outcome passes the gate; sensitive intents stay human-only regardless. The LLM proposes, the calibrated number disposes.
What does the human see on a handoff?
The tentative read: the predicted intent or resolution, its $p, and the $why drivers. Triage starts from a reviewable draft rather than a blank ticket, which is where the throughput gain on the human side comes from.
How does the boundary improve over time?
Corrections are rows. A human override enters the index immediately, so the next similar case predicts with better-grounded confidence, and categories that once sat in the review band drift above the auto threshold as evidence accumulates.