The problem
Tags are the universal organizational primitive of business content. Product categories, document classifications, customer topics, ticket areas, content themes — everywhere a team has lists of content that need filtering or routing, tags do the work. Most teams apply tags manually; the small subset of high-leverage tags get a workflow, and the rest accumulate inconsistently or not at all.
The cost of inconsistent tagging is invisible until you need to filter. Then you find that half the relevant items do not have the right tag, and the system stops being useful. The pattern that should drive tagging is in the content itself — the title, the body, the metadata — but the human is doing the matching one item at a time.
How it works
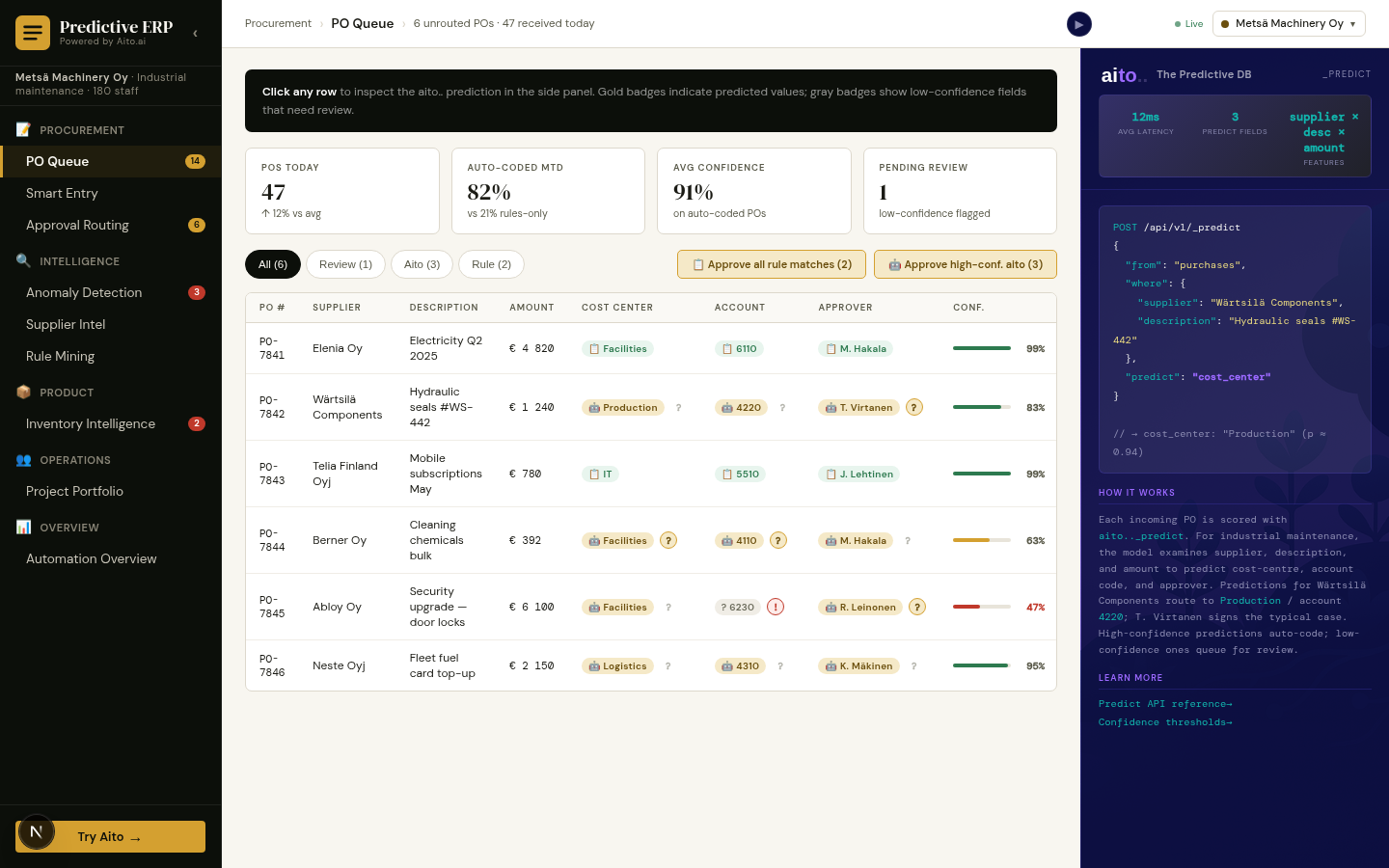
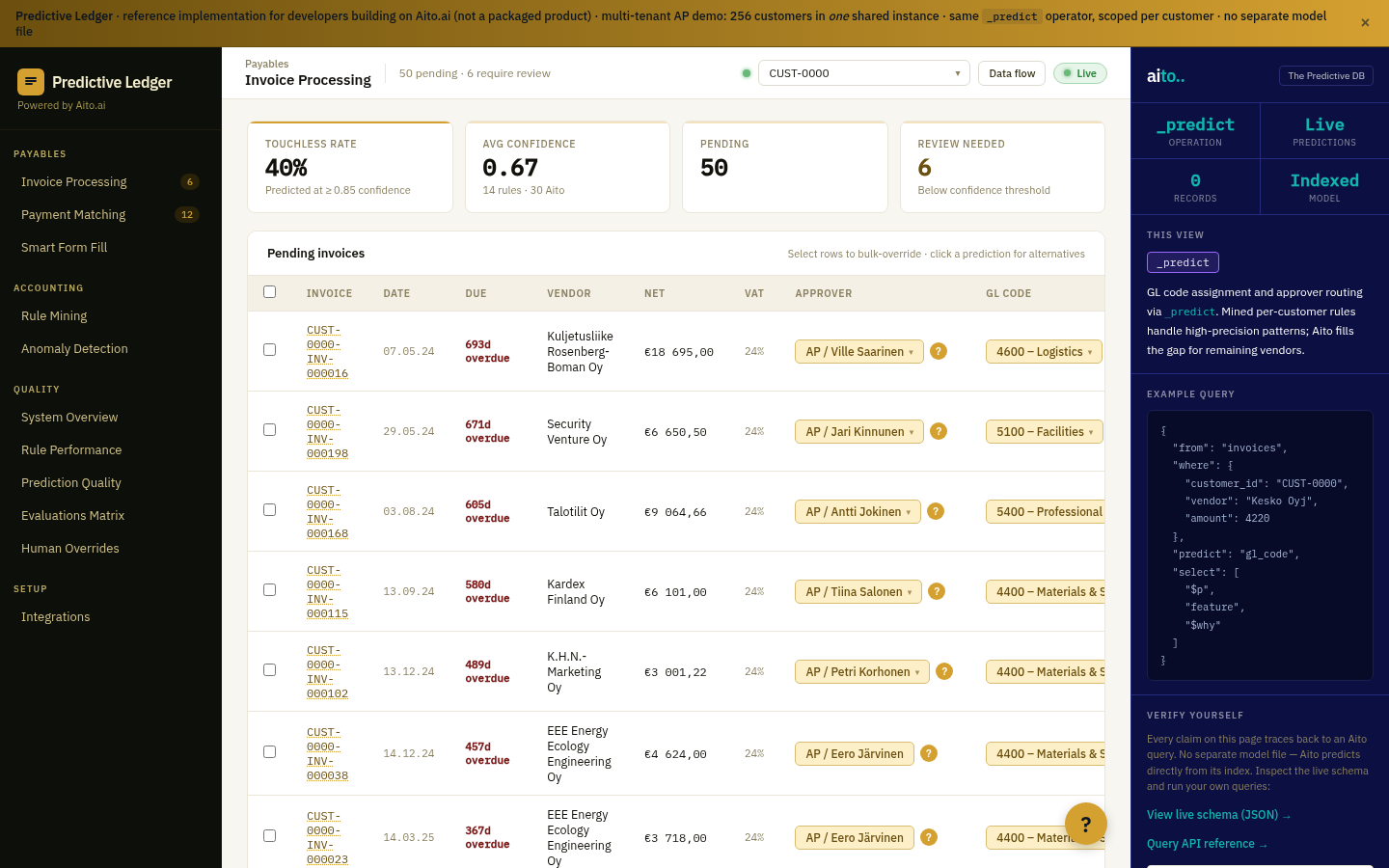
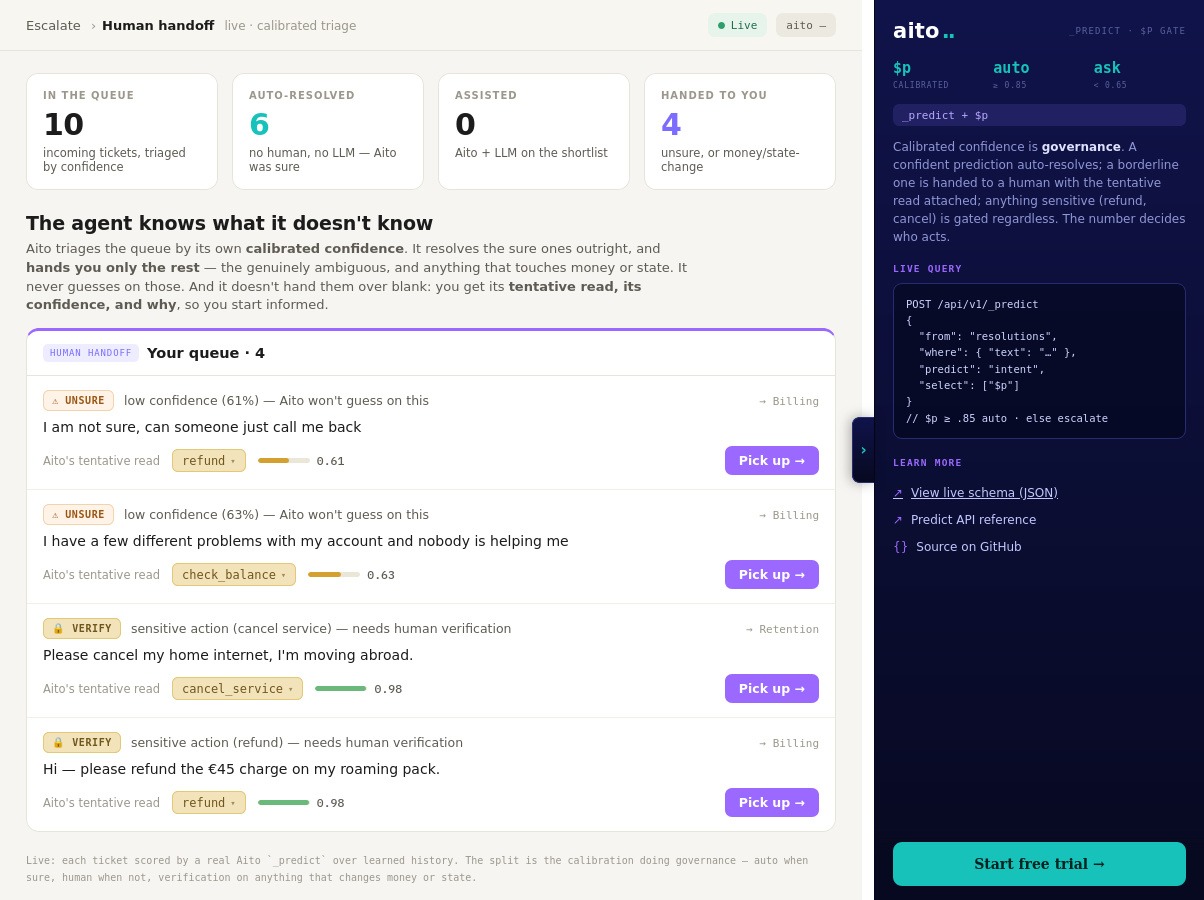
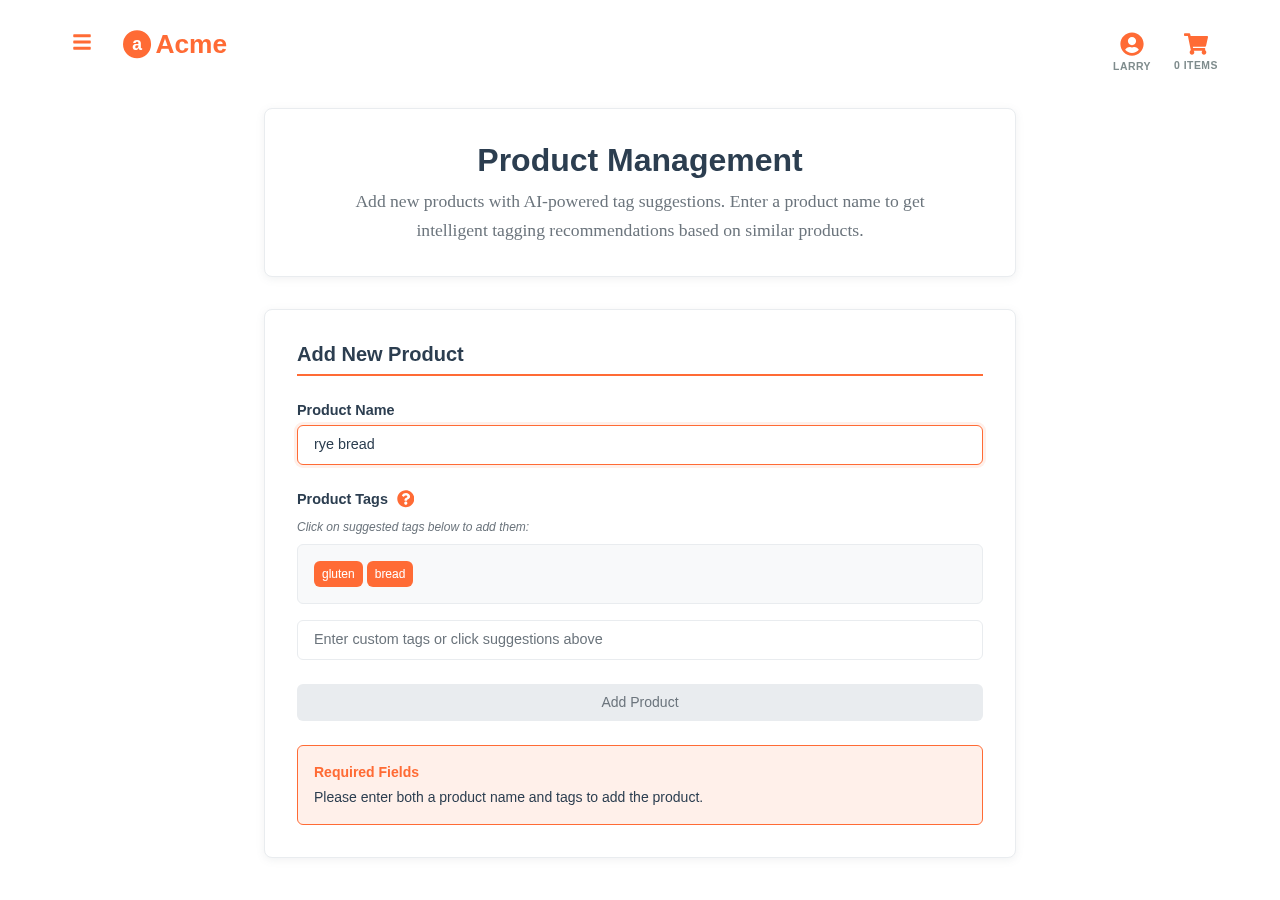
Tag prediction in Aito is multi-label _predict: given the content fields, predict the relevant tags with their individual confidences. Each tag has its own threshold. High-confidence tags auto-apply; mid-tier tags appear as suggestions; low-tier tags do not appear at all. The user accepts or overrides; overrides flow back as training data.
The system handles the typical tagging messes naturally. Adding a new tag to the taxonomy does not require retraining — apply it to a few examples and the conditional probability picks up. Renaming a tag preserves the historical conditional probability by tag ID rather than label. Tags with low support (rarely-used) automatically get low-confidence predictions rather than being over-applied.
{
"from": "content",
"where": {
"title": "How to use predictive databases for invoice automation",
"body": "..."
},
"predict": "tags",
"select": ["$p", "tags"],
"limit": 8,
"exclusiveness": false
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
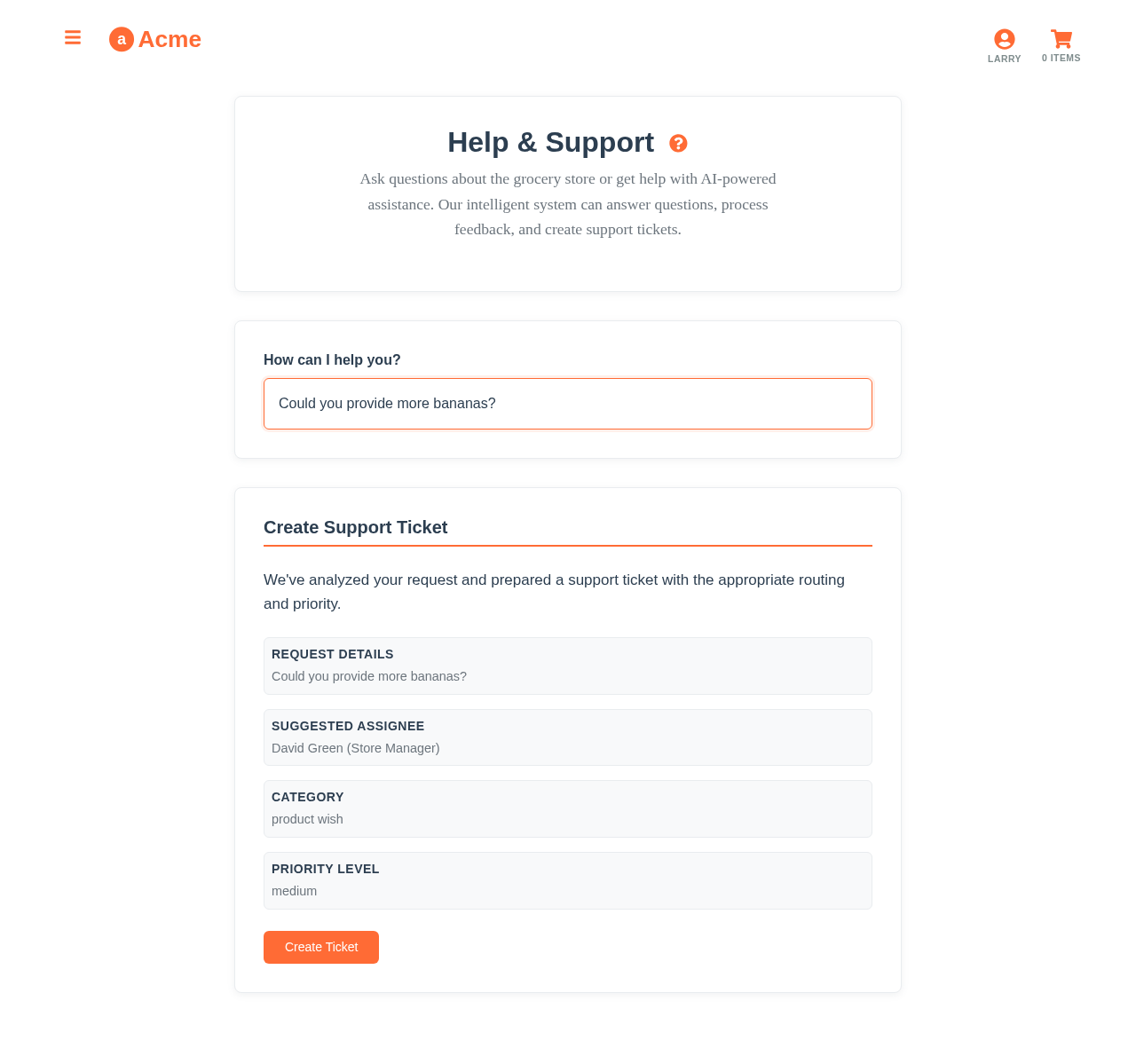
This use case runs in the 🛍 Grocery demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this handle hierarchical tag taxonomies?
Two ways. First, you can predict at any level of the hierarchy as a separate column — top_category, mid_category, leaf_category each get their own _predict. Second, the hierarchy itself becomes a learned property: the conditional probability of mid_category=widgets given top_category=hardware is high; the system never proposes incoherent combinations. Most deployments do both.
What if our tag taxonomy is large (1,000+ tags)?
The prediction is over all tags simultaneously, ranked by confidence. Large taxonomies work — the system surfaces the top-N tags above the threshold and ignores the rest. The dominant cost is the false-positive rate on tags with very few historical applications; the confidence threshold filters those out automatically.
Can tag prediction work alongside human-applied tags?
Yes — that is the typical pattern. The system suggests; the human reviews and applies. Each human application becomes a training signal for the next prediction. Over time the human's role shifts from "tagging from scratch" to "confirming or correcting suggestions." Many deployments never reach full auto-tagging; the system reduces effort 60-80% even in suggest-mode.
How accurate is this on rarely-applied tags?
Rarely-applied tags get rarely-confident predictions. That is the right behavior — if a tag has only been applied 5 times, the conditional probability is wide and the prediction is honest about its uncertainty. The system surfaces such tags only when the surrounding fields strongly indicate them; otherwise they stay below the threshold.
Does it support multi-language content?
Yes. Predictions are conditional on the content; the system does not require translation. A piece of content in Finnish gets tags based on Finnish-language patterns; the same tag taxonomy can be applied across languages because the tags themselves are language-independent IDs.