The problem
Similarity matching is one of those problems with too many tools and too little fit. Vector databases require embedding the data first; embeddings on structured data either don't capture the attributes that matter or capture them with too much noise. Hand-authored similarity rules are fragile and miss the patterns that aren't in the rule set. The team usually picks one and pays the cost of the wrong fit.
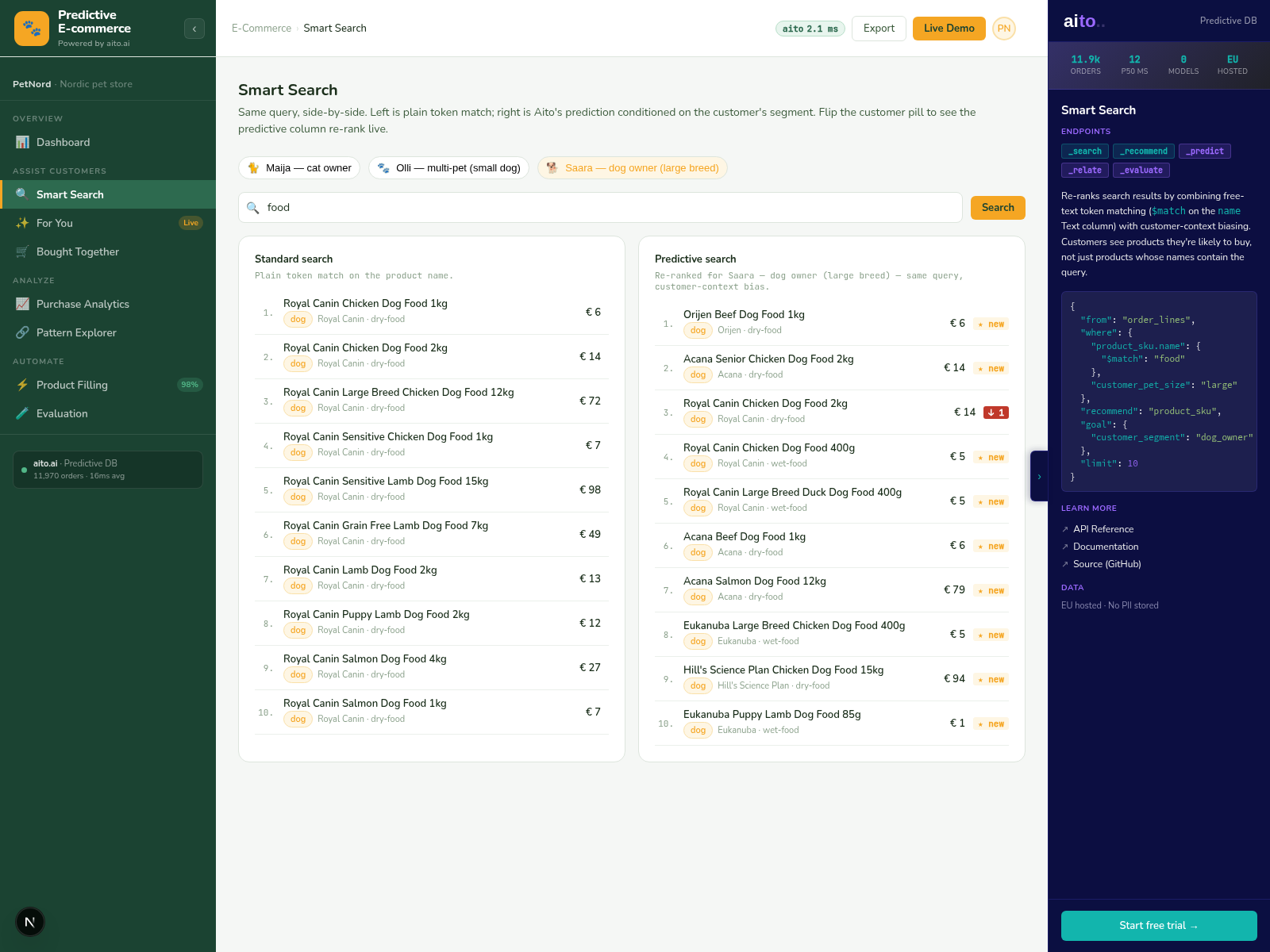
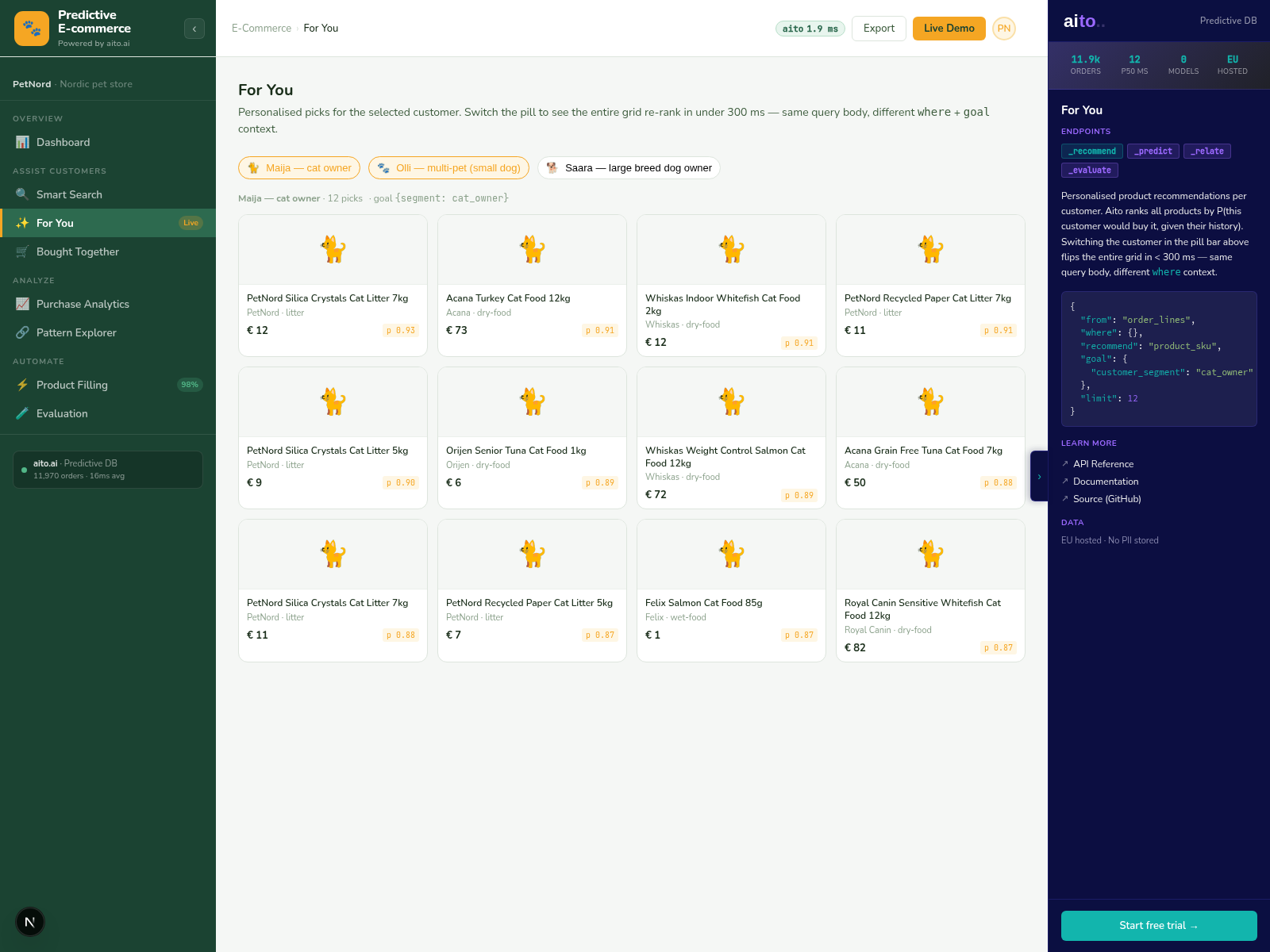
Aito's match operator runs similarity over the actual column distributions. "Find products similar to this one" is computed by which attributes overlap in the column-distribution sense — not in an embedding sense. The result is interpretable (you can see WHY the match is similar by examining the attribute overlap) and doesn't require a separate embedding pipeline.
How it works
_match takes a reference row and returns the top-N most similar rows by column-distribution similarity. The similarity metric considers all attributes of the reference; the result is ranked by overall similarity score. Filters in the where clause scope the search (e.g., only within a product category, only above a certain quantity).
The mechanism is closer to nearest-neighbor on tabular data than to vector similarity. Categorical attributes match on exact equality with appropriate weighting; numeric attributes match on conditional distribution proximity. The result is calibrated similarity that respects the table's actual schema, not a flattened embedding.
{
"from": "products",
"where": {
"category": "dog-dryfood",
"$exclude": { "sku": "WIDGET-1042" }
},
"match": { "sku": "WIDGET-1042" },
"limit": 10
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛍 Grocery demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to vector-database similarity (pgvector, Pinecone)?
Vector DBs require an embedding step — text is embedded into vectors, similarity is cosine distance in vector space. _match works directly on tabular columns without the embedding pipeline. For structured catalog data, the column-distribution approach is often more accurate; for unstructured text data, vector DBs win. The difference is measurable: in the live benchmark at agent.aito.ai (ticket-assignment-bench), vector search picks the wrong customer's memory 86% of the time because symptom text matches across customers, while conditioning on structure recovers the customer the text alone can't identify.
Can match be combined with predict in the same query?
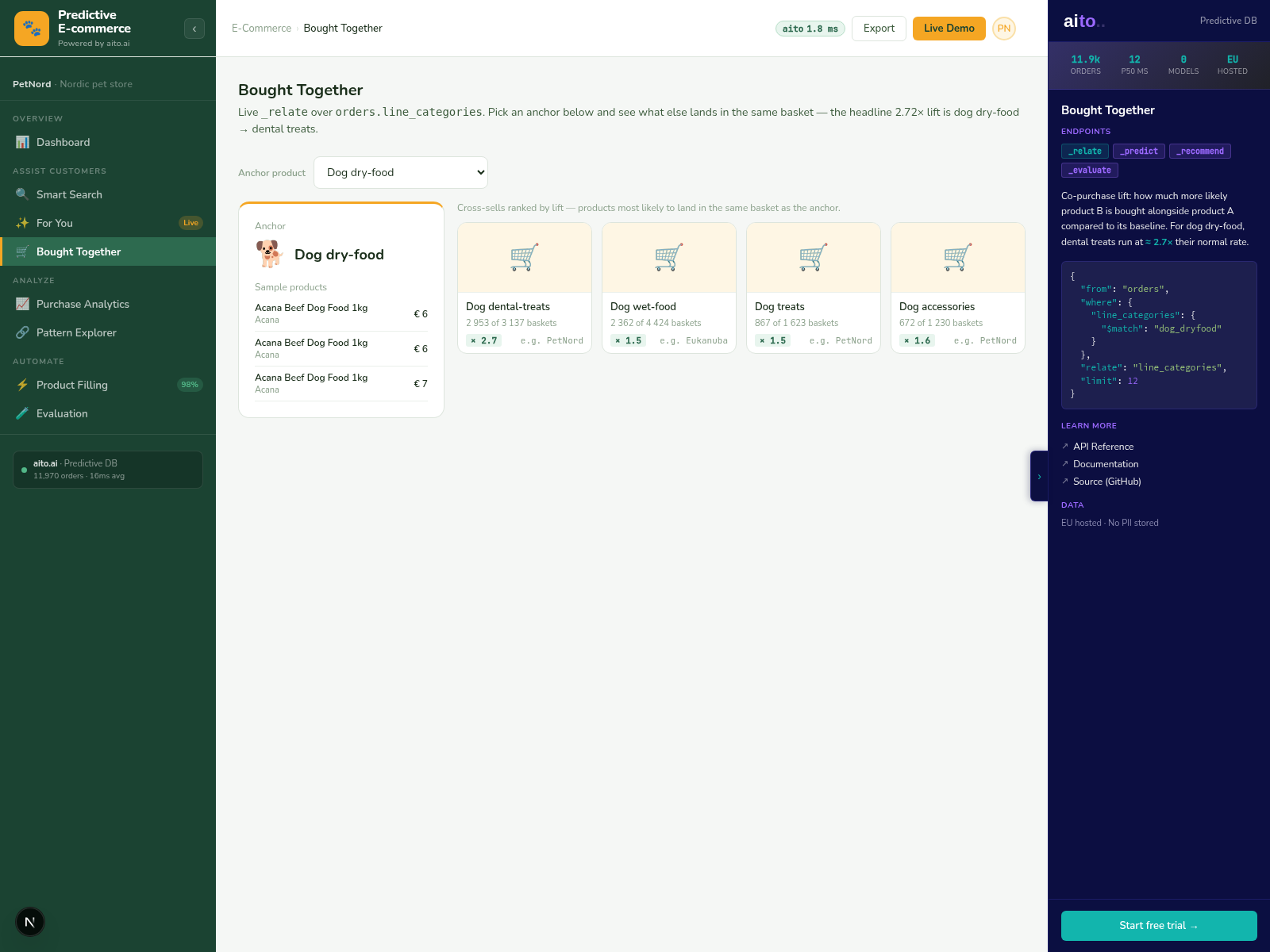
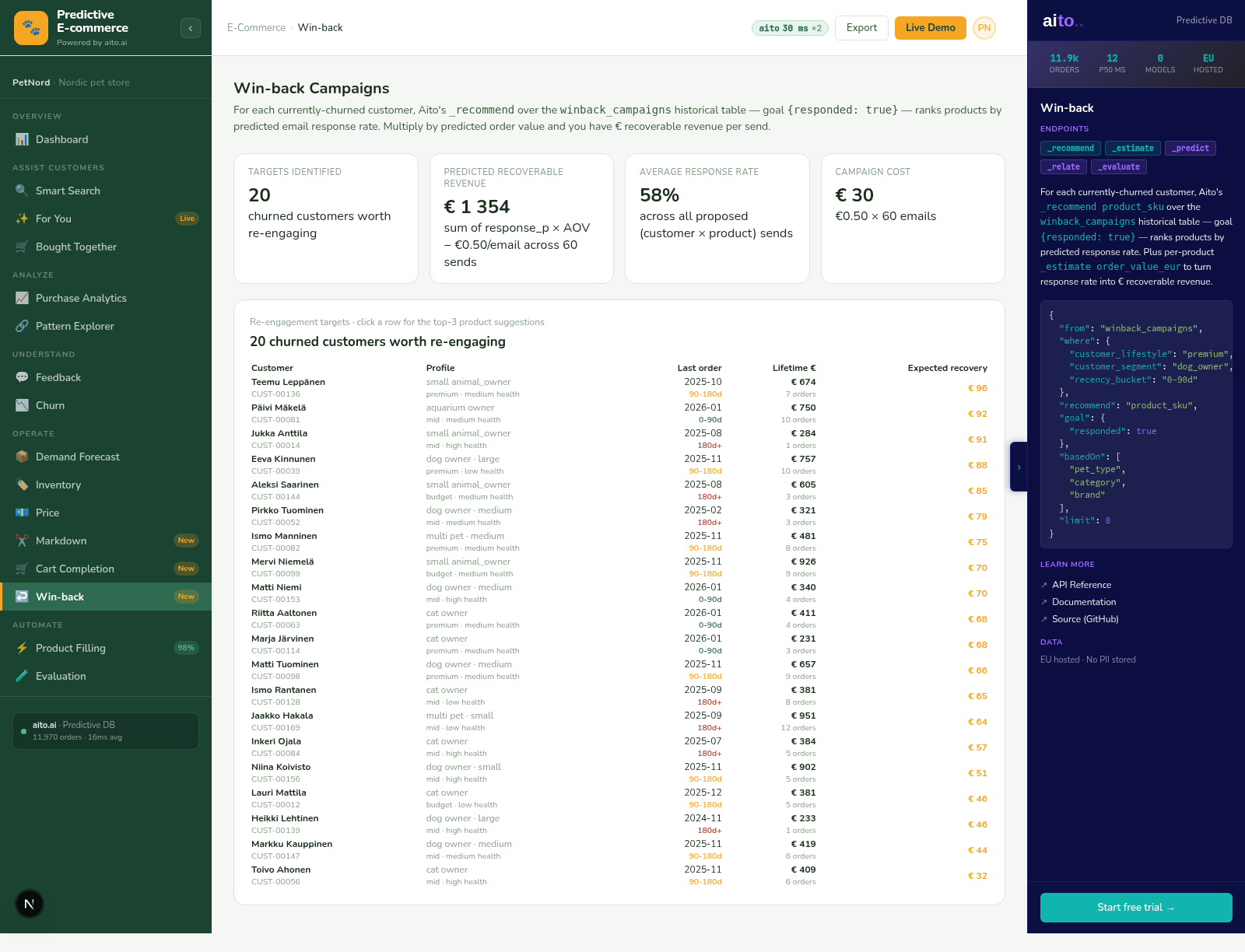
Yes. "Find similar products, then predict the demand for each" composes the two operators. Match returns the similar set; predict runs against each row in the set. Used in catalog gap-fill where the similar products inform the predicted attributes for a new SKU.
Does this work for ticket deduplication or document matching?
Yes. Match runs on whatever columns the table exposes. For tickets, similarity is computed on title, description, category, customer. For documents, on title, body, tags. The mechanism is column-agnostic; the schema does the work.
How fast is match at large catalog scale?
Query latency stays in the sub-200ms range up to ~10M rows. The columnar index does the heavy lifting at ingest; match at query time is feature comparison over indexed statistics. For very large catalogs, scoping with a where clause reduces the candidate set further.
Can we combine match with a vertical-specific embedding for hybrid search?
Yes. Many deployments run vector similarity for the unstructured part (product description text) and match for the structured part (category, attributes). The two results compose via reranking; the final ordering blends both signals.