The problem
Bought-together recommendations are the load-bearing cross-sell pattern in e-commerce. Show the buyer of dog food the dental treats; show the buyer of running shoes the moisture-wicking socks; show the buyer of the SaaS subscription the integration add-ons. The cross-sell decision has been made millions of times across e-commerce history; what is missing in most catalog tools is a system that finds the actual statistical co-occurrence in the data rather than relying on hand-curated cross-sell rules.
Hand-curated rules are fragile. They reflect the merchandiser's best guess at launch; they do not update as buying patterns shift; they miss the long-tail patterns no one thought to encode. The data has the answer — millions of orders show which products actually co-occur — but the data has been silent because there is no easy way to query the answer.
How it works
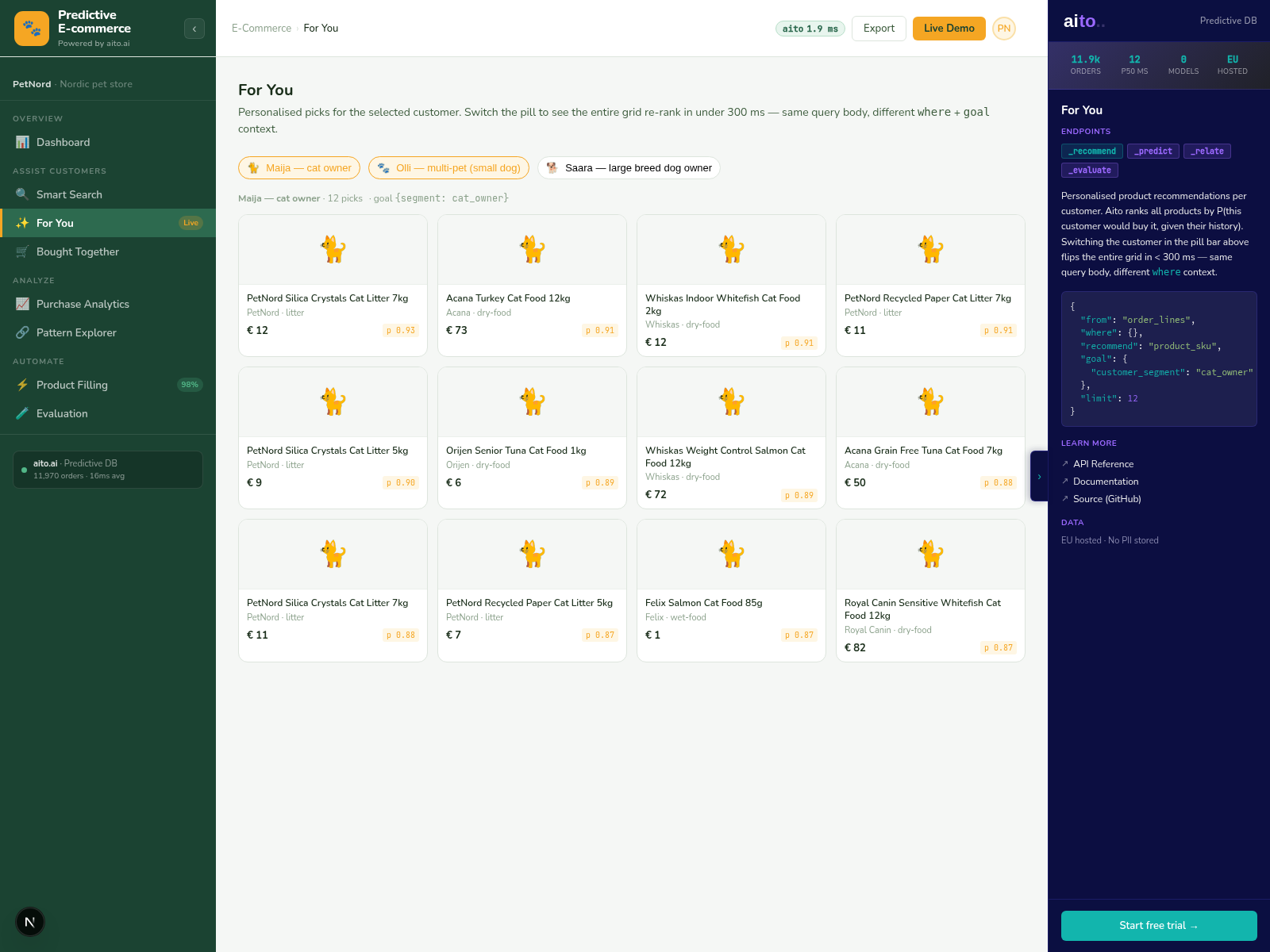
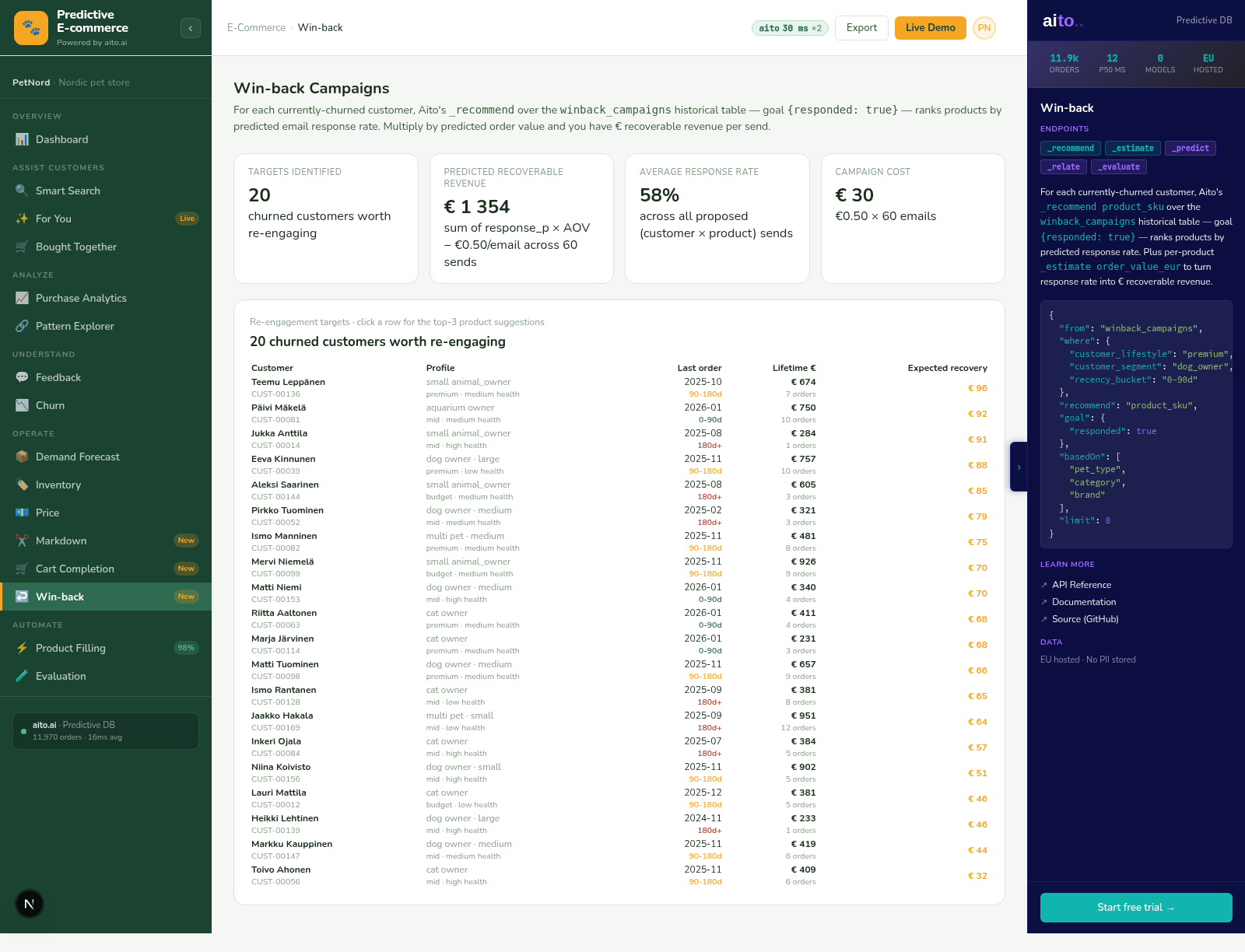
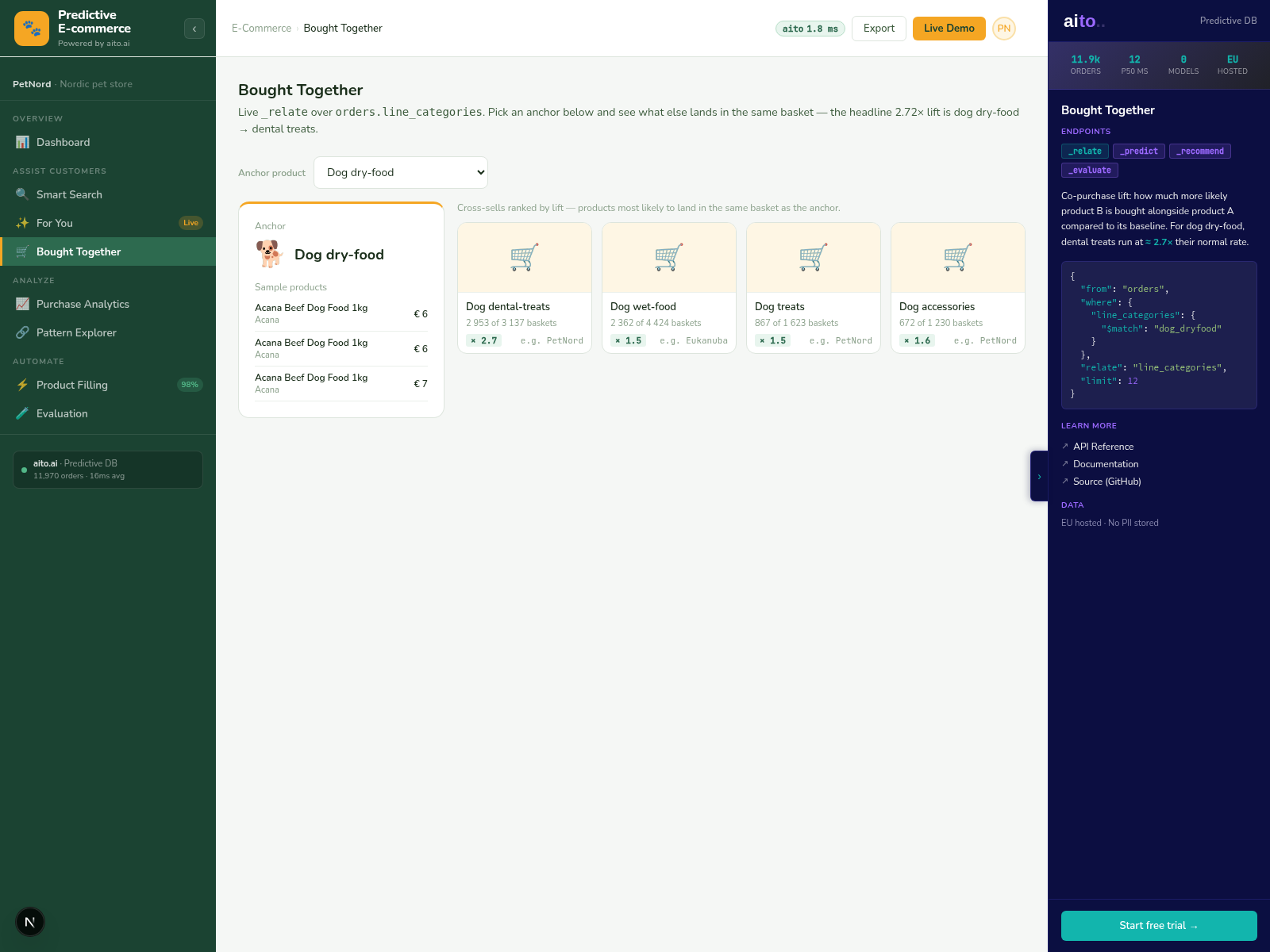
The Bought Together view in the e-commerce demo runs _relate across the order-lines table to surface the strongest cross-sell pairs ranked by lift. For a given anchor product (or anchor category), the query returns the products most disproportionately likely to appear in the same order. Lift is the ratio: of customers who bought the anchor, how much more likely are they to also buy the candidate compared to the overall population?
The dog dry-food → dental treats result at 2.72× in the PetNord fixture is not a curated rule. It is a live conditional probability over the actual co-purchase data. Run the query, get the number. Change the data (more orders accumulate, seasonal patterns shift, a new product enters the catalog), and the next query returns the updated number — no batch recommendation rebuild, no separate model.
{
"from": "order_lines",
"where": {
"product.category": "dog-dryfood"
},
"relate": "product.id",
"with": "category",
"select": ["$lift", "$p", "product.id"],
"limit": 10
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛒 E-commerce demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How does this compare to collaborative-filtering recommendation engines (matrix factorization, neural CF)?
Collaborative filtering builds a user-item matrix and decomposes it. Effective on dense data; struggles on cold-start items and tail products. _relate over co-purchase data is a simpler statistical primitive that returns conditional lift directly. On dense data, neural CF often wins on raw accuracy; on the cold-start tail and on items with little history, the statistical approach degrades more gracefully and the predictions are calibrated and explainable.
What about user-personalized cross-sell (different recommendations per user)?
Personalized cross-sell is _recommend against the impressions or clicks data conditioned on the user's segment or behavior. Bought-together via _relate is the catalog-level pattern; personalized cross-sell composes that with user-conditional probability. Both run from the same data, no separate model.
How do we avoid the obvious-bundle problem (recommending things customers always buy together anyway)?
The lift metric handles this. Lift = conditional / baseline. A product pair that is bought together a lot but also bought separately a lot has low lift — the recommendation is not surprising. A pair with high lift is statistically over-represented among co-purchases; that is the recommendation worth surfacing.
Does this surface seasonality (e.g., dog dental treats at vet-visit time)?
_relate is computed over the current data — including the most recent orders. Seasonal patterns are reflected automatically because the most recent month's co-purchase data dominates the conditional probability in proportion to the volume. For explicit seasonality conditioning, add a time-range filter to the where clause.
Will this scale to a catalog with millions of SKUs?
The columnar index makes _relate scale with the data volume, not the catalog size. Query latency stays in the sub-200ms range up to ~10M rows in production; for larger catalogs, the bottleneck is usually the front-end rendering of N suggestions rather than the prediction itself.