The problem
Similar-item recommendations sit alongside cross-sell as the load-bearing recommendation pattern in e-commerce. "You're looking at this product; here are five similar ones you might also consider." The pattern is so universal that every catalog tool has some version of it.
The implementations vary in cost. Vector-based similarity (embed each product, run kNN) is fast but requires the embedding pipeline. Manually curated similar-item lists are accurate but fragile and don't scale. Tag-based similarity is in between but misses cross-tag patterns. None of these are perfect; most catalogs end up with a mix that's hard to maintain.
How it works
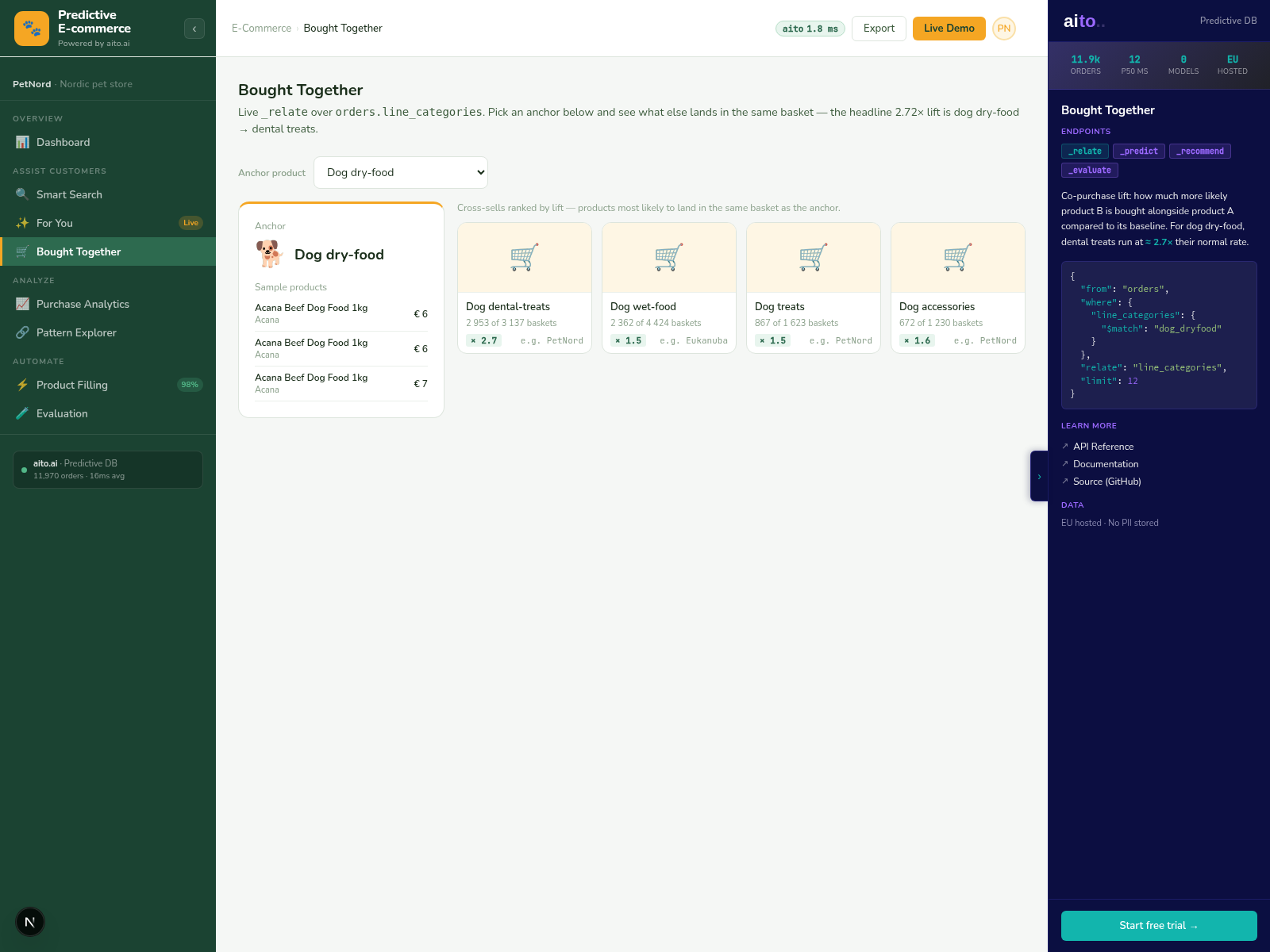
_relate over catalog attributes computes the conditional probability of one product appearing in similar contexts as another. "Of customers who buy product A, how much more often do they also buy product B?" That is the standard cross-sell pattern (Bought Together). For similar-item, the question shifts: "of customers who view product A, which products do they view in the same session at high lift?"
The result is a calibrated similar-item ranking that respects actual user behaviour, not just attribute matching. Two products in the same category but with different price points have low similarity if customers viewing one don't typically view the other; two products in different categories but with similar buyer segments have high similarity. Behaviour defines the similarity; the catalog schema is just a constraint.
{
"from": "impressions",
"where": {
"product.id": "WIDGET-1042"
},
"relate": "product.id",
"with": "session_id",
"select": ["$lift", "$p", "product.id"],
"limit": 10
}For the full architecture, see the technology overview. For the broader narrative across multiple use cases, read The Predictive Application.
See it live
This use case runs in the 🛒 E-commerce demo today. Click through to the live application and inspect the queries that produce the result. Source is on GitHub under Apache 2.0.
Frequently asked
How is this different from Bought Together?
Bought Together looks at co-purchase patterns in the same order. Similar Items looks at co-view or co-session patterns. The first surfaces complementary products ("customers who bought X also bought Y"); the second surfaces substitute products ("customers who looked at X also looked at Y"). Different intent, same _relate primitive.
Does this work for catalog with no purchase history (pre-launch products)?
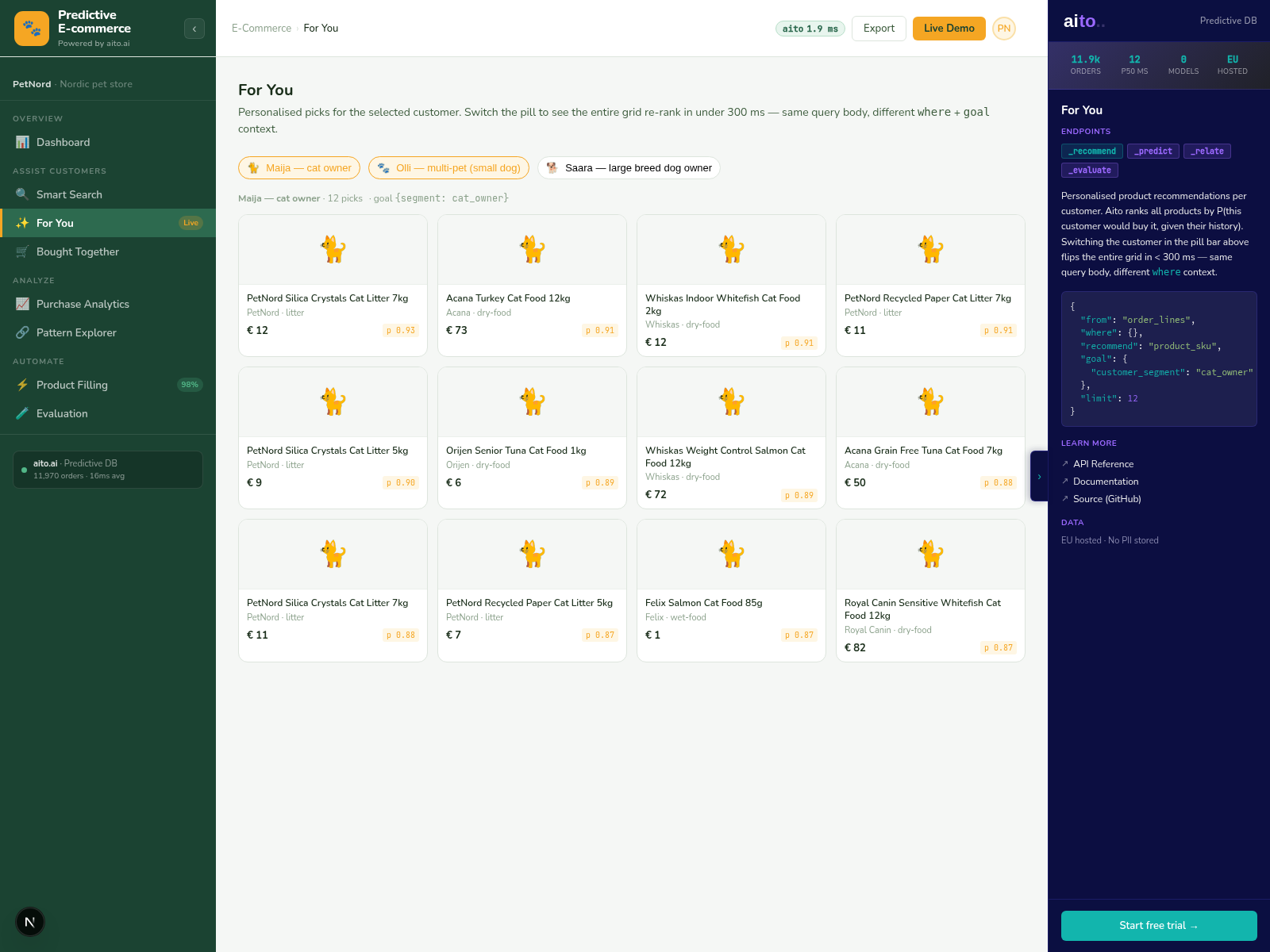
Pre-launch products with no behavioural signal get attribute-based similarity instead — match over the product attributes. Once the product accumulates impressions and purchases, the prediction transitions to behaviour-based. The two phases are seamless from the user's perspective.
Can similar-item rankings adapt to seasonality?
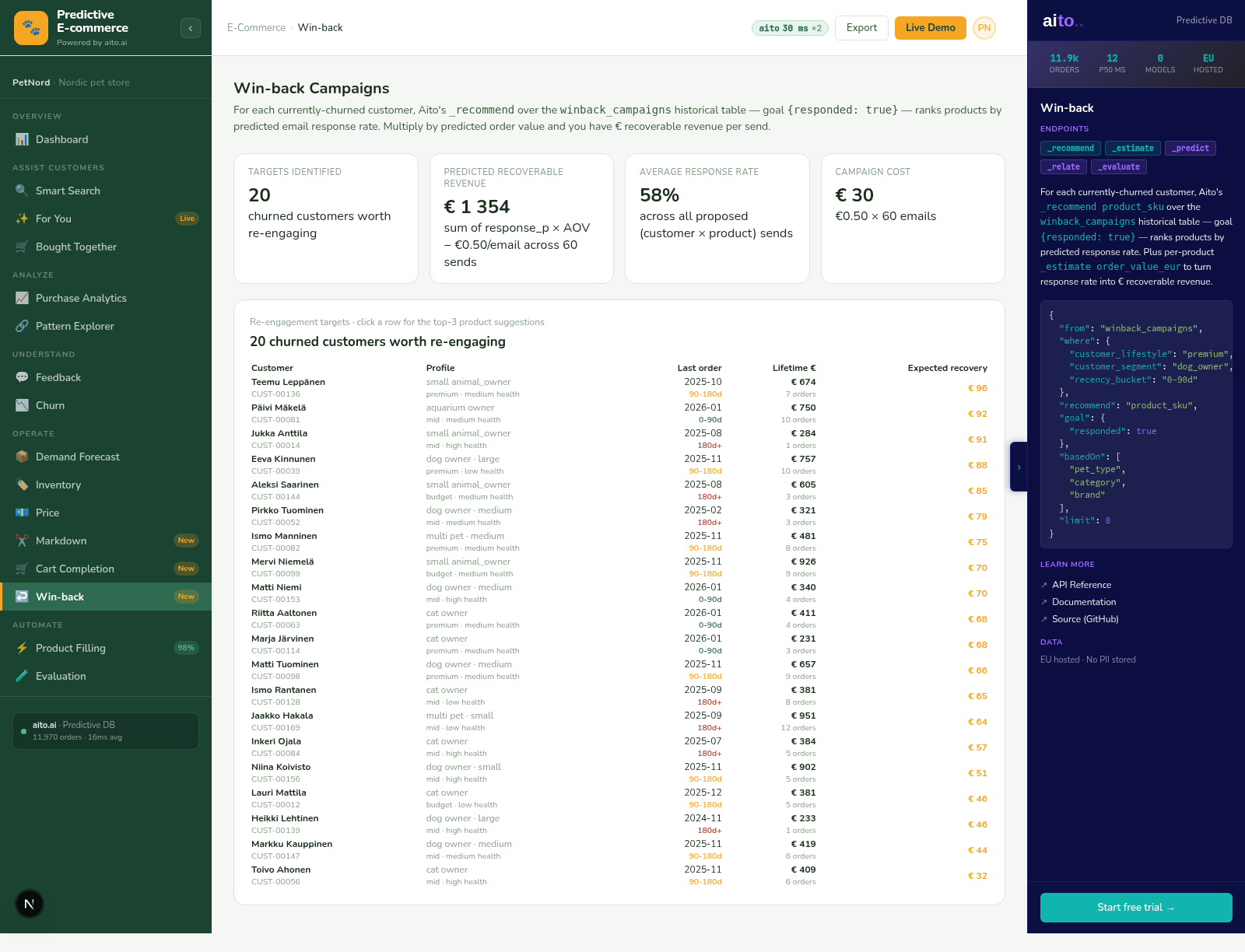
Yes. _relate computed over recent data reflects current behaviour. Seasonal patterns (winter clothing, summer gear) emerge automatically because the most recent month's data dominates the conditional probability. For explicit seasonality, add a time-range filter.
How does this scale on a million-SKU catalog?
_relate stays sub-200ms up to ~10M rows of behavioural data. The catalog size matters less than the impression volume — most catalogs see far more impressions than they have SKUs. Scoping with where clauses (similar items within the same category, similar items above a price floor) reduces the search space further.
Can this be used for service-similarity (similar consultants, similar projects)?
Yes. The pattern is "find rows in the same table that appear in similar contexts." Consultants appearing in similar project types are similar; projects with similar attribute patterns are similar. The underlying machinery is schema-agnostic.