Using the predictive database to match dissimilar content
Antti Rauhala
Co-founder
November 6, 2019 • 12 min read
Teosto, is a non-profit performance rights organization that collects royalties on behalf of songwriters and composers in Finland. From different TV-stations they get reports on which music is used in series, movies and media. To avoid manual matching of the reports, they asked us if there was a possibility to automate this process based on the incomplete and messy (i.e. heterogeneous) data they had.
Aito’s predictive database was used to apply the machine learning algorithm “matching” to do the job. This brought Teosto a step closer to their vision of becoming an AI-powered organization.
Matching... what?
Matching is one of the most common, yet worst recognized, problems in both software engineering and data science fields. The most familiar example of the problem is probably matching people with people (dating apps) but we take matching jobs with people as our example here.
In its essence, matching is about matching an entity with features, like a job description, with another entity of features, like a profile description or cv. In the matching problem, the contents may look similar. In the job description we may have ‘hiring software engineer’ and in the profile description we may have description ‘a software engineer’. When the contents are similar enough, the problem gets often approached with traditional search engines, as they are great in finding similar content. You essentially ask the engine to find a job, which shares lots of words with the CV.
Still, this approach has its challenges, as you may end up matching not just ‘software’ with ‘software’, but a writing style with a writing style or common words with common words. As such, the approach leads easily to noisy results.
The much more difficult problem in matching arises that, while the contents may look similar, they are fundamentally not the same. For example, you may have a job description for ‘summer trainee’, but the candidate might not necessarily have used the ‘a summer trainee’ as their job description in their CV. This means that if you will use a search engine to find all ‘summer trainees’, you’ll likely miss most candidates.
And an even more difficult challenge arises when you do matching between different languages. For example in the data provided by Teosto we may have a matched entity with the text ‘Pikku Prinssi’ (little prince in Finnish), which should match the media entry with the name ‘Little Prince’. In such a case, using a search engine to find the ‘pikku prinssi’ will simply fail to find the relevant entry. And there are roughly 6500 acknowledged languages in the world...
As such, treating ‘the matching problem’ as a simple and easy search problem (i.e. software engineer for software engineer) can lead to bad results. This will especially happen in domains, where the data is not just non-similar, but fundamentally asymmetric: For example, you may want to match a hammer with nails, instead of other hammers.
The problem worth solving
A possible way in solving the matching problem is using supervised machine learning. If you have enough examples of ‘Pikku Prinssi’ matching ‘the Little Prince’, the machine learning algorithm will pick the pattern, and deliver success.
Still, using the supervised machine learning for matching will fail, when you have more matched items, than examples of matches. This would happen, if you have about 10000 products to match, but only 100 examples of matches. In this case, the supervised learning algorithm would have no data for at least 9900 items, and could not infer anything in 99% of the cases.
As such, matching is a problem worth solving.
To keep the rather abstract matching problem concrete, let’s delve into the problem via the concrete example of Teosto – the Finnish non-profit organization.
Teosto collects music usage license fees for the Finnish music composers and lyricists. As such, Teosto is a rather old company with many processes done on legacy systems, such as IBM mainframes.
Teosto had the problem of matching TV channel’s media use reports to media entries. The underlying issue was that before Teosto can manage the composers’ and lyricists’ fees, they needed to recognize correctly the media the report referred.
For example, Teosto might receive this kind of media report from a TV station:
{
"episode": 25,
"program_name": "PANDA & LITTLE MOLE",
"production_year": 2016,
"season": "",
"episode_name": "MYYRÄ JA PANDA",
"alt_episode_name": "GRANDPA MONKEY’S GLASSES"
}
And we would need to find the following item among approximately one million media entries:
{
"ALTEPISODENAME": "ISOISÄ APINAN SILMÄLASIT",
"ALTORIGNAME": "MYYRÄ JA PANDA",
"CUEEPSNBR": "25",
"CUESNBR": "25",
"CUESOC": "089",
"MEDIA_ID": "089/377226",
"EPISODENAME": "GRANDPA MONKEY",
"ORIGNAME": "PANDA & LITTLE MOLE",
"SEASON": ""
}
While the patterns are clear, the problem setting has a lot of deceitful complexity in it. The problems were the following:
- Often, some of the metainformation was missing (e.g. the season, episode numbers)
- Especially the seasons were mostly missing, which was a serious problem
- The metainformation varied depending on the media type (movie vs series), which lead to special cases
- The fields on the input side and the output side matched fuzzily
- While program_name often mapped to ORIGNAME, it sometimes mapped to ALTORIGNAME instead
- The matching fields often had similar, but not quite the same data.
- On one side the name could be decorated with season, episode numbers and age ratings
- The language could be English on one side and e.g. Swedish on the other
For these reasons Teosto had not been able to use traditional database queries or free text searches for matching. This approach had been tried, but the solution had been disabled because the result quality.
Implementing Aito’s predictive database
In collaboration with Sisua Digital, who was leading this robotic process automation (RPA) prototyping, Aito’s predictive database was used to create 2 separate tables:
- a reports-table, containing 150.000 reports
- and a cue-table, containing 100.000 media entries
The report table contained the basic information about the media entry, the name, alternative name, episode name, alternative episode name, season and the episode number. It also contained the CUE-number identifier, that identified the cue-table entry. The report table’s CUE-number was linked to the cue table. Cue table contained similar information, but often in a slightly different format.
As a reference, the schema definition for Aito was approximately the following:
{
"schema": {
"cue": {
"type": "table",
"columns": {
"CUEEPSNBR": { "type": "string" },
"CUEPYEA": { "type": "int" },
"CUESHNBR": { "type": "string" },
"CUESNBR": { "type": "string" },
"CUESOC": { "type": "string" },
"CUESTNBR": { "type": "string" },
"SEASON": { "type": "string" },
"MEDIA_ID": { "type": "string", "nullable": false },
"ORIGNAME": { "type": "text", "analyzer": "Finnish", "nullable": true },
"ALTORIGNAME": { "type": "text", "analyzer": "Finnish", "nullable": true },
"EPISODENAME": { "type": "text", "analyzer": "Finnish", "nullable": true },
"ALTEPISODENAME": { "type": "text", "analyzer": "Finnish", "nullable": true }
}
},
"reports": {
"type": "table",
"columns": {
"media_id": { "type": "string", "nullable": true, "link": "cue.MEDIA_ID" },
"episode": { "type": "int" },
"program_name": { "type": "text", "analyzer": "Finnish" },
"production_year": { "type": "int" },
"season": { "type": "string" },
"episode_name": { "type": "text", "analyzer": "Finnish" },
"alt_episode_name": { "type": "text", "analyzer": "Finnish" }
}
}
}
In the project, the aim was to predict the reports’ CUE-number. We formulated an Aito query to the _query endpoint to do the matching, which looked approximately like this:
{
"from": "reports",
"where": { // let’s state the known facts in the where -clause
"episode": 13,
"program_name": "SIMPSONS",
"production_year": 0,
"season": "",
"episode_name": "SIMPSONIT",
"alt_episode_name": "7G01 SOME ENCHANTED EVENING"
},
"get": "media_id", // let’s ask for the media entry behind the media_id link
"orderBy": { // let’s order the media entries by the probability lift
"$normalize": { // let’s normalize the values in 0-1 range for easier comparison
"$lift": [ // $lift stands for the probability lift
"CUESHNBR", // the relevant fields are stated explicitly
"ORIGNAME", // for less noise & faster results.
"ALTORIGNAME",
"EPISODENAME",
"ALTEPISODENAME",
"CUEEPSNBR",
"CUESNBR",
"MEDIA_ID",
"CUEPYEA",
"SEASON"
]
}
},
"limit": 1
}
The results looked liked this:
{
"offset": 0,
"total": 938908,
"hits": [
{
"$score": 0.9997762786963816,
"ALTEPISODENAME": "LAPSENVAHTI",
"ALTORIGNAME": "SIMPSONIT",
"CUEEPSNBR": "",
"CUEPYEA": 0,
"CUESHNBR": "41958",
"CUESNBR": "0",
"CUESOC": "089",
"MEDIA_ID": "089/41958",
"CUESTNBR": "0",
"EPISODENAME": "SOME ENCHANTED EVENING",
"ORIGNAME": "SIMPSONS",
"SEASON": ""
}
]
}
II you select “$why” in the Aito query, explanations for the results will be generated (see API docs). Some of the top explanations looked like this (with the returned json turned into more a readable form):
Report feature Lift Cue feature
alt_episode_name:evening -> 16333x -> EPISODENAME:evening
alt_episode_name:enchanted -> 8306x -> EPISODENAME:enchanted
alt_episode_name:some -> 1675x -> EPISODENAME:some
program_name:simpsons -> 121x -> ORIGNAME:simpsons
episode:13 -> 0.5x -> NO CUESNBR:13
production_year:0 -> 1.45x -> PRODYEAR:0
The explanation reveals a feature set that Aito’s predictive database used to identify the correct CUE entry. The lift number describes, how much more likely the correct item has the identified feature. For example the ‘evening’ feature in the episode name makes the match likelihood over 16000 times higher.
Looking at the explanation, it is worth noting that the report has incorrect number (13) in the EPISODE field. The correct episode number is found in the alt_episode_name-field in the “7G01” text. Still, even this piece of information cannot be used, as the CUE data was missing all episode, the season and the production year information, which Aito normally uses to find the correct match. Fortunately, the report’s episode name was unique enough for Aito to identify the episode correctly.
Aito also provides highlights that can be accessed in the “$highlight” field. For simpsons, Aito did highlight every word on 3 different fields:
EPISODENAME: "SOME ENCHANTED EVENING"
ORIGNAME: ”SIMPSONS”
CUEPYEA: ”0”
Other highlights also illustrate the way, how Aito sees the data. Here’s the CUE match for Bron season 3 episode 3:
ORIGNAME: "BRON"
ALTORIGNAME: ”SILTA (16)”
CUESNBRE: ”3”
EPISODENAME: “BRON S3 EP 3”
CUEPYEA: ”2015”
In this case, Aito has used the production year to recognize the correct season, while the correct episode information was found both in the EPISODENAME and in the CUESHBRE fields.
The results
Aito results were evaluated using Aito’s _evaluate end point. The evaluate request looked approximately like this:
{
"evaluate": {
"from": "reports",
"get": "media_id",
"orderBy": {
"$normalize": {
"$lift": [
"CUESHNBR",
"ORIGNAME",
"ALTORIGNAME",
"EPISODENAME",
"ALTEPISODENAME",
"CUEEPSNBR",
"CUESNBR",
"MEDIA_ID",
"CUEPYEA",
"SEASON"
]
}
},
"where": {
"episode": { "$get": "episode" },
"program_name": { "$atomic": { "$get": "program_name" } },
"production_year": { "$get": "production_year" },
"episode_name": { "$atomic": { "$get": "episode_name" } },
"alt_episode_name": { "$atomic": { "$get": "alt_episode_name" } }
}
},
"select": [
"n",
"accuracy",
"meanRank",
"baseMeanRank",
"meanMs",
"cases"
],
"testSource": {
"from": "new-reports",
"limit": 1000,
}
}
In the evaluation, the data was split into separate test and train tables, where the train data was contained in the ‘reports’ table and the test data was contained in separate ‘new-reports’ table.
The evaluation results are visible in the following graph. The graph plots Aito’s confidence values against the measured accuracies. Green line shows Aito’s score for the top match, while the bar’s describe how often the top score was correct. The graph demonstrates that when Aitos’ confidence value was about 50%, approximately 50% of predictions were correct. similarly. When the confidence was 90%, about 90% of the predictions were right.
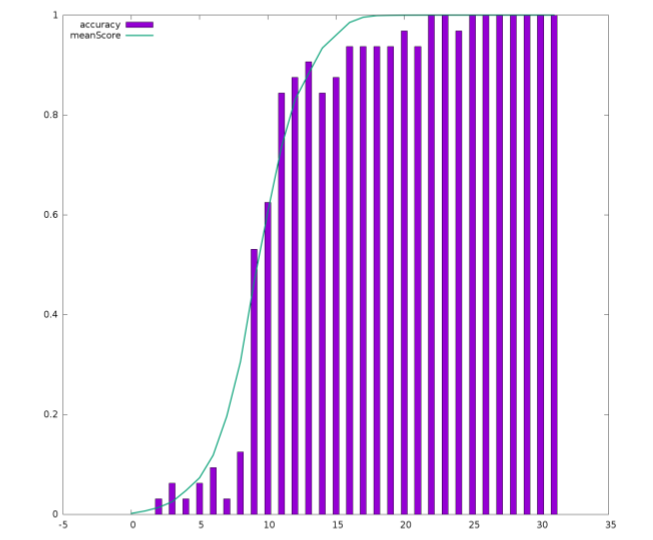
Another important thing was, that Aito could produce 0% error rate for 19% content and on average over 90% accuracy for the next 45% of the material. The results predict that Aito can provide full automation for 19% of the cases, and additional process support for 45% percent of the cases, where Aito’s prediction will be confirmed and possibly corrected by an expert. This implies major time and cost savings in the process for 64% of the cases.
While the results were good, especially given the novelty of the application, we have also identified ways to improve the result. So we are expecting even better results in the near future.
The outcome
Naturally, our Teosto customers and Sisua partners were very happy with the outcome, and our partner Sisua has started the RPA integration of Aito’s predictive database with Teosto’s systems and the daily processes.
Other use cases where the matching capabilities of Aito's predictive database can be used:
- Matching questions with answers
- Matching pieces of text (‘I want a cheap Windows laptop’) with a product
- Matching customers with products
- Matching people with jobs, or with people as in dating
If you are interested of applying Aito to you, don’t hesitate to request a free trial.
Last words
I'd like to thank Kimmo Kauhanen at Teosto. It takes a degree of courage and vision to take the leading steps on the field of AI-assisted process support. Teosto has already laid out plans to take IPA (intelligent process automation) and Aito to transform Teosto into an AI-assisted organization.
I also have to thank Sisua Digital and Jarno Toivonen and Aleksi Hentunen, who took the lead in the project’s implementation. I welcome the readers to contact Sisua to learn and experience together with the masters, how the intelligence process automation is done :-)
I also have to thank Christoffer Ventus from Aito side for providing data science support for the project.
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429







