Introducing a new database category - the predictive database
Antti Rauhala
Co-founder
August 27, 2019 • 9 min read
(Originally published August 2019. Updated September 2020 and March 2026.)
Could machine learning on structured data be made radically more accessible and faster to use? How about, if you could query predictions — classifications, recommendations, missing values — with no training step, using queries like this:
{
"from": "engagements",
"where": {
"customer": "john.smith@gmail.com"
},
"recommend": "product",
"goal" : "purchase"
}
In a typical tech environment it is extremely easy to find applications for predictions on structured data. The end users have gotten used to machine learning-driven features like recommendations, and such features can deliver huge business benefits. There is simply an abundance of ideas and desire to bring predictions to software.
Yet, while machine learning is huge, it can be inaccessible for the average development team. Not every development team is armed with a data scientist. Even more, the traditional model training process is often prohibitively expensive. The image below depicts one way to frame a typical machine learning project. What the picture omits is, that the process can take weeks or months, it can cost tens or hundreds of thousands of euros to get through, and the results are not always what was expected.

Few product teams can spare 'extra 50k€' to try a predictive feature that might improve the product. As a consequence most, maybe over 90%, of the value-adding predictive functionality is not financially feasible.
Given all this, the true question is: could predictions on structured data be made radically more accessible — with no model training step at all?
The Predictive Database
To truly understand the significance of the predictive database, let’s consider the following scenario.
You have a database that provides you the normal database operations for your grocery store. You can use the database to list the historical customer purchases like this:
{
"from": "purchases",
"where": {
"customer": "john.smith@gmail.com"
}
}
Now, your PO has done some interviews and found the customers complaining that filling the weekly shopping list is a huge hassle. What would you do? Perhaps you could use the following query for predicting the customer’s next purchases:
{
"from": "purchases",
"where": {
"customer": "john.smith@gmail.com"
},
"predict": "productIds",
"exclusiveness": false
}
The query results will list the customer’s next purchases by the purchase probabilities, each with a confidence score reflecting the statistical evidence in the data. You can use it to prefill the shopping basket with the weekly butters and milks. It can also be used to provide recommendations.
But there is even more. How about, if you have some impression and click data, and your PO, your customers and the team itself desire the personalized search? Let’s try the following query to recommend ‘milk’ related products:
{
"from": "impressions",
"where": {
"customer": "john.smith@gmail.com",
"product.text": {
"$match": "milk"
}
},
"recommend": "product",
"goal": { "click": true }
}
The query returns the products containing the word ‘milk’ by the probability the customer might click it. If the customer is lactose-intolerant, the lactose-free products will be listed first. As such, the query seamlessly combines the soft statistical reasoning with the hard text search operation to get the sought results.
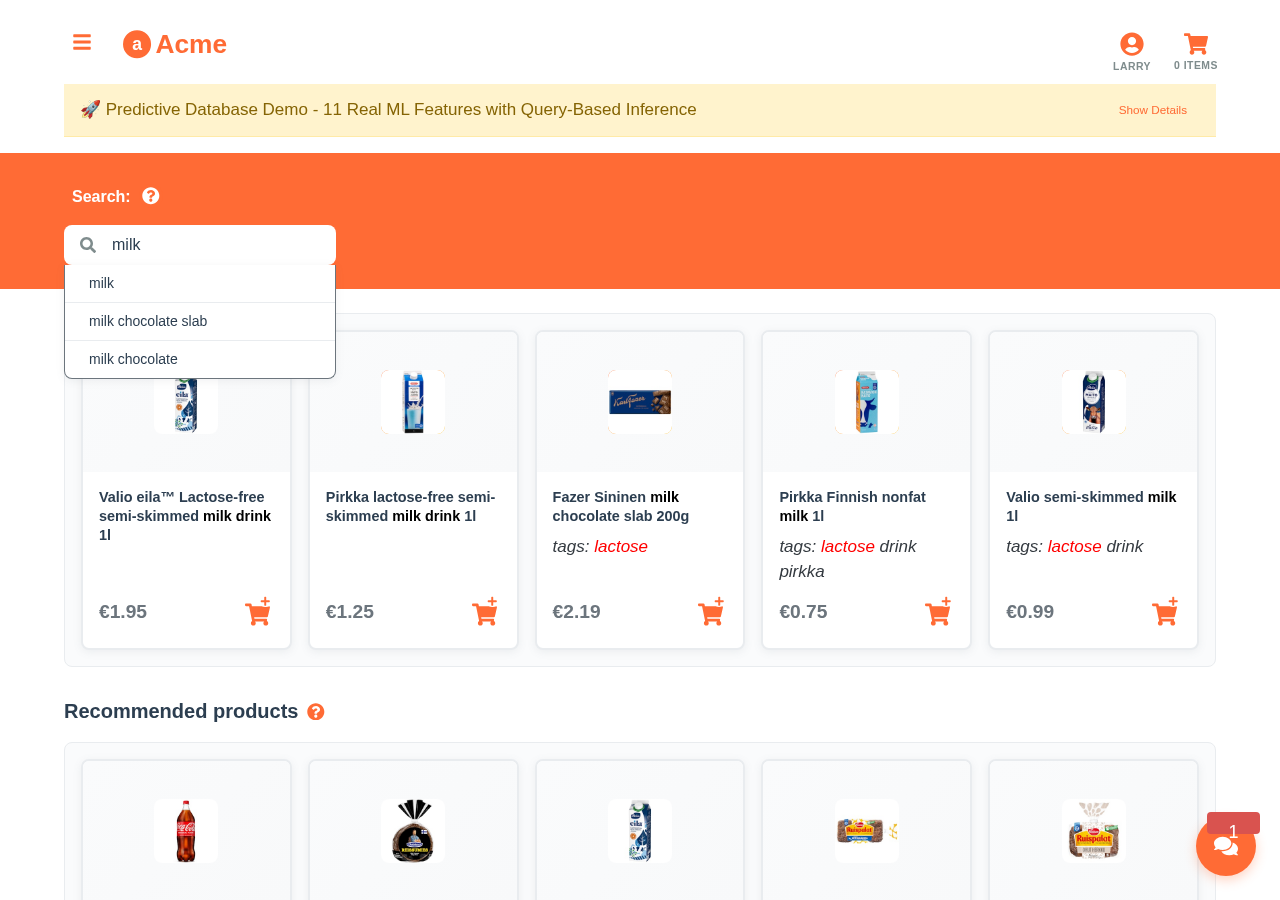
You can try the personalized search and other predictive queries live at demo.aito.ai.
There is a wide array of other prediction problems on structured data that can be quickly solved with queries — with no training step. For example, you can form simple queries to propose tags for products, to propose personalized query words, match email-lines with the products in the database or explain the customer purchases and behavior. As such, these simple queries can provide the intelligent user experience, the process automation and analytics.

The Technology
While the previous examples may sound visionary, we have succeeded in realizing the vision. It occurs, that by integrating columnar inference deeply in a database optimized for structured data, it is possible to optimize the model building to a level, where you can create lazy statistical models in milliseconds. This lets you receive a query, build a model for it, use it, and return an instant response — with no training step. This offers a radically faster workflow and simplified architecture compared to traditional supervised machine learning:
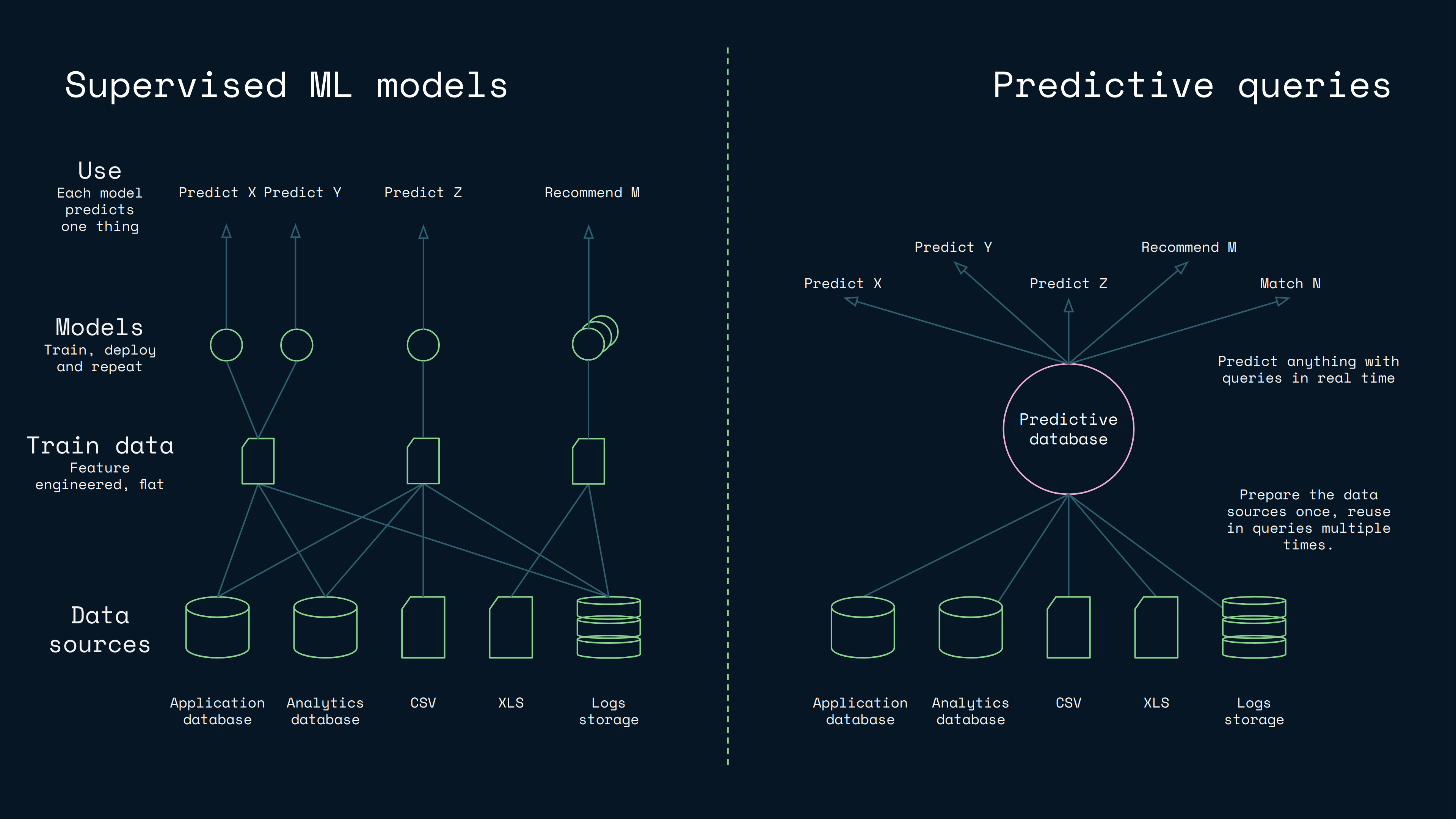
For this reason we have built a custom predictive database, thoroughly optimized for columnar inference on structured tabular data, with a machine learning solution integrated in the database's core. As such, this creates not just a new kind of database category, but also a new kind of machine learner. Instead of needing to train separate models for production, you can query predictions and get instant answers with confidence scores — no model training required.
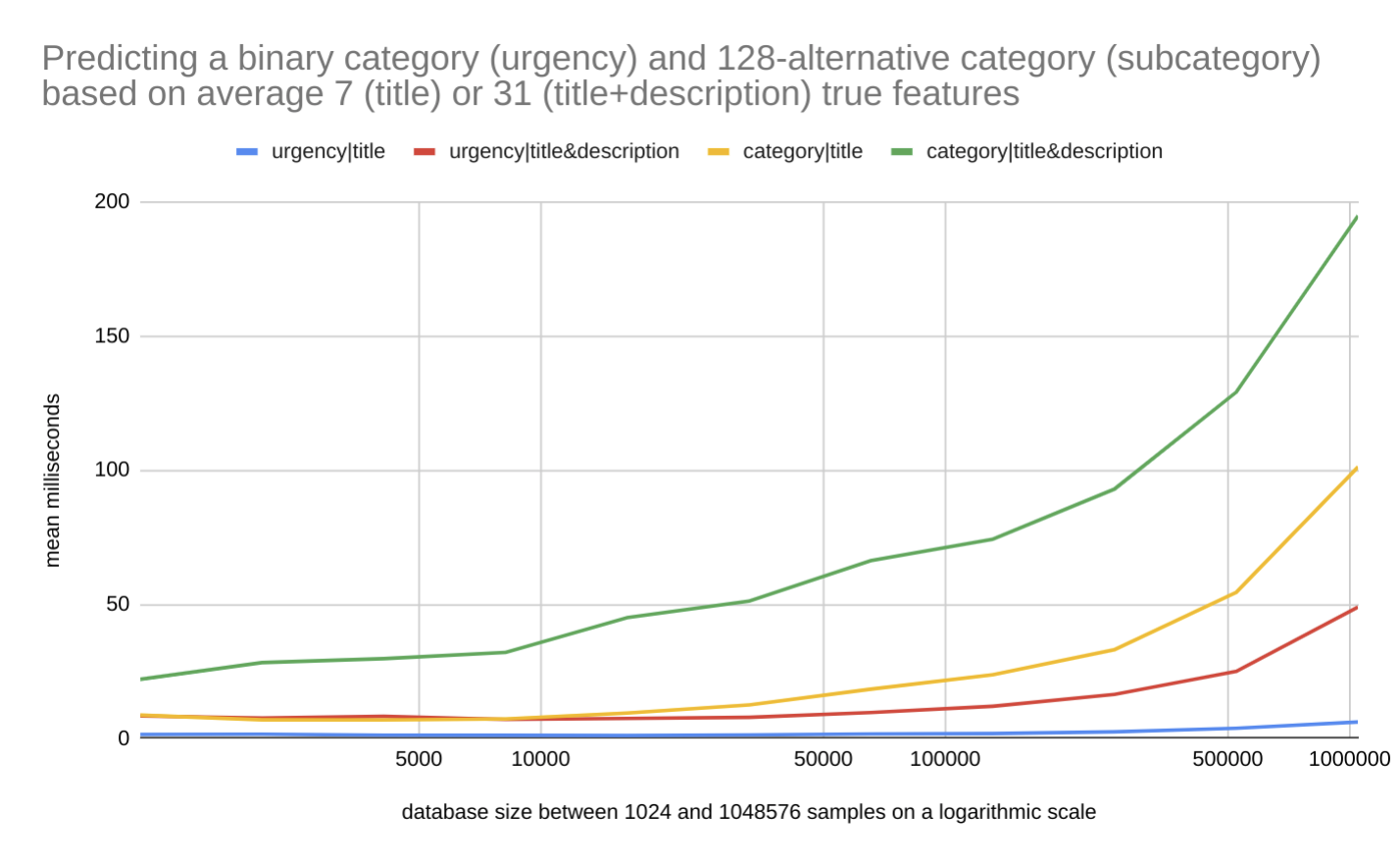
While the lazy machine learning models are created in the millisecond timeframe, the prediction accuracy can remain relatively good. This is explained by the columnar inference approach's ability to model the inference more locally and in a more query-specific manner. The approach is particularly strong in cold-start and low-data scenarios, where traditional supervised models struggle because they lack sufficient training data — the predictive database compensates by leveraging columnar priors across the full data structure. You can read more about this topic in "Could predictive database queries replace machine learning models?" blog post
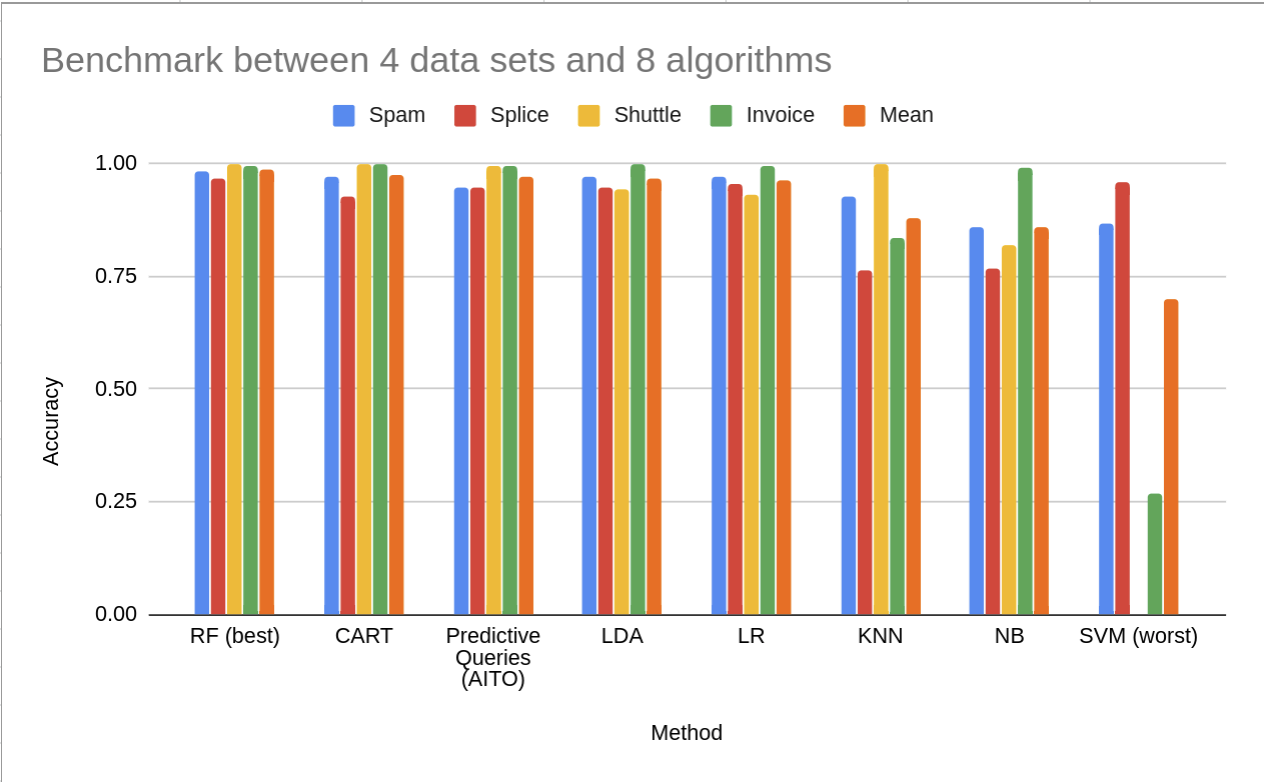
The Impact
The dramatic reduction of cost in implementing predictive functionality — no model training, no ML ops, just queries against structured data — means that it becomes economical to:
- Add predictions into the internal tools, PoCs, the MVPs and the smaller products.
- Add the numerous smaller predictive features, like the little things that help ease the users’ lives.
- Make the software thoroughly intelligent and include predictions wherever they add value.
Overall, the changed economics can work to democratize predictions on structured data and make them affordable; it could fundamentally change how predictions are used in software.
Meet Aito
Aito is the first production implementation of the predictive database. As a predictive database, Aito lets you query predictions on structured tabular data — classifications, recommendations, missing values — using the same query interface you use for data retrieval, with no separate model training step.
Each prediction returns a confidence score grounded in Bayesian inference over the actual data. When the statistical evidence is strong, confidence is high. When the data is ambiguous, confidence drops — and the system tells you so honestly. This calibrated confidence is what makes it possible to build reliable automation on top of predictions.

Aito exists to support developers who value quick time to market, and who are looking for powerful yet simple tools that can solve a wide range of prediction problems on structured data.
What is a predictive database?
A predictive database is a database that lets you query predictions — classifications, recommendations, missing values — using the same query interface you use for data retrieval, without a separate model training step. You upload structured tabular data, and the database handles inference as part of query execution.
The concept is not new. MIT's BayesDB/BayesLite proved the theoretical foundation. Aito is the first production implementation — a predictive database purpose-built for structured data prediction at production latencies.
Does a predictive database require model training?
No. A predictive database requires no training step and no model training. You upload your structured data and immediately query predictions. The database performs columnar inference at query time — building a query-specific statistical model in milliseconds rather than requiring a separate training pipeline.
This eliminates the ML ops surface area entirely: no retraining schedules, no model versioning, no endpoint management. You maintain queries in code, not models in infrastructure.
How does a predictive database compare to LLMs for structured data?
LLMs excel at natural language understanding, reasoning, and unstructured text. But for structured tabular data — transaction classification, recommendation on historical records, filling in missing values based on column correlations — a predictive database is faster, cheaper, and produces calibrated confidence scores that LLMs cannot match.
For a detailed comparison with benchmarks, see Predictive Databases vs LLMs: Choosing the Right AI for Structured Data.
When should you use a predictive database?
Use a predictive database when you have structured historical data, you want predictions based on patterns in that data, and you don't want to build or maintain an ML system. It is particularly strong in cold-start and low-data scenarios — new customers, new product categories, new accounts with few records — where traditional supervised models lack sufficient training data.
For a deeper technical comparison with supervised ML models, see Could predictive database queries replace machine learning models?.
Interested? Check out the documentation to have a closer look, or try the demo workbook to run live predictive queries against structured data.
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429







