Could predictive database queries replace machine learning models?
Antti Rauhala
Co-founder
July 13, 2020 • 20 min read
This post appeared first on Towards Data Science in July 12th, 2020.
One of the greatest trends in today’s technology landscape is the democratization of machine learning. Because the commodity state-of-the-art models, better tooling and better access to hardware: machine learning is becoming an everyday tool in the companies’ toolbox.
The ML democratization is still an on-going trend and given the disruption in this space it’s worth asking: where will this transformation take us? What the future of the everyday ML will look like?
Predictive queries are an interesting take on machine learning, especially in the ML democratization context. Solutions like MIT’s BayesDB/BayesLite and Aito provide a way to get arbitrary predictions instantly with SQL-like queries. As an example, here’s a predictive query in Aito:
{
"from": "invoice_data",
"where": {
"Item_Description": "Packaging design",
"Vendor_Code": "VENDOR-1676"
},
"predict": "Product_Category"
}
As such: the predictive queries seem like an easier, faster and radically different way to do machine learning. They give a glimpse of a future, where anyone can do machine learning as easily as one does database queries.
This article gives a brief introduction to the predictive queries, and it compares the predictive queries to supervised learning through 3 different aspects that are:
- The workflow, comparing the easiness and the costs between predictive queries and supervised machine learning
- The architecture, comparing the high level differences between using predictive queries and using supervised models
- And the qualitative properties (scaling, accuracy) as the quality is an obvious concern for an emerging, if promising, technology.
Introduction to the predictive queries
Predictive queries resemble normal database queries with the exception that they provide predictions about the unknown, while the traditional database queries provide facts about the known. Here’s an example of the BQL (Bayesian Query Language) query done against BayesDB/BayesLite database:
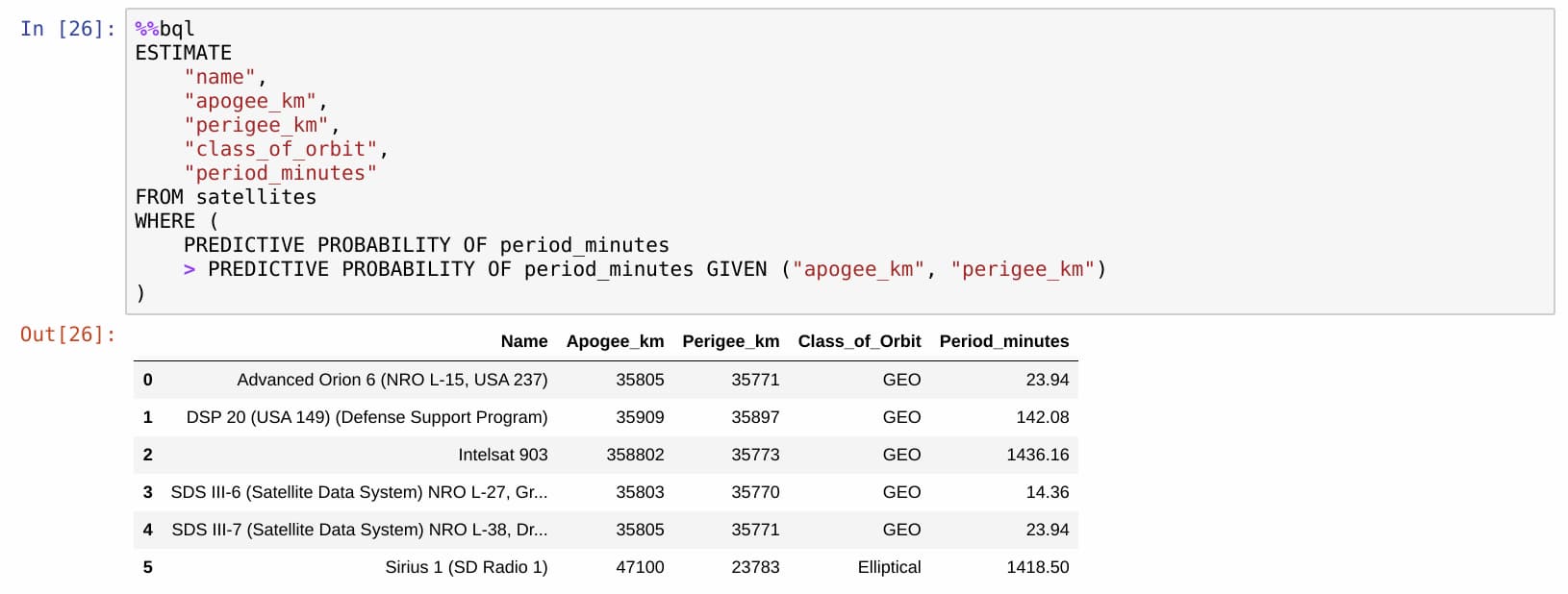
In essence, the predictive queries can provide a very SQL-like alternative to the supervised ML models with the key differences that:
-
While supervised machine learning models need to be configured, trained and deployed before usage, the predictive queries provide instant answers after the database is prepared with data. As such: the predictive queries have a different workflow.
-
While supervised machine learning is always specialized for a single prediction from A to B, predictive queries can be used a) to instantly predict any unknown X based on any known Y and b) to provide also recommendations, smart search and pattern mining. As such, the supervised models are narrow, while the predictive queries are multipurpose, which has implications on the architecture.
-
While with the supervised machine learning the narrow models are explicitly formed train time, the predictive queries do multi-purpose modeling write time or narrow modeling during query time. As such: the predictive queries are technically more challenging.
Only few solutions exist, that provide such predictive queries. One is the mentioned BayesDB/BayesLite, which creates an in-memory multi-purpose models in a special preparation phase. Another solution is Aito.ai, which does query-time narrow modeling without explicit preparations. Here’s is an example of the Aito workflow:
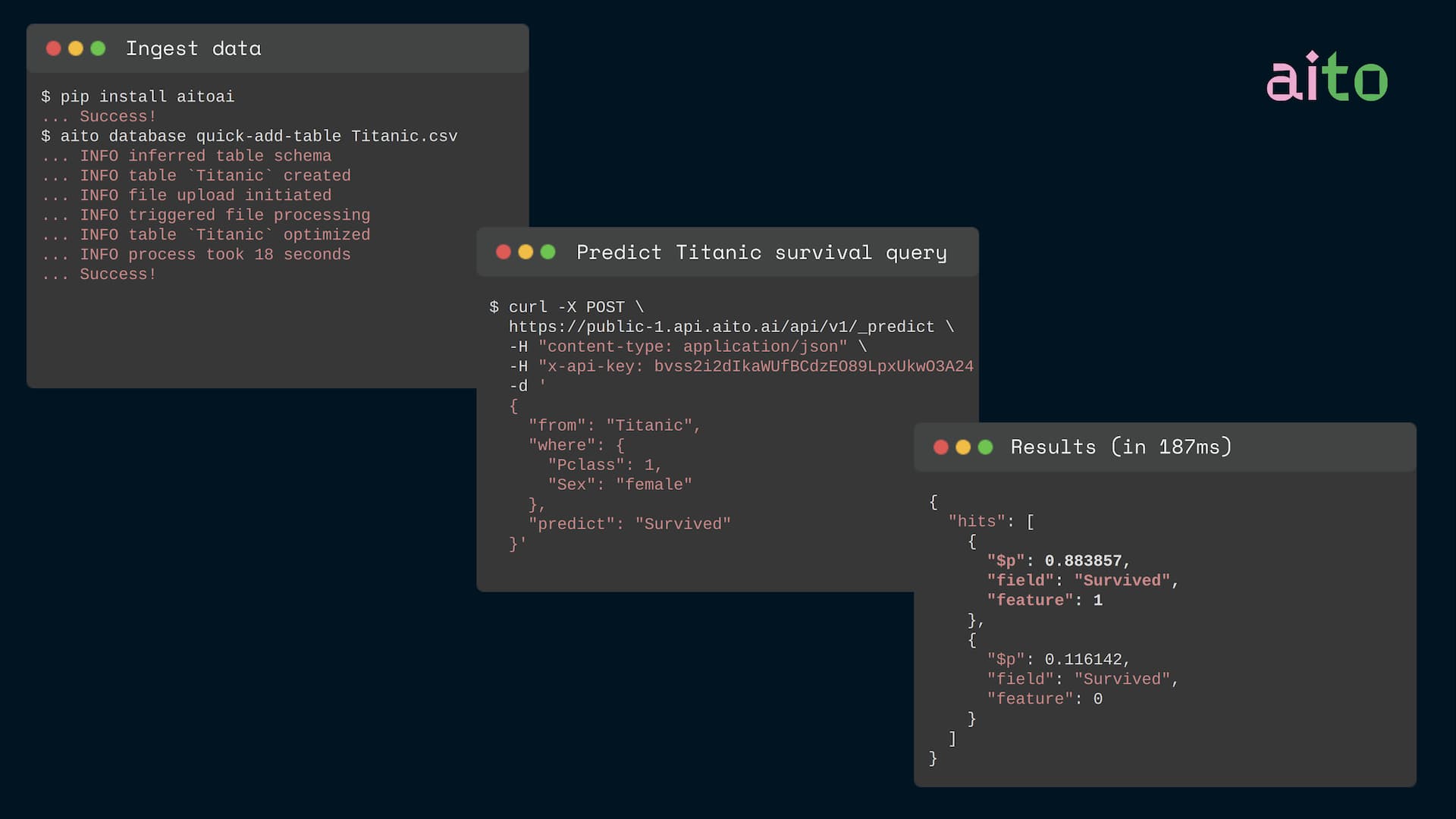
We are focusing the following comparisons on Aito. We feel this focus is justified as in Aito we are more familiar with the solution, and it is mature enough to serve the end customers in live production settings. While BayesLite is extremely impressive and their BQL interface and DB/ML integration are worth envy: BayesLite seems to have properties like the 16 minute preparation phase for simple data, which are not consistent with the presented arguments.
So let’s next dig deeper on the difference in workflow, architecture and quality between the predictive queries and supervised ML models.
1. The Workflow
The first difference between predictive queries and the traditional supervised models relates to the workflow and the costs.
Supervised ML models are deployed typically in data science projects, which have several steps like the handover to the data scientist, data preparation, feature engineering, model fitting, deployment, integrations, retraining and monitoring & maintenance. As an addition to this linear progression, you also often have an iteration phase, where the results are improved by refining the data, the preparations, the features, the models, the deployment or the integrations.

Taking a supervised model to production may take several weeks or months from one to two persons. This can raise the price point up to hundred thousand euros per model. If you need several models, you need several data science projects, leading to multiplied expenses and delays.
Now this process changes rather dramatically, if you implement the machine learning functionality with predictive queries. With predictive queries the workflow is in essence the following:
- Prepare the auxiliary predictive database once (if it’s not used as the main database)
- Verify good enough prediction quality with evaluate requests
- Integrate the predictive queries like you would integrate SQL queries
- Write the test/evaluation cases, push these to Git and let the CI handle the regression testing
- If seen as necessary: track the in-production prediction quality with analytics and display the metrics in the product dashboard.

While putting an auxiliary database (like ElasticSearch) into production can take weeks, the expense related to putting each query into production is closer to the expense of using search/database queries. Often such queries form only a small part of the related functionality’s expense, and often the query based functionality can be implemented in hours and put into production in days.
This dramatic difference between the workflows and the expenses are explained a) partly by the predictive database’s AutoML capabilities that are accelerated by a specialized database and b) partly by the reduced need for deployments and integrations as the data and the ML are already integrated into a single system. The complex phases of the data science project get systematically eliminated or simplified:
- The handover of the data science project to the data scientist is not needed as the predictive query workflow is easy enough for the software developers.
- Data preparation and feature engineering steps can be greatly eliminated with the ML-database integration. You don’t need to re-prepare and re-upload the data, if the data is already in the database. You don’t need to manually aggregate data into flat data frames, if you can do inference through the database references. You don’t need to manually featurize text either, as the predictive database analyzes the text automatically just like ElasticSearch. Last: you don’t need to manage feature redundancies, if the database has built-in feature learning capabilities.
- Modeling phase can be automated with a single sophisticated model that provides good enough results for most applications.
- Per model cloud deployment, live integrations and retraining of models simply disappear, because you don’t need to ‘deploy’ or retrain the predictive queries. Instead you integrate one auxiliary predictive database like you would integrate ElasticSearch. If you use the predictive database as your main database, you can omit even that one integration.
- Maintenance is easier, because instead of maintaining deployed infrastructure for each prediction target, you maintain the SQL-like queries like you would maintain code with Git & CI.
As a consequence, the workflow and the cost of implementing ML via predictive queries is similar to the process of implementing normal business logic via SQL.
2. The Architecture
The second difference between the predictive queries and the supervised models is the narrowness and it’s implications on the software architecture.
Famously: the supervised ML models are narrow in 2 different respects:
1.Narrowness of the prediction setting. Supervised learning models are essentially narrow functions from A (e.g. text) to B (category), which means that if you have 10 different problems, you end up with with 10 different supervised ML models. 2. Narrowness of the predictive functionality type. A single kind of supervised method can typically serve only one kind of predictions. For this reason you often need completely separate systems or products to implement predictions, recommendations, smart search and pattern mining.d up with with 10 different supervised ML models.
This combined narrowness has negative implications on the architecture. If you have 10 different predictive functionalities that mix prediction, recommendation and smart search use cases: you end up struggling with a very complex system. The system may include separate supervised model platform with half dozen deployed models, separate recommendation system, a separate smart searching product and separate pattern mining tools. Such complexity is hard to learn, master and maintain. Smart search and content based recommendation engines often replicate large parts of the database, which leads to redundancy. The systems may also not integrate well with each other and they may end up in inconsistent states, where the smart search may return old information and the recommendations and the predictions may ignore new products and data.
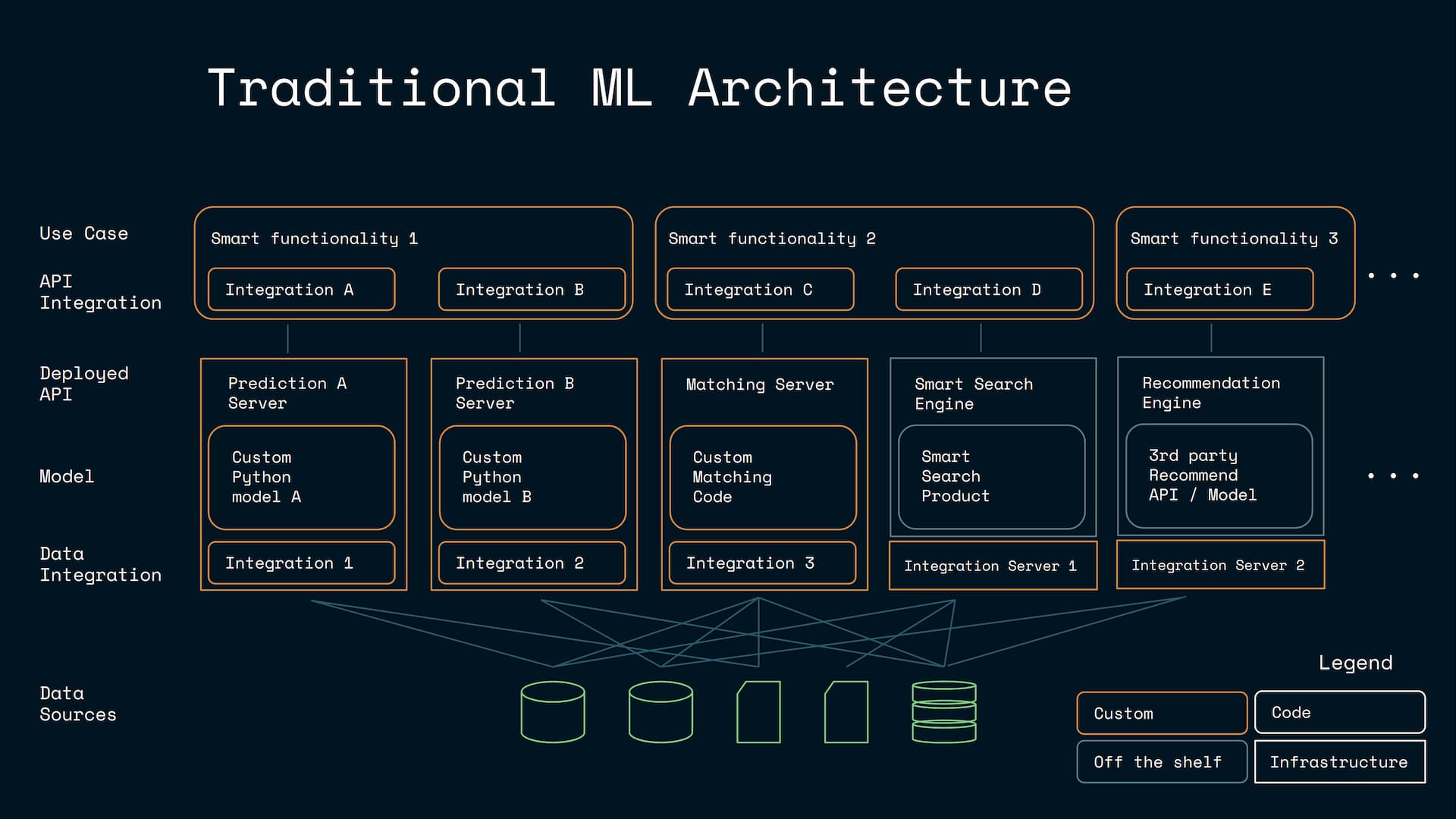
On the other hand, it can be argued that the predictive queries are inherently multipurpose and non-narrow in both respects. First of all: predictive queries do not have a fixed prediction setting and they don’t require 10 separate model deployments for 10 different problems. The 10 problems may need 10 predictive queries, which is an obvious advantage: while creating and maintaining 10 different supervised ML models can be hard, most software engineering projects do not struggle in creating, comprehending and maintaining tens or even hundreds of SQL queries.
Second, regarding the narrowness of the prediction type: for predictive databases the multipurpose nature emerges naturally from the rather inevitable design choices in such systems. To a degree it emerges for the same reasons multi-purposeness emerges in the traditional databases: a database cannot know the query beforehand so by its design it must be ready to serve any generic need. This drives the design choices in general to be generic rather than specific.
As a less obvious yet inevitable design choice: it is the text-book Bayesian / probabilistic approaches that fit best the fast statistical computations that make the predictive databases possible. This is evident in both BayesLite and the Bayesian Aito. At the same time, such a solid mathematical foundation is very easy to generalize further to create a multipurpose predictive system, as it’s evident in both of these systems. Both BayesLite and Aito provide a wide portfolio of intelligent functionality.

In the case of Aito, the Bayesian mathematics were generalized to serve not just predictions, but also recommendations. Because the search mathematics is based on a Bayesian Binary Independence Model and a predictive database needs to index all text to function: extending the Bayesian Aito to serve traditional search, matching and personalized search use cases was only natural. Also using the text book mathematics to enable explainable AI was extremely simple. Adding pattern mining support to a system, which needs fast pattern mining to even function, was almost inevitable. On the other side: BayesLite complements Aito’s feature portfolio with wide analytical capabilities, SQLite’s extensive database functionality and an impressive ability to generate data.
So similarly as databases are extremely multipurpose and versatile with the known data, the predictive databases can be extremely multipurpose and versatile with the unknown data. Now, if you combine both the traditional database and the predictive database capabilities, you will create even more multipurpose system that can flexibly serve all the knowledge related needs covering both the known and the unknown.

As a consequence for a single application: perhaps you only need one predictive database to serve all your needs. You get the queries, natural language searches, predictions, recommendations, smart searches etc. from a single source. No additional server deployments, custom models or data integrations are needed as everything is served from the single database. The redundancy, consistency and the interoperability issues also disappear, because all functionality is based on the same transactional data.
The predictive query oriented architecture is also more consistent with the industry best practices. Replacing prediction servers with queries help replacing infrastructure with queries/code as in serverless computing, and separate the concerns around the data (in the database) from the queries/code (in Git). Replacing multiple redundant data integrations with a single integration is consistent with the DRY principle and the approach allows reuse of old data integrations. Using off the shelf solutions is often preferred over creating custom solutions to avoid reinventing the wheel and not invented here anti patterns. Overall, the approach reduces the amount of maintained code, infrastructure and complexity and it is consistent with the good old software architecture goals and principles.
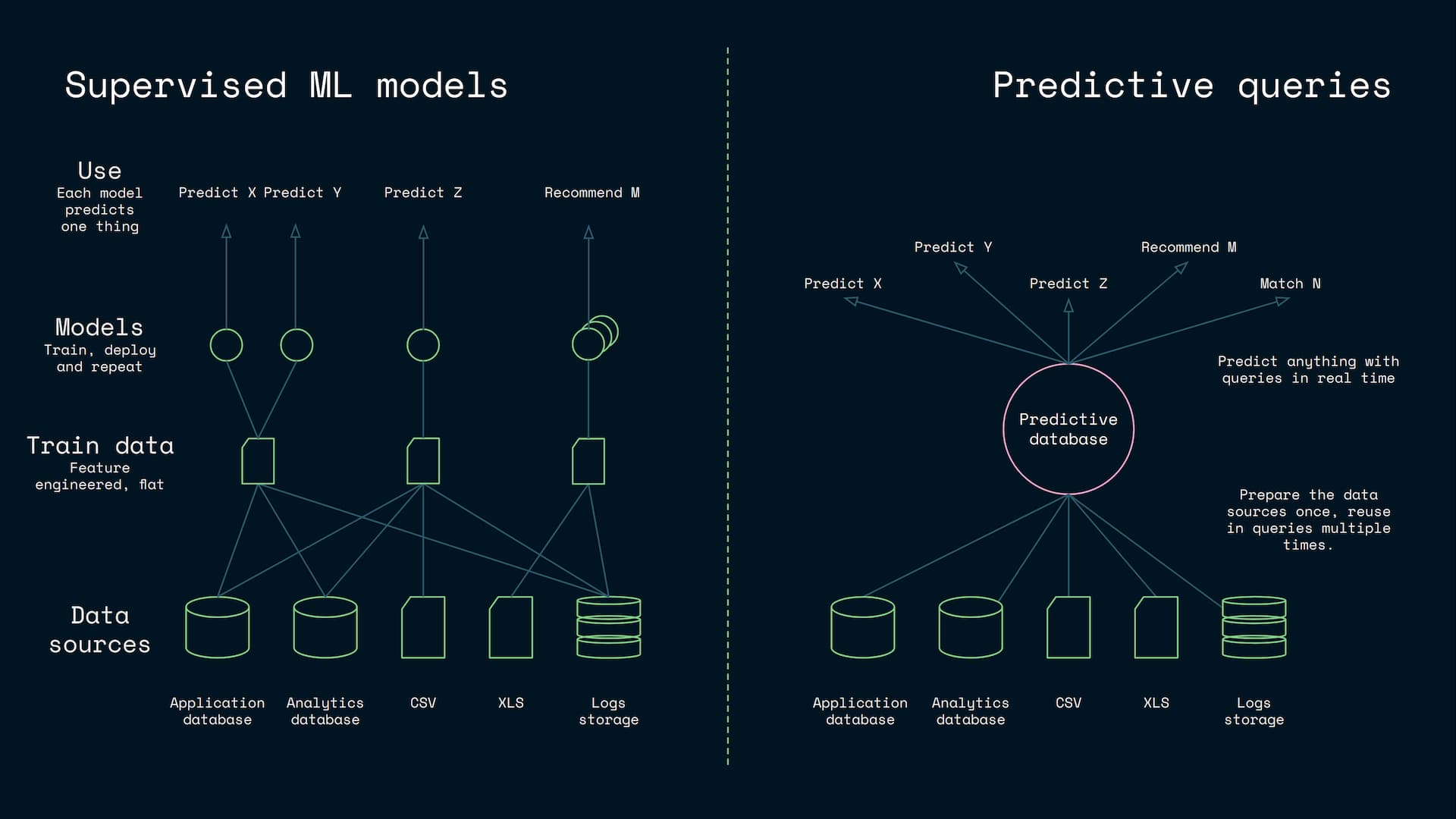
As such the predictive query/database oriented approach is a radical departure from the traditional approach with wide implications on the industry. Just as a thought play: if you have a database that can answer queries of both the known and the unknown: why would you maintain a separate normal database on the side or deploy a multitude of redundant ML models/systems?
3. The Quality
In the early days of AI, you could see people envisioning a predictive database like system. One vision was McCarthy’s idea of the epistemological part, which would combine machine learning, knowledge representation and reasoning in a seamless way. This epistemological part was essentially a model for the world, which would be used to query both the known and the unknown as with a predictive database. Still, this vision never fully realized for a rather obvious reason: creating a query based statistical reasoning system is extremely challenging both algorithmic and performance wise.
The fundamental problem is that predictions always need a model, but if you don’t know the prediction specifics beforehand you are left with 3 rather challenging options:
- ‘World model’, where you create one general purpose model that can serve arbitrary queries. Here the problem is that it’s extremely hard to create one universal ML model to serve arbitrary predictions in general and it’s even harder if you don’t want to degrade the write/preparation performance.
- Lazy learning, where you train a separate supervised model for each query at the spot. Here the challenge is that creating a high quality model query time is extremely hard without degrading the query latency and throughput.
- The third and intuitively most sound option is to combine both approaches as this should provide not only the best results, but also the best write and query speed trade-off. On the negative side, it also combines the challenges of the both previous approaches.
BayesLite is a good example of the ‘world model’ approach. It creates an in-memory general purpose model in the extra ‘create population’, ‘create analysis’ and ‘analyze’ steps. While the approach is elegant, the modeling step can take over ten minutes even with limited data sets, which illustrates well the sacrifice on the write/preparation time side. Still, it’s likely that the preparation speed could be improved drastically by using a more specialized database (BayesLite is based on SQLite) and a different algorithm (query time representation learning can be accelerated to millisecond scale as in Aito, which implies that fast write-time preparation should also be possible).
On the other hand, Aito uses the lazy learning approach, in which the performance hit occurs at query time. I’m going to focus next on how we solved some of the inherent performance challenges with this approach.
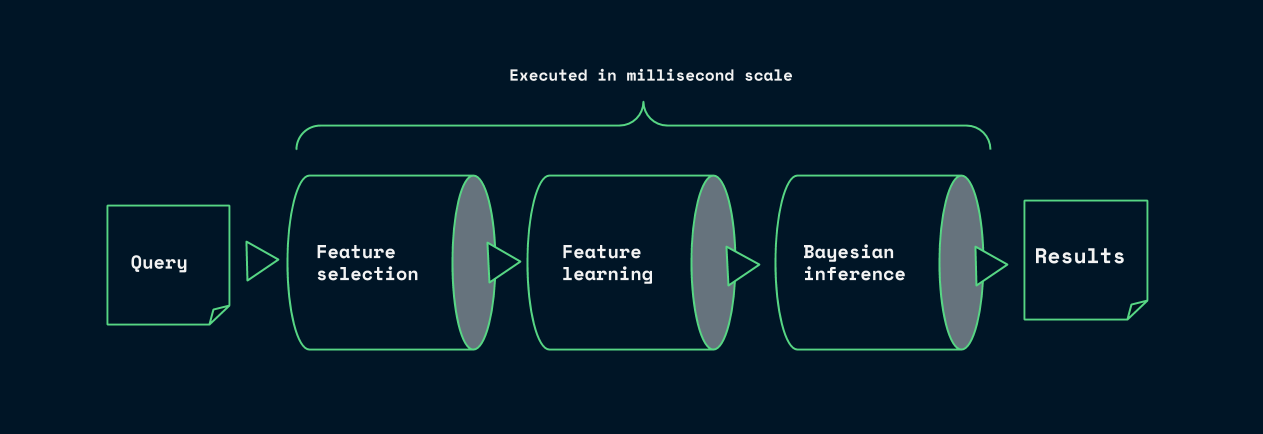
In essence, creating the lazily learned model for a specific query typically requires 1) warm and fast data structures for a few hundred query specific features 2) a few thousand relevant statistical measurements and 3) a few thousand relevant samples per interesting feature/examination. To serve these needs in the millisecond scale Aito 1) has fast prepared data structures for every possible feature, 2) uses specialized indexes for counting full database statistics in the microsecond scale and 3) has specialized data structures to enable sub millisecond sampling of data.
As a consequence: the predictive queries can often be served in the milliseconds scale as visible in figure 1. You can find more information about the benchmark in this notebook.
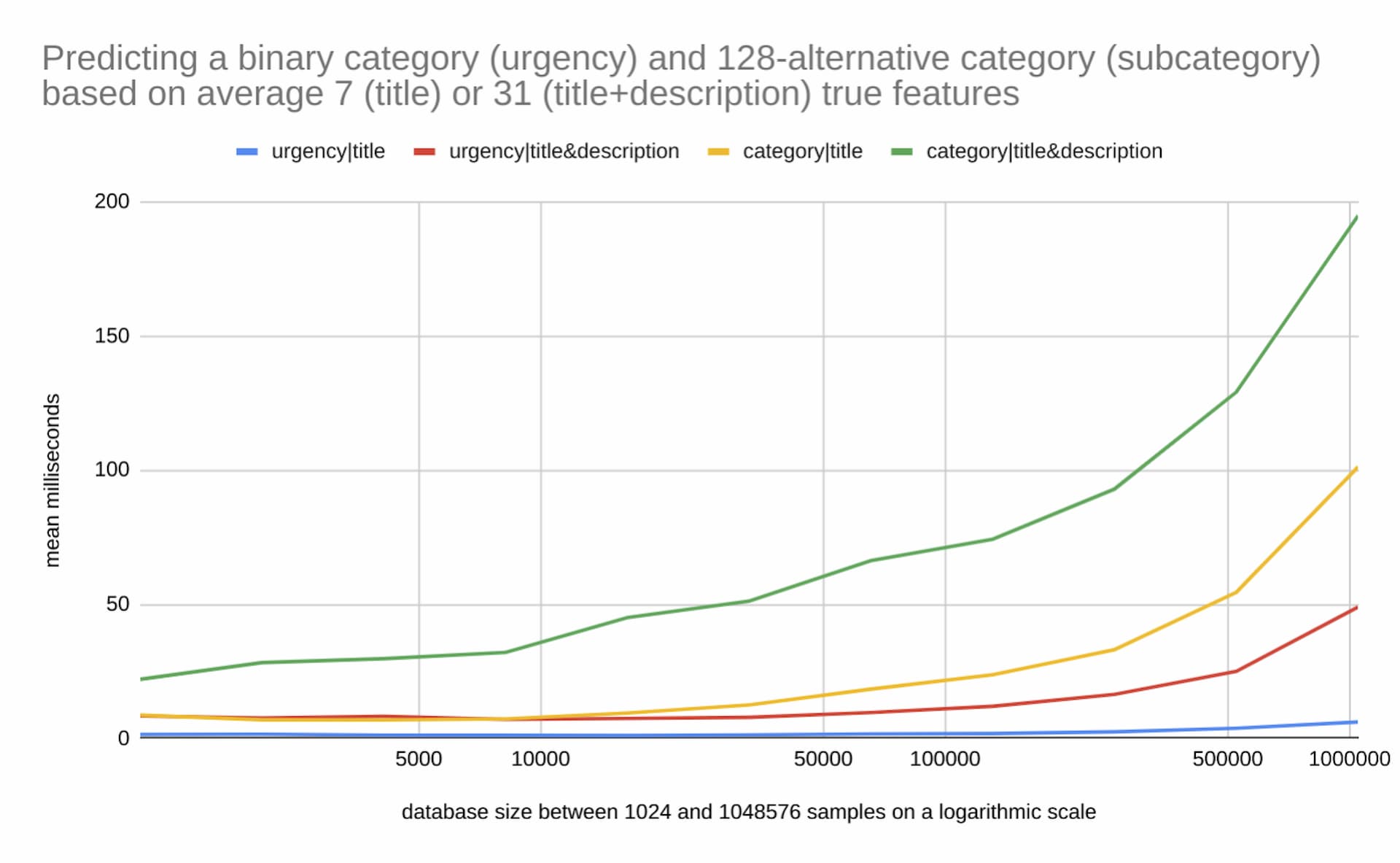
While most prediction can be served with low latencies: because Aito currently uses full database statistics, there is an O(N) component to Aito’s scaling. This means that once you start approaching million data points: the performance degrades. Also, the amount of the known features in query and the amount of the alternatives in the predicted category affect the performance as visible in the graph.
Currently, these performance characteristics put certain limitations on Aito’s possible uses as the latency and throughput may suffer with big data sets and complex inference. Still, it is worth noting that also the supervised machine learning performance and resource requirements often start to degrade in the million sample scale or e.g. in the 10k sample scale for the benchmarked SVM implementation. Aito query performance is also more than good enough for applications, where the datasets are limited, and the latency and throughput requirements are looser as in the internal company tools, the PoCs/MVPs, the background processes, the intelligent process automation and the RPA.
While the performance quality is good enough for many uses, we do expect it to be radically better in the future. The early experiments with even more specialized database structures imply that writes speeds and sampling speeds can be still made up to 10-50 times faster. This could let the predictive database to have a) a write performance, which is comparable (or better) to search databases, b) much better scaling as the sampling based inference scales more O(1) than O(N)-like and c) hugely improved prediction speed. In the future, integrating the ‘world model’ approach by doing write-time feature/representation learning could bring the prediction speed even closer to what we see in traditional supervised learning in exchange for some decrease in write performance.
Last, but not least: let’s consider the prediction quality. In this benchmark, we compared Aito to 7 ML models including random forest over 4 different classification data sets with discrete data (Aito doesn’t do regression).
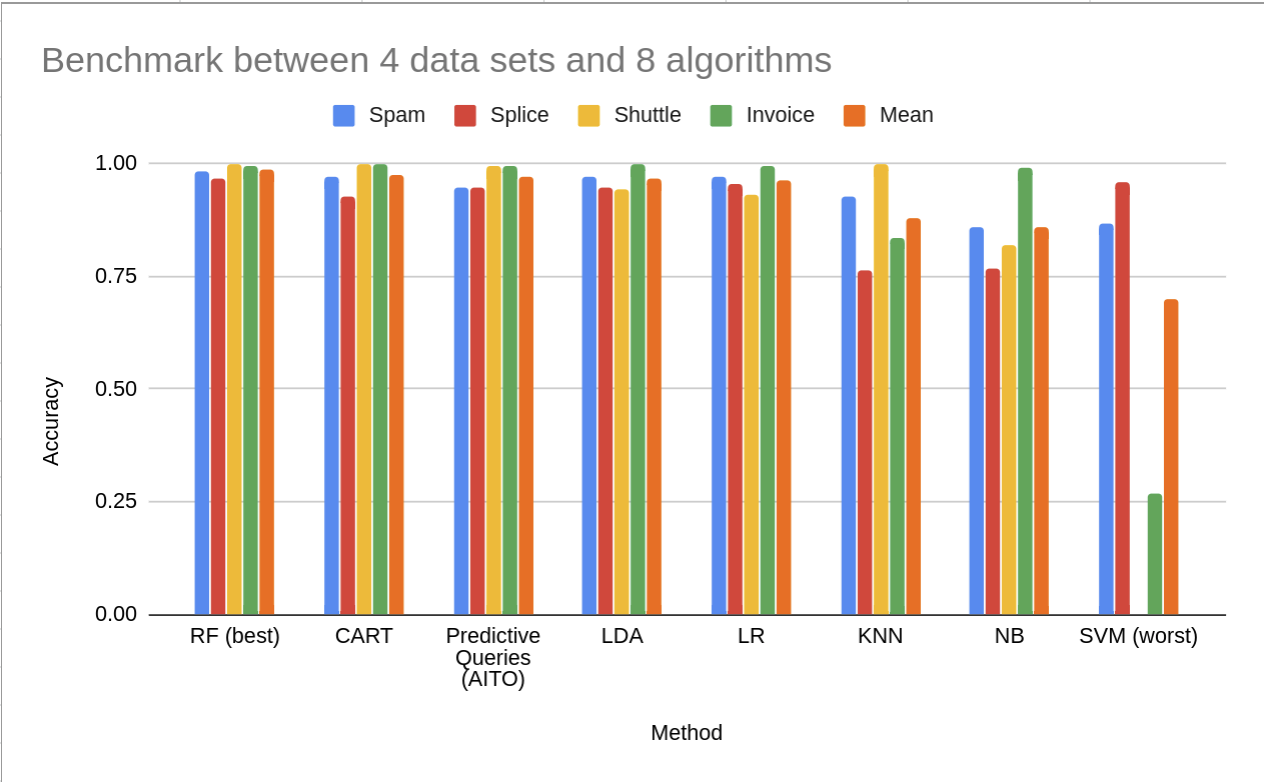
Like we see in the benchmark, the lazy learning approach produces very good prediction quality despite the millisecond scale budget to train the predictive model.
Creating a good lazy model in the millisecond scale is feasible, because creating a specific model to serve a specific prediction is radically faster than creating a generic model to serve a generic prediction. Like mentioned before, the training phase doesn’t need to consider every million features and million samples available, but only a few hundred features and a few thousand samples relevant for the query. The reduced complexity together with a specialized database enables serving moderately sophisticated query specific models instantly.
Lazy learning can also be surprisingly good, because the model is fine tuned for a single prediction. A traditional supervised model may discard rare features and ignore rare patterns in the data to limit the model complexity, which becomes a problem, when the prediction must be based on rare features. With the predictive queries the problem simply disappears as the query time training allows selecting the features and the model specifics that fit best each individual query.
It is also worth noting, that databases contain a wealth of metadata. The company ID may refer to an entire company table, which metadata can be used in predictions via Bayesian priors. There are also database-friendly mechanisms like analogies (which is already implemented in Aito), which can assume that the relations like (‘message has Bob’, ‘receiver is Bob’) and (‘message has John’, ‘receiver is John’) to have a shared structure (‘message has X’, ‘receiver is X’) and shared statistical behavior. Such techniques could improve predictions by utilizing data and patterns unavailable to traditional approaches.
This all raises the question that through the various techniques: could the predictive queries reach not only the parity, but a superior performance compared to the best supervised ML models in many practical applications?
The Conclusion
As such the predictive queries can turn the machine learning field upside down by…
- …replacing the expensive workflow of supervised ML with much faster workflow resembling the workflow associated with database queries…
- …and replacing the complexity of narrow supervised models and products with one multipurpose system and SQL-like queries…
- …while maintaining a competitive performance and prediction quality compared to the supervised learning.
As a consequence of these 3 factors: it is conceivable that the predictive queries would replace most supervised ML models in the real world applications in the future. This is implied by a simple thought experience: if you can get predictions instantly from the database: why would you spend weeks productizing and integrating redundant supervised models?
Also, it is conceivable that the predictive queries/databases will emerge as the main drivers of the machine learning democratization. As thought experiments: if doing ML is database query like, then why couldn’t any developer do ML? And also: if the ML based functionality cost becomes similar to the database based functionality cost, why couldn’t ML be used in every company, in every project and in every functionality like the databases are?
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429







