Introducing a new database category - the predictive database
Antti Rauhala
Co-founder
April 25, 2026 • 9 min read
(Originally published August 2019. Revisited April 2026.)
Could machine learning on structured data be made radically more accessible and faster to use? How about, if you could query the predictions, the recommendations and other AI / ML functionality, with no training step, with queries like this:
{
"from": "engagements",
"where": {
"customer": "john.smith@gmail.com"
},
"recommend": "product",
"goal" : "purchase"
}
In a typical tech environment it is extremely easy to find applications for predictions on structured data. The end users have gotten used to machine learning-driven features like recommendations, and such features can deliver huge business benefits. There is simply an abundance of ideas and desire to bring predictions to software.
Yet, while machine learning is huge, it can be inaccessible for the average development team. Not every development team is armed with a data scientist. Even more, the traditional model training process is often prohibitively expensive. The image below depicts one way to frame a typical machine learning project. What the picture omits is, that the process can take weeks or months, it can cost tens or hundreds of thousands of euros to get through, and the results are not always what was expected.
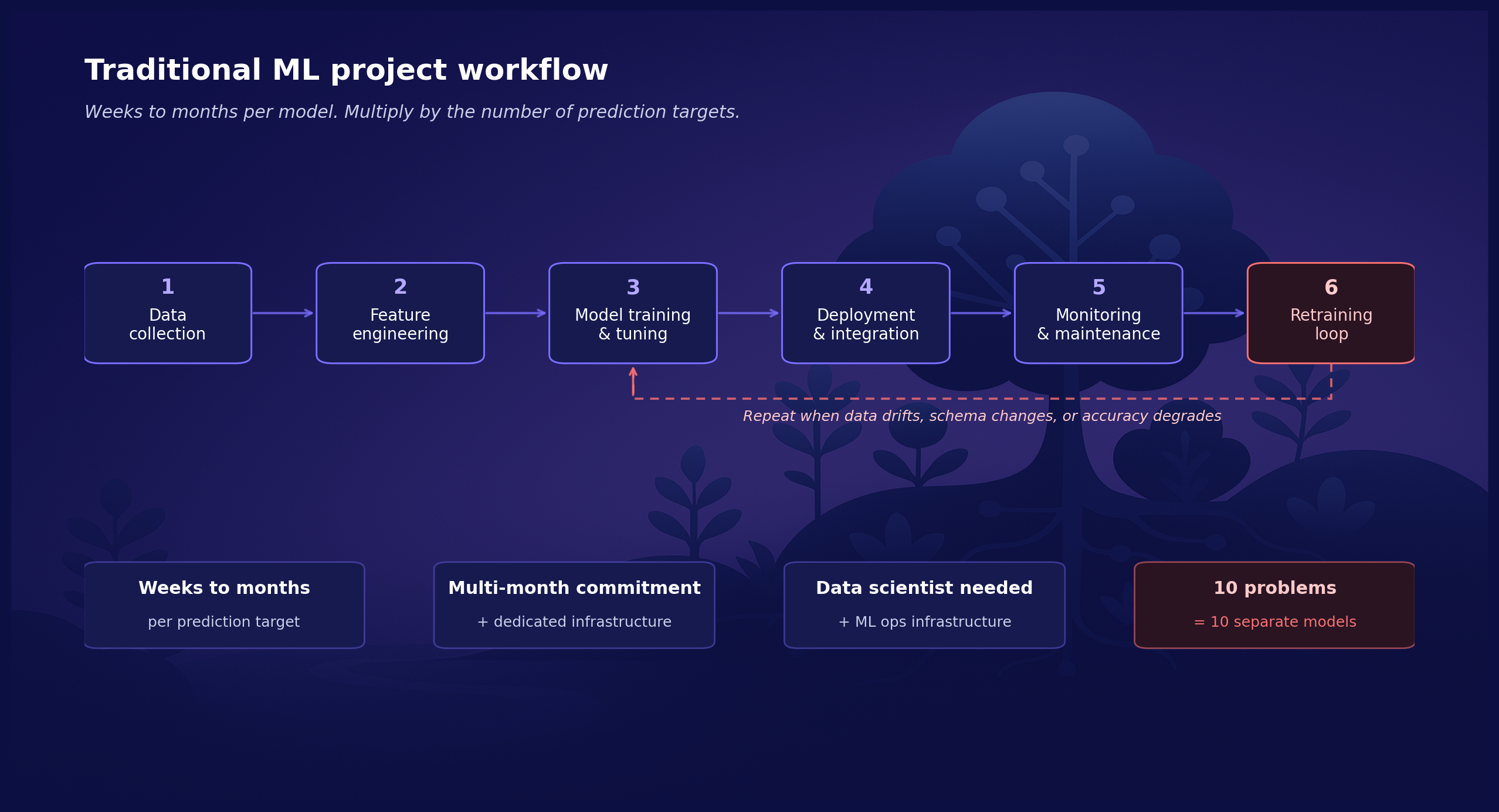
Few product teams can spare an 'extra two months' to try a predictive feature that might improve the product. As a consequence most, maybe over 90%, of the value-adding predictive functionality is not feasible to even attempt.
Given all this, the true question is that could predictions on structured data be made radically more accessible, with no model training step at all?
The Predictive Database
To truly understand the significance of the predictive database, let’s consider the following scenario.
You have a database that provides you the normal database operations for your grocery store. You can use the database to list the historical customer purchases like this:
{
"from": "purchases",
"where": {
"customer": "john.smith@gmail.com"
}
}
Now, your PO has done some interviews and found the customers complaining that filling the weekly shopping list is a huge hassle. What would you do? Perhaps you could use the following query for predicting the customer’s next purchases:
{
"from": "purchases",
"where": {
"customer": "john.smith@gmail.com"
},
"predict": "productIds",
"exclusiveness": false
}
The query results will list the customer’s next purchases by the purchase probabilities. You can use it to prefill the shopping basket with the weekly butters and milks. It can also be used to provide recommendations.
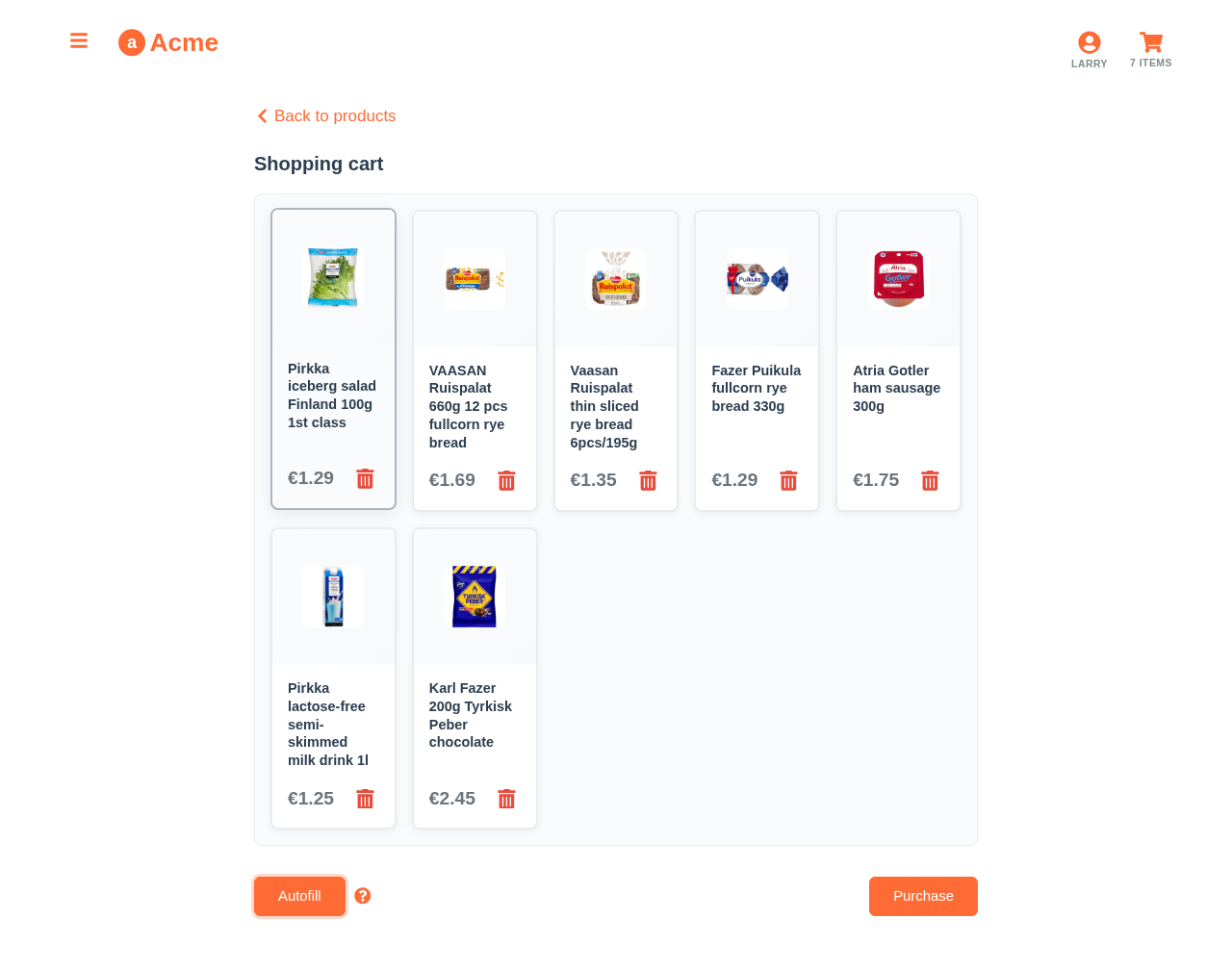
But there is even more. How about, if you have some impression and click data, and your PO, your customers and the team itself desire the personalized search? Let’s try the following query to recommend ‘milk’ related products:
{
"from": "impressions",
"where": {
"customer": "john.smith@gmail.com",
"product.text": {
"$match": "milk"
}
},
"recommend": "product",
"goal": { "click": true }
}
The query returns the products containing the word ‘milk’ by the probability the customer might click it. If the customer is lactose-intolerant, the lactose-free products will be listed first. As such, the query seamlessly combines the soft statistical reasoning with the hard text search operation to get the sought results.
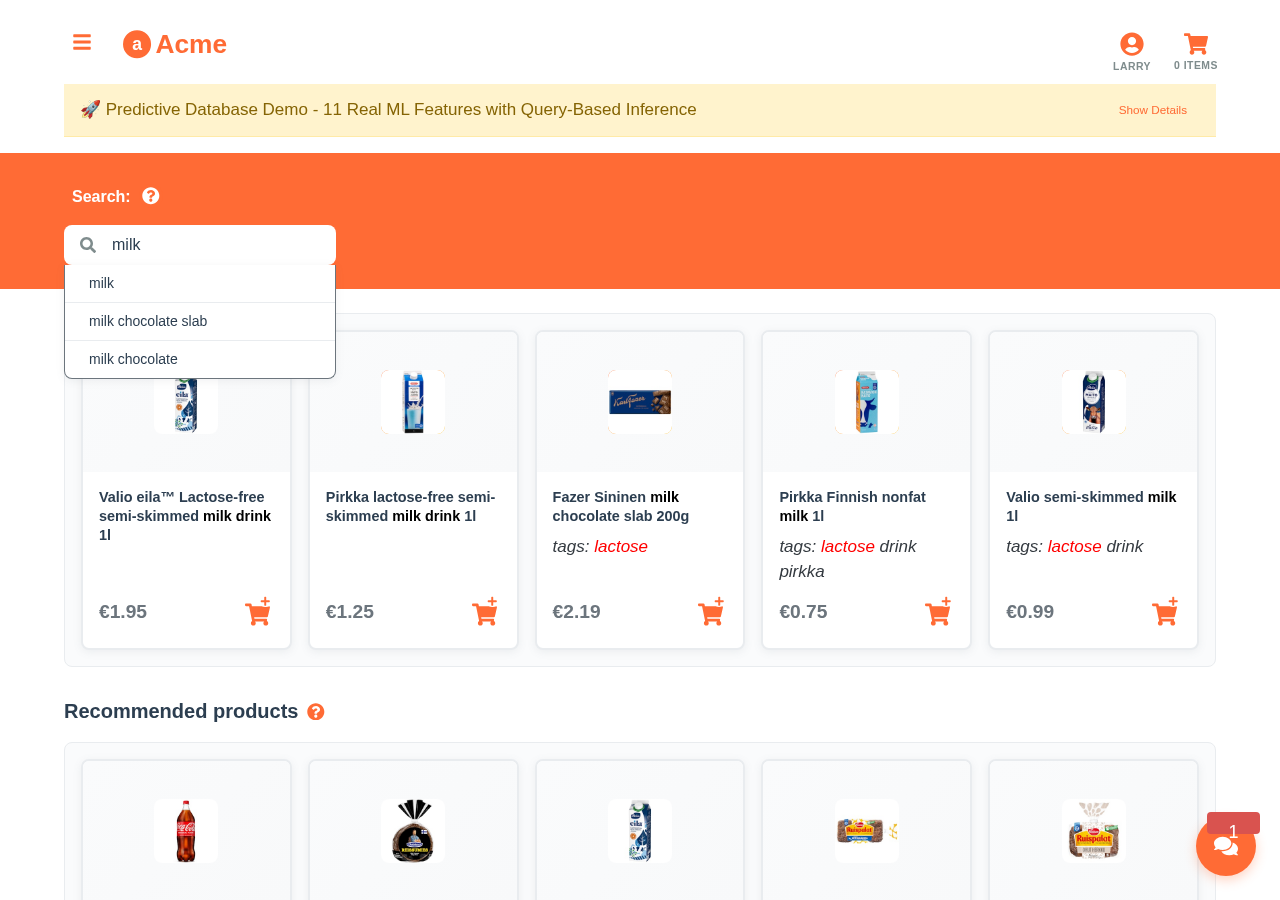
You can try the personalized search and other predictive queries live at demo.aito.ai.
There is a wide array of other prediction problems on structured data that can be quickly solved with queries. For example, you can form simple queries to propose tags for products, to propose personalized query words, match email-lines with the products in the database or explain the customer purchases and behavior. As such, these simple queries can provide the intelligent user experience, the process automation and analytics.
The Technology
While the previous examples may sound visionary, we have succeeded in realizing the vision. It occurs, that by integrating columnar inference deeply in a database optimized for structured data, it is possible to optimize the model building to a level, where you can create lazy statistical models in milliseconds. This lets you receive a query, build a model for it, use it, and return an instant response. This offers a radically faster workflow and simplified architecture compared to traditional supervised machine learning:
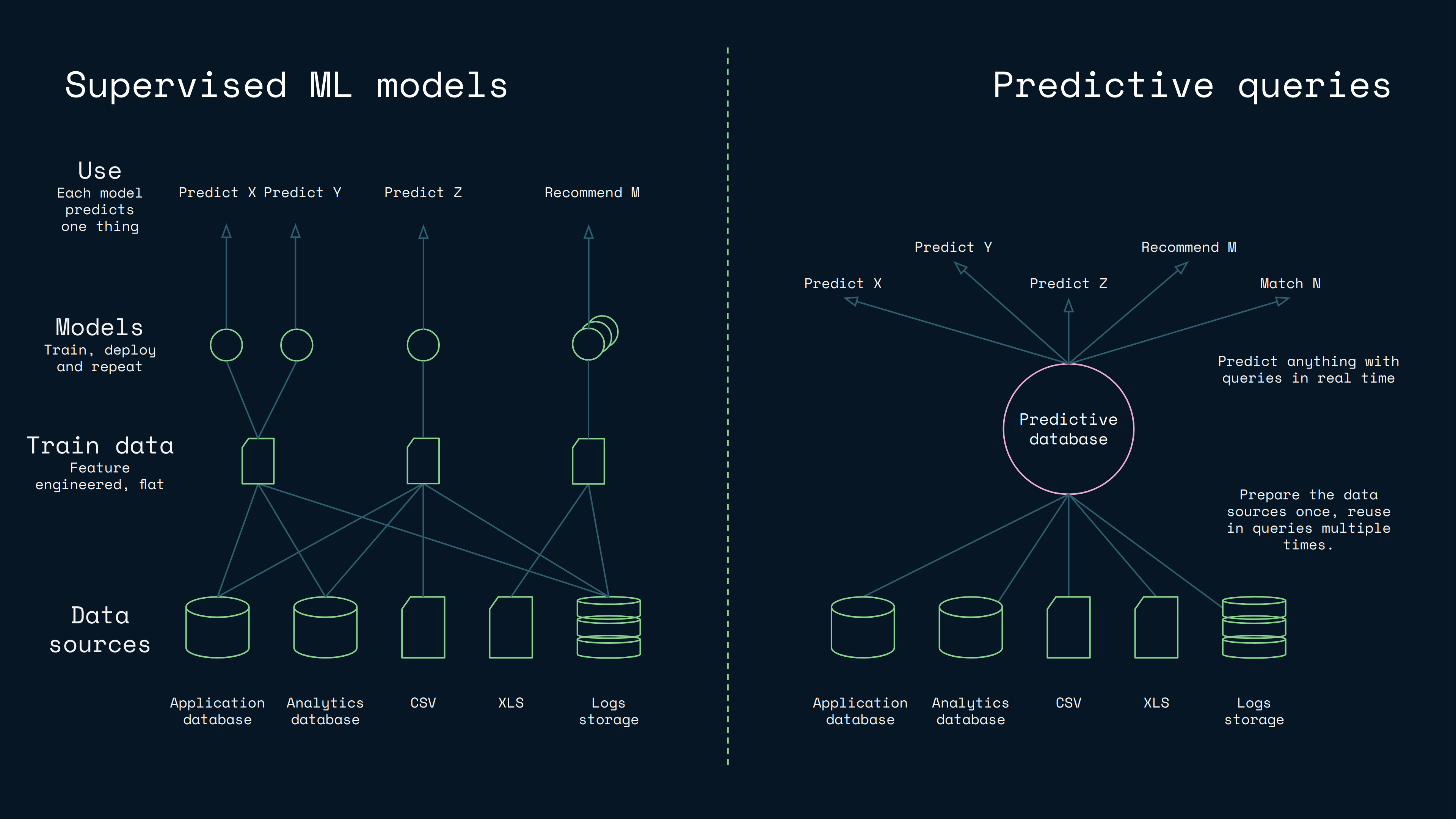
There is no separate training step, because the inference is computed at query time over a columnar index built at the ingest. The work has not vanished, it has moved from a periodic batch process into the database itself.
This works, because columnar inference models the prediction more locally and in a more query specific manner. This is also why the predictive databases hold up in cold-start: the database leans on Bayesian priors over the metadata already present in any database, like the column distributions, the cross-column correlations and the hierarchical structure. You can read more about how the priors work in "Why Aito Predicts Accurately with Little Data", and for a deeper comparison with the supervised ML models, see "Could predictive database queries replace machine learning models?".
The Impact
So, the predictive database is a database optimized for ad-hoc inference: you choose what to predict and from what for each query. But now: what are the practical implications and the impact of such technology?
When a prediction is a query rather than a project, it becomes economical to:
- Add predictions into the internal tools, PoCs, the MVPs and the smaller products.
- Add the numerous smaller predictive features, like the little things that help ease the users’ lives.
- Make the software thoroughly smart and pick the predictive features from the menu wherever they fit.
Overall, the changed economics can work to democratize the predictions on structured data, and they could fundamentally change the way the predictions are used in software.
Meet Aito
This vision of the predictive database was implemented by our startup called Aito, and it is the first production implementation of the category. The concept is not new: MIT's BayesDB / BayesLite proved the theoretical foundation, and the in-database ML extensions in PostgreSQL (MADlib), Snowflake (Cortex) and BigQuery (BQML) cover the narrower scopes of the same idea. Aito is the first one purpose-built for the full category, the predictive queries on the structured tabular data, with no training step at the user's level, at production latency.
As a predictive database, Aito lets you query the predictions on the structured tabular data (the classifications, the recommendations, the missing values) using the same query interface you use for the data retrieval, with no separate model training step. Aito is offered with the flat-rate plans and a free Sandbox tier (see the pricing).
Today, four customers run Aito in production: two on the invoice automation through a partner, one on the retail price estimation and one on the financial transaction categorization.
At 100K rows, LightGBM trains three models in about 40 minutes. Random Forest takes about 100 seconds. Aito takes zero, because there is no training step. Any change in the data that would force a supervised pipeline to retrain is just there in the next query.
In a multi-tenant invoice routing benchmark over 100 simulated companies, Aito with priors averages 49.5% accuracy. The supervised baselines, all hyperparameter-tuned, sit in the low-30s: the LightGBM 33.4%, the Random Forest 28.9%. On the hardest target, the processor prediction with ~63 candidates per company, Aito reaches 11% at cold start against the LightGBM's 2.5%. Roughly seven times the random baseline.
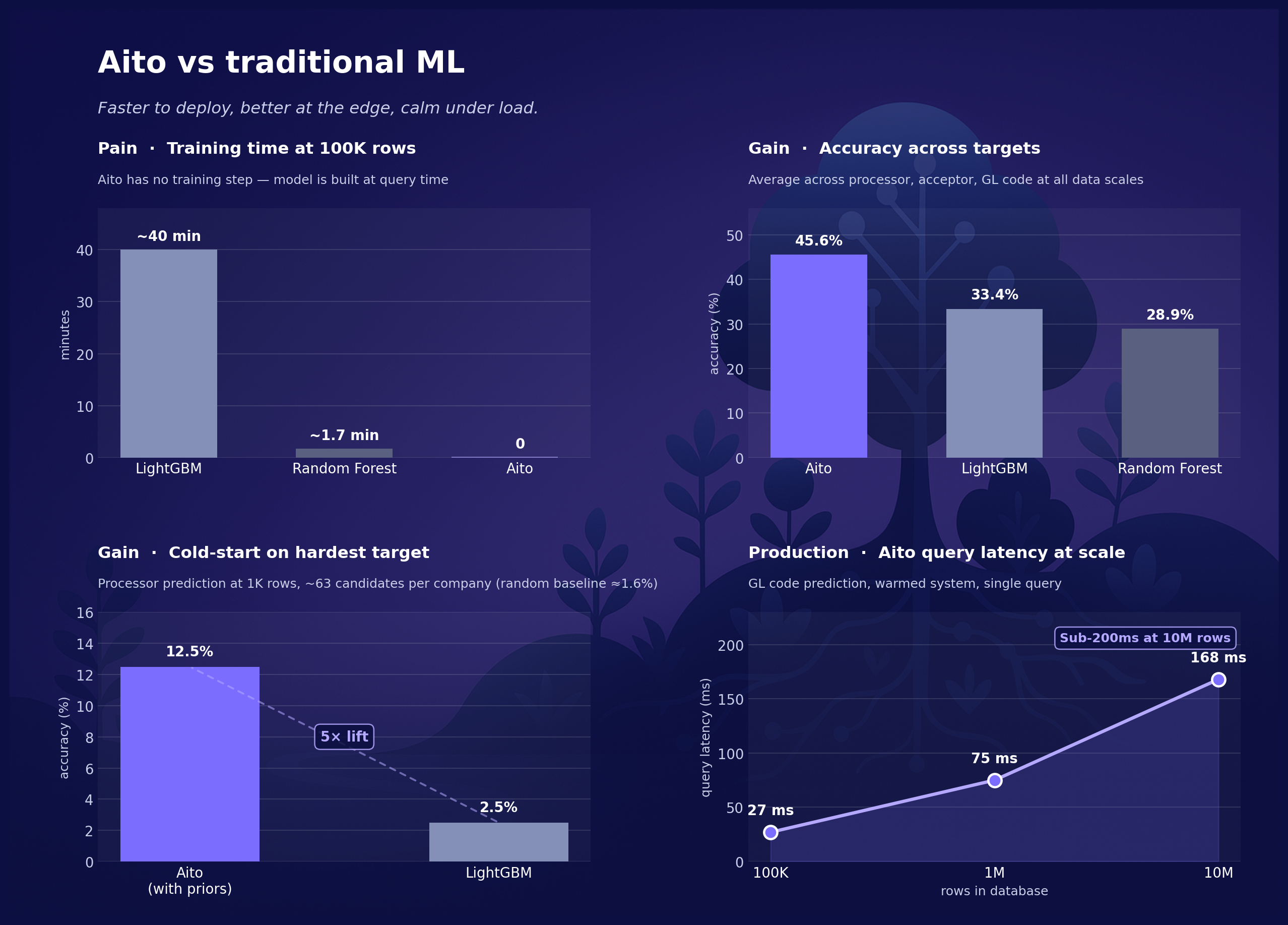
Each prediction comes with a confidence score, grounded in the Bayesian inference over the actual data. When the statistical evidence is strong, the confidence is high. When the data is ambiguous, the confidence drops, and the system says so. The calibration is what makes the predictions safe to automate on. It is also where the most LLM-based approaches to the structured prediction fall down.
The predictions used to cost a project. Now they cost a query.
Interested? Try the live demo at demo.aito.ai, or check out the documentation to have a closer look.
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429







