Using the predictive database
#predictivedatabase
#machinelearning
Antti Rauhala
Co-founder
August 27, 2019 • 4 min read
In our previous blog post, we introduced the new database category: predictive database.
The predictive database was proposed as a solution to the question: "How to make AI be made radically more accessible and faster to use?". AI queries like these were proposed as the answer:
{
"from": "engagements",
"where": {
"customer": "john.smith@gmail.com"
},
"recommend": "product",
"goal" : "purchase"
}Now we’ll go deeper into how to use the predictive database or more specifically Aito, our implementation of the concept.
How to get started?
Aito was designed to feel familiar to the developer audience and it can be used like any database.
You need to do 3 things to get results from Aito:
- Define the database schema
- Upload the json data
- Send a simple query
So as a first step let's get familiar with the Aito database schema. The JSON schema syntax was inspired by ElasticSearch:
{
"schema": {
"messages": {
"type": "table",
"columns": {
"content": { "type": "Text" }
}
}
}
}Aito supports some basic datatypes like numbers, booleans, strings and text. Text can be analyzed, and columns can link to other tables. Read more about the Aito schema definitions here.
Now, you can send the schema definition to Aito with a simple HTTP PUT request:
curl -X PUT "https://$AITO_ENVIRONMENT.api.aito.ai/api/v1/schema" \
-H "x-api-key: $API_KEY" \
-H "content-type: application/json" \
-d@schema.jsonThe next step is the data upload. The JSON data can be uploaded with a simple POST request, as in most APIs:
curl -X POST \
https://$AITO_ENVIRONMENT.api.aito.ai/api/v1/data/messages/batch \
-H "x-api-key: $API_KEY" \
-H "content-type: application/json" \
-d '
[
{ "content": "Hello world" },
{ "content": "A second message" }
]'In the third step, we execute the query. The query syntax was inspired by both SQL and MongoDB, and it should be familiar for most developers. The simplest possible query looks like this:
{
"from": "messages"
}Let's send the query to Aito's search end point.
curl -X POST \
https://$AITO_ENVIRONMENT.api.aito.ai/api/v1/_search \
-H "x-api-key: $API_KEY" \
-H "content-type: application/json" \
-d '{
"from": "messages"
}'The query simply lists the contents in the 'messages' table, as visible in the below results:
{
"offset": 0,
"total": 2,
"hits": [
{ "content": "Hello world" },
{ "content": "A second message" }
]
}Using Statistical Reasoning
Let’s next look at a bit more complex example called the ‘grocery store demo’. You can find the demo application here.
It has 3 smart functionalities, that are:
- recommendations,
- personalized search and
- automatic tagging of products.
Let’s consider the first functionality, the recommendations. To understand the functionality, we must first understand the problem, so let’s look at the following screenshot:
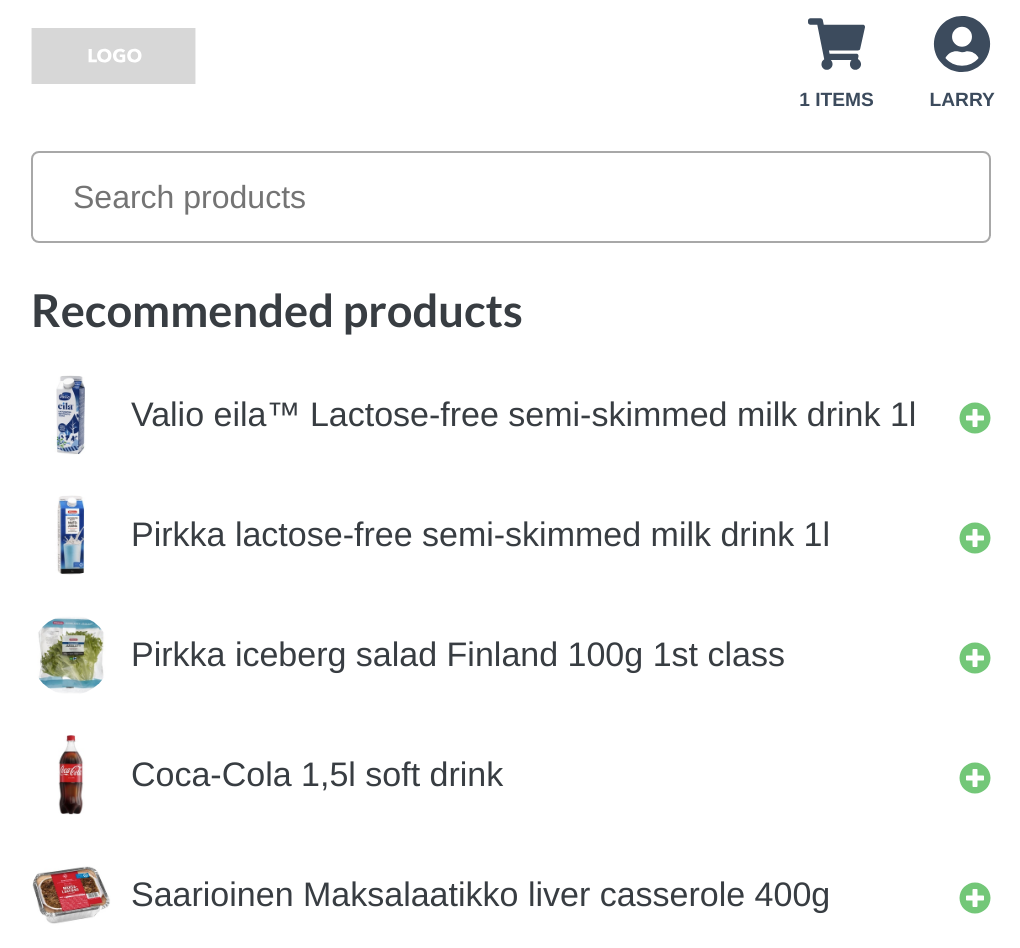
The screenshot describes visually the problem setting, where the grocery store needs to recommend the customer (Larry) products, that customer doesn’t yet have in his shopping basket.
The query is presented in the following image. The query consists of a json object containing fields like’ from’, ‘where’ and ‘limit’, that remind of the SQL queries, while the ‘where’ clause resembles MongoDB:
{
"from": "impressions",
"where": {
"session.user": "larry",
"product.id": {
"$and": [
{ "$not": "6409100046286" }
]
}
},
"recommend": "product",
"goal": {
"purchase": true
},
"limit": 5
}Aito responds to the query with the following JSON:
{
"offset": 0,
"total": 41,
"hits": [
{
"$p": 0.38044899845646235,
"category": "104",
"id": "6408430000258",
"name": "Valio eila™ Lactose-free semi-skimmed milk drink 1l",
"price": 1.95,
"tags": "lactose-free drink"
},
{
"$p": 0.20982669270272708,
"category": "104",
"id": "6410405216120",
"name": "Pirkka lactose-free semi-skimmed milk drink 1l",
"price": 1.25,
"tags": "lactose-free drink pirkka"
},
{
"$p": 0.04097576026274742,
"category": "100",
"id": "6410405093677",
"name": "Pirkka iceberg salad Finland 100g 1st class",
"price": 1.29,
"tags": "fresh vegetable pirkka"
},
{
"$p": 0.04017592239308106,
"category": "108",
"id": "6415600501811",
"name": "Coca-Cola 1,5l soft drink",
"price": 2.49,
"tags": "drink"
},
{
"$p": 0.03593903693070478,
"category": "103",
"id": "6412000030026",
"name": "Saarioinen Maksalaatikko liver casserole 400g",
"price": 1.99,
"tags": "meat food"
}
]
}In the JSON: we can find the page offset, the total number of hits, the actual documents, and the purchase probability in the $p-field.
While the query and the response may look simple, during the rather instant operation:
- Aito did create a recommendation model based on the query and the entire impression table,
- And Aito used the query and the model to filter and score all product table contents.
The Applications
Aito is currently in beta, but as a database it is quite stable and there are lots of applications, where Aito has good performance and throughput.
Aito has been used successfully in customer projects like:
- Populating a shopping basket from PDF
- Finding relevant people using their digital footprint in chats, events and projects
- Churn prediction and analytics
- Demand estimation
- Chat and workflow automation
- Invoice automation
Overall, Aito is currently best used
- for process optimization
- for internal tools and analytics
- for prototypes and proof-of-concepts
- and for MVPs and small productions settings
The Numbers
Aito has evaluation, stress test and performance test suites, which reveal some of Aito’s current capabilities.
While Aito’s value promise is not to provide the best estimates possible, Aito does very well in the classic supervised learning tasks. Here there are 2 benchmark test cases (DNA Splice and SMS spam dataset UCI repository), where Aito provides better results than the comparison:
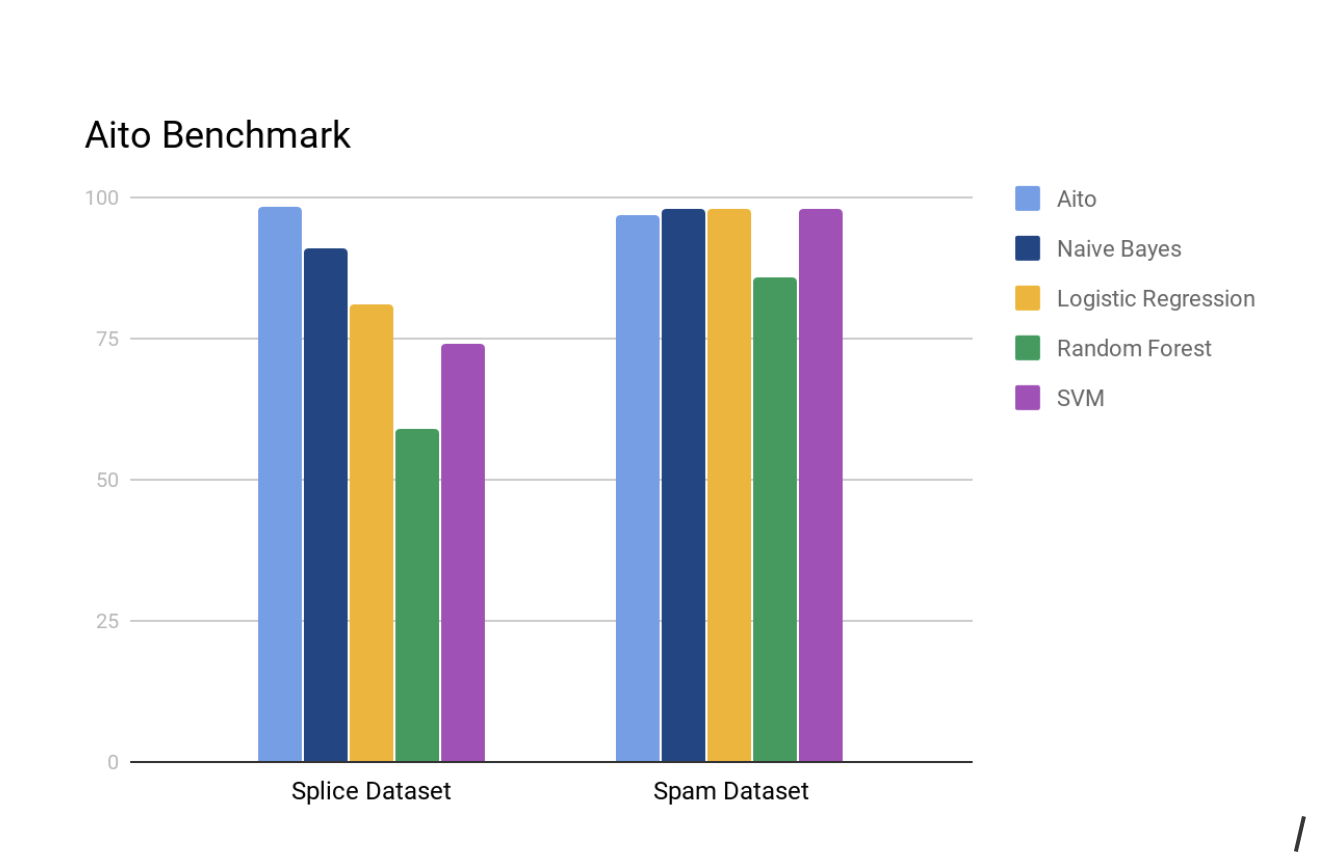
The average prediction took 8ms for spam and 12ms for the splice dataset.
Aito was also designed to be not just a classifier, but a proper Bayesian probability estimator. While the probability estimates can get biased from time to time, in many cases the estimates can be fairly accurate as visible here (for the spam dataset):
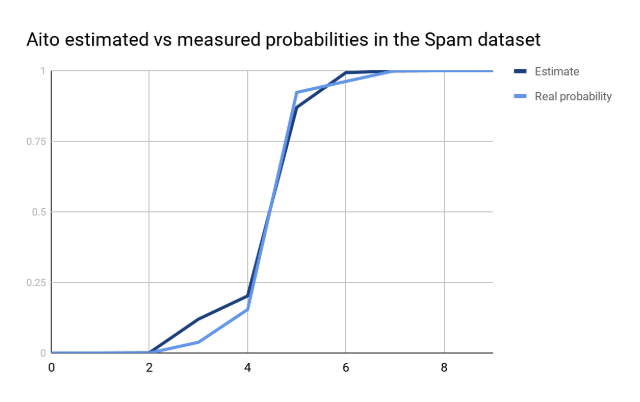
The tests and our own experiences show that Aito works typically fine to up to 1M rows and 1M features. If the Aito database is treated with _optimize operation, Aito may work well enough also with about 10M rows.
Following test case demonstrates Aito with the generated ecommerce data set. The table also shows the cost of adding 1000 impression in a batch mode.
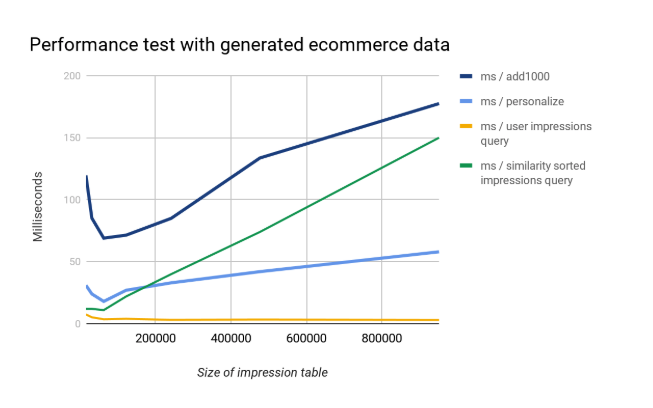
Although the results show that traditional databases (like Postgres, MySql, Mongo, etc) can beat Aito in the conventional database operations by wide margins, Aito still provides decent database performance for many applications as an addition to its AI services.
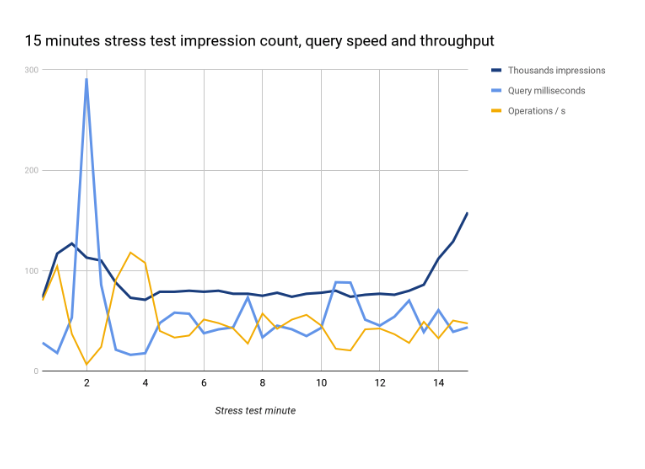
Aito’s Achilles heel right now is the responsiveness with bigger data sets, if the database faces continuous writes. If you have 1M features, after a write operation the next query operation may take over several seconds to complete. This often doesn’t matter in the internal use, and it can be managed by updating the database nightly, hourly or minutely.
At the same the write throughput and many other characteristics are ok. Following graph demonstrates the impression table size, the mean query speed and the query throughput. These results can be improved (Aito is still in beta), but they are already good enough for many applications like corporations’ internal tools used by hundreds or thousands of users:
The Future
We do believe that we are creating the future. While right now Aito is more of a replacement for more narrow ML / AI tools, in the future we’d want Aito to play the role of the main database. In this future that we seek to create: every database is smart and able to provide the software not just its memory, but also its intelligence.
We warmly invite you to share our vision of the future. The best way to get the taste of this future and help realize it is to try Aito. To do so, just request a free trial from this page, and please: tell both the community and us what you like about it, what are you experiences with it and also what you’d want us to improve.
Back to blog list