Getting started
Documentation

March 18, 2019
This guide provides practical and immediately actionable steps for getting started with Aito.
For quick upload instructions using the Aito CLI tool scroll to the bottom.
1. Introduction
Welcome to the kickstart guide with Aito.ai with all the necessary steps to get started! We start with looking at how Aito works when everything has already been set up, and then we see how to set everything up ourselves. To follow this guide, you may use your favorite REST client or paste the queries directly to your command line. Let’s go!
2. What Aito does
We’ll first show you how Aito looks like in action. We have already set up a public Aito instance for everyone to play with.
Let’s start off with a fun example where we’ll automatically detect sarcasm in Reddit discussions. Below is a snapshot of how the data looks like. The “label” column indicates whether or not the comment is sarcastic; it is the first thing we want to predict.
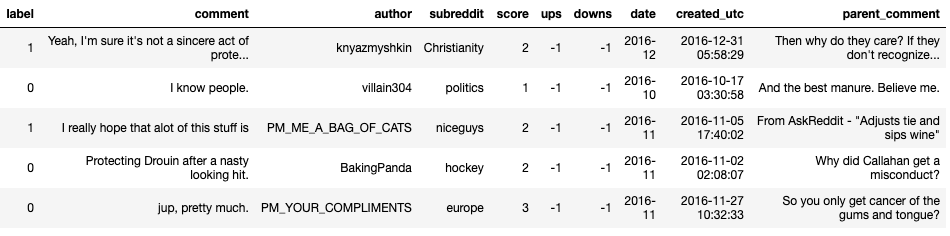
To predict if the sentence “dude you are so smart” is sarcastic on Reddit, simply copy the following query to your command line and hit enter:
curl --request POST \
--url https://aito-reddit-sarcasm.aitp.app/api/v1/_predict \
--header 'content-type: application/json' \
--header 'x-api-key: 9Ik1wJQ1tq86vMQG7taDB2cgfpSogUFu69lBGTnV' \
--data '{
"from": "comments",
"where": {
"comment": "dude you are so smart"
},
"predict": "label"
}
'
The response looks like this:
{
"offset" : 0,
"total" : 2,
"hits" : [ {
"$p" : 0.8432771866750243,
"field" : "label",
"feature" : 1
}, {
"$p" : 0.15672281332497587,
"field" : "label",
"feature" : 0
} ]
}
The response to this query contains the likelihood (“$p”) of each class (“feature”). This comment is indeed quite sarcastic. In fact, Aito thinks it is sarcastic with 84% probability.
Looking at the query you’ll notice that we only provided Aito with the comment and not the other data features. Let’s include “subreddit” in the query and see what happens:
curl --request POST \
--url https://aito-reddit-sarcasm.aitp.app/api/v1/_predict \
--header 'content-type: application/json' \
--header 'x-api-key: 9Ik1wJQ1tq86vMQG7taDB2cgfpSogUFu69lBGTnV' \
--data '{
"from": "comments",
"where": {
"comment": "dude you are so smart",
"subreddit": "politics"
},
"predict": "label"
}
'
And the response you get from Aito:
{
"offset" : 0,
"total" : 2,
"hits" : [ {
"$p" : 0.9031693595826128,
"field" : "label",
"feature" : 1
}, {
"$p" : 0.09683064041738716,
"field" : "label",
"feature" : 0
} ]
}
Being posted in the “Politics” Subreddit increases the chances that this comment is sarcastic to 90%. Meanwhile, if you try the same query but replace “politics” with “science”, the probability of sarcasm reduces dramatically to just 62%.
Go ahead and change the sentence to whatever you want and select a new subreddit. Here’s a few random subreddits for you to try:
- AskReddit
- nba
- science
- videos
- pcmasterrace
Well done! Now, after asking Aito if there’s sarcasm in the comment, let’s ask why it thinks so. Understanding the reasoning of a prediction is critical in any Machine Learning application! To receive more information than just the prediction, add a “select” line in the query which returns the predicted label (“feature”), its probability (“$p”) and most importantly, the reasoning (“$why”). Copy the following curl:
curl --request POST \
--url https://aito-reddit-sarcasm.aito.app/api/v1/_predict \
--header 'content-type: application/json' \
--header 'x-api-key: 9Ik1wJQ1tq86vMQG7taDB2cgfpSogUFu69lBGTnV' \
--data '{
"from": "comments",
"where": {
"comment": "dude you are so smart",
"subreddit": "science"
},
"select": ["feature","$p","$why"],
"predict": "label"
}
'
As requested, the query returns:
{
"offset" : 0,
"total" : 2,
"hits" : [ {
"feature" : 1,
"$p" : 0.6155384924100668,
"$why" : {
"type" : "product",
"factors" : [ {
"type" : "baseP",
"value" : 0.5
}, {
"type" : "normalizer",
"name" : "exclusiveness",
"value" : 0.9015948211626251
}, {
"type" : "relatedVariableLift",
"variable" : "subreddit:science",
"value" : 0.3999850073479482
}, {
"type" : "relatedVariableLift",
"variable" : "comment:smart",
"value" : 1.520886821001524
}, {
"type" : "relatedVariableLift",
"variable" : "comment:dude",
"value" : 1.257895343712437
} ]
}
}, { ... }
}
A lot of stuff is crammed in the response but bear with us. What’s important right now are the factors called “relatedVariableLift”. They tell us what Aito thinks during inference. Lifts represent multipliers which impact the final outcome, and according to Aito, the words “smart” and “dude” are especially likely to be sarcastic. For example, the word “smart” increases the sarcasm probability of the comment by 1.52x but being on the "science" subreddit decreases it by 0.39x.
Another very common type of inference is recommendation. With the below curl, Aito will predict the subreddit where a specific user is least likely to be sarcastic. Laid out, it says “recommend me a subreddit where the value of ‘label’ is likely 0 when the value of ‘author’ in the ‘comments’ table is ‘Creepeth’”.
curl --request POST \
--url https://aito-reddit-sarcasm.aito.app/api/v1/_recommend \
--header 'content-type: application/json' \
--header 'x-api-key: 9Ik1wJQ1tq86vMQG7taDB2cgfpSogUFu69lBGTnV' \
--data '{
"from": "comments",
"where": {
"author": "Creepeth"
},
"recommend": "subreddit",
"goal": {"label": 0}
}'
Turns out this user is least likely to be sarcastic on the "AskReddit" subreddit.
3. Setting up your own Aito
Now we take a few steps back and start from uploading your own data into a schema. Or in case you don’t right now have suitable data available, you may download and use the same CSV files we use in this demo. The demo files are found in this repositry: https://github.com/AitoDotAI/kickstart. "reddit_sample.csv" contains a sample of the full comments dataset and "users.csv" is a completely fabricated table to represent the Reddit users. To keep following the guide, you’ll need API keys which allow you to access your Aito instance. If you don’t have an API key yet, please contact us here.
Setting up your own schema has three distinct steps. First we look at the schema structure, then create an empty schema and tables, and finally upload the data into their correct tables. We highly recommend using a REST client for HTTP-API interaction.
Schema planning
Very often your data is stored in a collection of connected tables. In our Reddit example, the data is divided into two tables: Comments and Users. Aito will be able to find information across linked tables, and in our case the tables are linked together with “author” column. We could also link in a third table describing for example the subreddits, daily weather or something else. At this point, you need to go through your files and determine which tables and columns are linked.
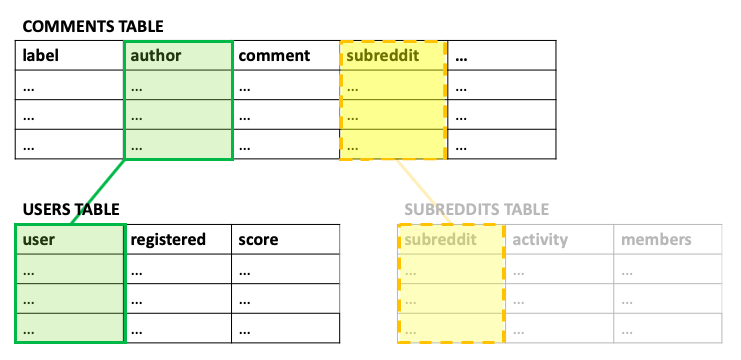
Now that we know the structure, we can start creating the database schema.
Creating your Aito schema
Now we define the tables, columns and their individual types and other specifications in the JSON format. This important step is a bit tedious but also necessary to ensure correct formatting of the data. In the next chapter we introduce our Command Line Interface (currently alpha version) for the automation of some parts of this process.
The structure of the JSON:
{
"schema": {
"table1": {
"columns": {
"column1": {"type": "Data type"},
"column2": {"type": "Data type", "analyzer": "english"},
...
},
"type": "table"
},
"table2": {
"columns": {
"column1": {"type": "Data type", "link": "table1.column2"},
"column2": {"type": "Data type"},
...
},
"type": "table"
},
...
}
}
Double check the JSON with care and add any necessary specifications such as links (connects two tables on one column) and text analyzers (treats the value as separate words instead of a single class). Make sure the linked columns have the same type. With our sample data, here’s how the full schema creation request looks like (replace the environment name and api key with yours):
curl --request PUT \
--url https://$AITO_INSTANCE_URL/api/v1/schema \
--header 'content-type: application/json' \
--header 'x-api-key: your-rw-api-key' \
--data '{
"schema": {
"users": {
"type": "table",
"columns": {
"registered": {
"type": "String",
"nullable": false
},
"score": {
"type": "Int",
"nullable": false
},
"user": {
"type": "String",
"nullable": false
}
}
},
"comments": {
"type": "table",
"columns": {
"subreddit": {
"type": "String",
"nullable": false
},
"author": {
"type": "String",
"nullable": false,
"link": "users.user"
},
"score": {
"type": "Int",
"nullable": false
},
"label": {
"type": "Int",
"nullable": false
},
"downs": {
"type": "Int",
"nullable": false
},
"date": {
"type": "String",
"nullable": false
},
"comment": {
"type": "Text",
"nullable": false,
"analyzer": "english"
},
"ups": {
"type": "Int",
"nullable": false
},
"parent_comment": {
"type": "Text",
"nullable": false,
"analyzer": "english"
},
"created_utc": {
"type": "String",
"nullable": false
}
}
}
}
}'
If there were no errors, the request sets up and returns the full schema structure. You can view your schema again with:
curl --request GET \
--url https://$AITO_INSTANCE_URL/api/v1/schema \
--header 'content-type: application/json' \
--header 'x-api-key: your-rw-api-key'
Uploading data into Aito
Aito expects data in a records-oriented JSON where each row is an individual item, such as:
[
{"user":"Trumpbart","registered":"2018-5-30","score":-111},
{"user":"Shbshb906","registered":"2018-7-10","score":124},
{"user":"Creepeth","registered":"2013-4-6","score":10},
…
]
To convert a CSV into the JSON format, you may use any script or converter you like, or try the Command Line Interface discussed in the next chapter. With your data in JSON, you may now upload it to each table. This batch upload request can support up to 50 000 rows at a time. If your file contains more rows, you may use a script to loop through the data. The following curl request uploads up to 50 000 rows to the “users” table:
curl --request POST \
--url https://$AITO_INSTANCE_URL/api/v1/data/users/batch \
--header 'content-type: application/json' \
--header 'x-api-key: your-rw-api-key' \
--data '
[
{"user":"Trumpbart","registered":"2018-5-30","score":-111},
{"user":"Shbshb906","registered":"2018-7-10","score":124},
{"user":"Creepeth","registered":"2013-4-6","score":10}
...
]'
Repeat the process for each table you wish to upload data into. To view the content of the “users” table, you may use:
curl --request POST \
--url https://$AITO_INSTANCE_URL/api/v1/_query \
--header 'content-type: application/json' \
--header 'x-api-key: your-rw-api-key' \
--data '{
"from": "users",
"limit": 10
}'
Your data is now ready for predictions!
Using Command Line Interface
The Aito Command Line Interface (CLI) is a tool to introduce automation into this process. It helps you by generating the table schema JSONs required for schema creation, converts CSV data to JSON, and uploads data into your Aito instance. Please do note it’s still an early alpha version. Currently you can't create a full schema with the tool by one command, you'll need to run the commands per data table.
Here’s how to get started:
-
Install Aito CLI (requires Python 3.6+) on command line:
pip install aitoai -
On your command line, cd to the folder which contains your data files.
-
Run the following command for each of your CSV data files:
aito convert csv -c schemafile.json --json < datafile.csv > datafile.json
The last command generates two JSON files from your CSV file. “schemafile.json” contains the table schema in JSON format which you can copy to your schema creation request. “datafile.json” contains all the data in the CSV converted into the JSON format for uploading data into Aito. Make sure to change the JSON file names for each CSV file you convert.
At this point, you need to combine the schemafiles into one JSON schema, such as in "Creating your Aito schema" chapter, and send it as a PUT request to create the schema. While combining them, make sure you check if each column has the right type and add the needed column links.
After creating the schema use the following command to upload each of your data files:
aito client -u https://$AITO_INSTANCE_URL -r your-ro-api-key -w your-rw-api-key upload-batch your-table-name < your-datafile.json
This might take a while but you’ll be able to follow the progress on the command line.
Upload data with Aito CLI using the Reddit data
Example data files can be downloaded from our kickstart repository.
-
Create the needed JSON files from the CSVs:
aito convert csv -c comments_schemafile.json --json < reddit_sample.csv > comments_datafile.json
aito convert csv -c users_schemafile.json --json < users.csv > users_datafile.json -
Create users and comments table schemas into Aito:
aito client -u https://$AITO_INSTANCE_URL -r your-ro-api-key -w your-rw-api-key create-table comments < comments_schemafile.json
aito client -u https://$AITO_INSTANCE_URL -r your-ro-api-key -w your-rw-api-key create-table users < users_schemafile.json -
Upload comment and user data into Aito:
aito client -u https://$AITO_INSTANCE_URL -r your-ro-api-key -w your-rw-api-key upload-batch comments < comments_datafile.json
aito client -u https://$AITO_INSTANCE_URL -r your-ro-api-key -w your-rw-api-key upload-batch users < users_datafile.json
Inference
Finally your data is ready for the fun part. Try again the prediction queries of the first chapter but this time in your own environment. There are many more types of inference than basic prediction which you may use to build your solutions. You'll find instructions to using all the api endpoints in our documentation: https://aito.ai/docs/api/#query-api
We highly encourage you to try them out and see which api endpoints fit your needs. An example gallery with all the different endpoints is coming up, stay tuned!
Back to developer docsAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429







